作者:陈煜 | 效能改进
一、背景
技术中心的年度研发效能报告已于前不久发布,在吞吐的分析中,我们新增了一个指标「标准差」(计算公式见图1)。
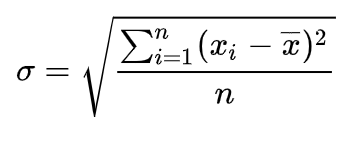
标准差在概率统计中最常使用作为统计分布程度上的测量。它反映组内个体间的离散程度。标准差越大,表示大部分数值和其平均值之间差异较大,反之亦然。
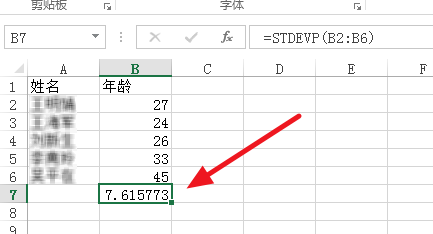
上面的公式不用记,Excel 中有对应的计算函数:STDEVP(见图2)。
二、指标的产生历程
常见的数据分析方法包括:趋势分析、指标下钻分析、关联影响分析。而标准差,就是下钻分析维度的产物。我们的目标是提升吞吐量(即:单位周期交付的需求数量),所以重点关注在「吐」的情况。
然而,利特尔法则指出,过高的在制品数量会影响需求的交付周期,进而影响需求交付效率。故在吞吐量的分析中,我们加上了在制品的分析,引入了对「吞」的观察(即:单位周期规划的需求数)。
但是,我们仅仅以自然月为单位周期进行分析,发现规划需求数和交付需求数只是两组无规律的波动。仅用周期内发生的需求个数和时间趋势,难以评价吞吐量是否正常,我们只能看到一张随月度起伏变化的曲线图(见图3)。
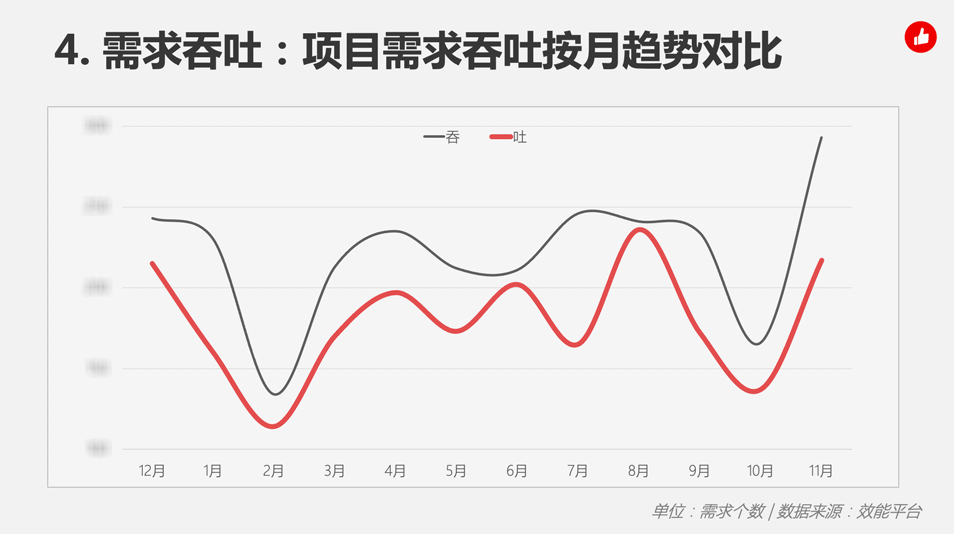
我们希望有个指标或数据统计方式,可以直观反映出吞吐的「问题」,一方面可以做部门间的横向对比,另一方面也能提醒我们介入干预。标准差就是这样一个指标,它适用于分析一组数据,擅长只用一个数值,就可以表达波动幅度的情况,这对任何一支团队都是适用的。
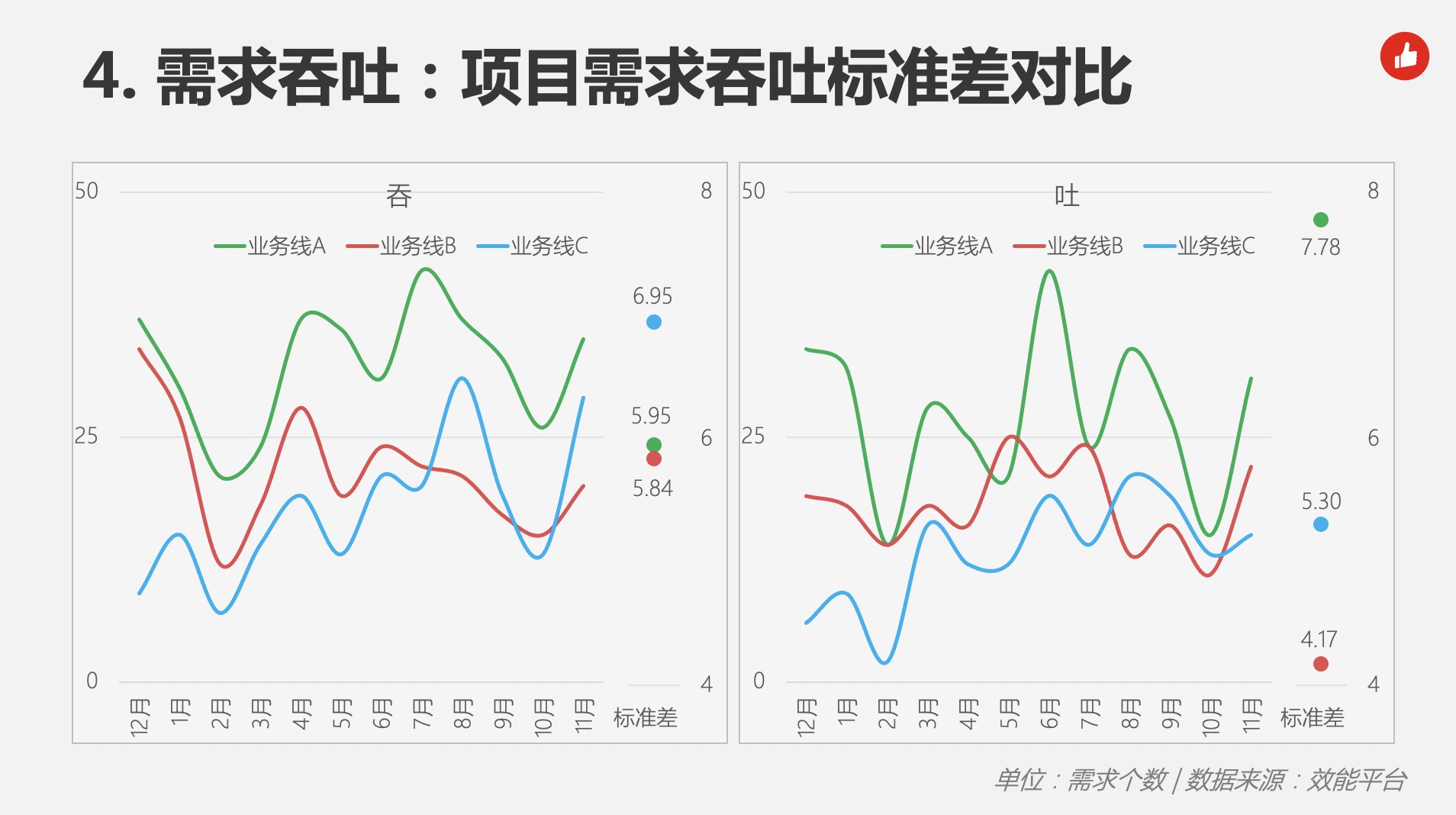
吞吐标准差,统计了两个维度的数据:规划需求波动、交付需求波动。标准差表示,每月新规划或上线需求数,与平均值的离散程度。标准差越大,每月规划个数或上线个数越不稳定,对团队生产秩序的冲击越大(见图4)。
三、指标的运用场景
在图4的案例(数据来自年度研发效能报告,挑选了最典型的三条业务线)中,我们有几个发现:
单纯横向比较这三条业务线的吞或吐,都没有意义,在团队规模、需求场景、业务架构等维度上都没有可比性。
吞(左图):业务线C(蓝点)的波动性最大,意味着该业务的产品方案输入最不稳定(这真是个意外的收获,用研发效能的度量指标也能观测产品端的生产节奏),对研发团队的影响最大,可能出现过需求大小月:在小月里可能发生过团队空转或承接了持续数月的巨型需求,在大月里则需要投入额外的管理成本和资源来维持生产。
吐(右图):业务线B(红点)的波动性最小,意味着该业务的研发团队产出最稳定。真实的情况是,该业务线的研发团队已通过敏捷转型实现了时间盒内交付的稳定节奏,与此同时,其吞的标准差(左图红点)也是最低的(这是不是意味着,敏捷研发模式可以降低生产波动呢?敏捷真是个好东西!)。
吐(右图):业务线A(绿点)的研发产出最不稳定,需要进一步介入分析(一般来说,原因会比较多元,本文不做展开),并采取改进措施。
四、小结
吞吐的标准差可以用于衡量研发团队的稳定性以及成熟度(敏捷转型相关),但因为软件研发不同于工厂制造,无论吞还是吐,每一条需求都会受到功能颗粒度和研发复杂度的影响,故无须追求消除偏差的极致目标。
标准差可用于事前。吐的标准差在一定程度上可以用于指导规划活动(吞)的开展,对于同一个团队来说,交付能力(吐)通常是稳定的,规划过多则会造成在制品积压反而影响交付,适得其反。
标准差也可用于事后。当吐的标准差过大,但总体需求交付数却不理想时,就需要结合过往需求研发并行程度、需求研发周期等数据,做进一步下钻分析。
传统的吞吐量指标,意在观察团队是否挖掘了产能极限。但笔者认为,团队的产能水平通常是恒定的,唯一影响其发挥的因素是「吞」,可通过吞的标准差来评价。而「吐」一方面折射出「吞」的效果,另一方面则是为了满足需求提出方的体感诉求。
吞吐的标准差指标可挖掘和探索的领域还有很多,如果读者朋友有更多的相关实践,欢迎在留言区沟通。
延伸阅读
- 一则物理看板的演进实践
- 「研发共建」提升中台效能初探
- 效能指标「研发浓度」在项目度量中的应用
- 有赞效能数据赋能实战
- 项目制实践如何助力组织进化
- 有赞如何打造高绩效的千人技术团队?
- 敏捷与 OKR:系统思考与组织设计的艺术
- 大规模产品待办列表处理策略—需求分级
- 大规模产品技术团队需求管理实践
如果读者对效能改进也有兴趣,欢迎加入有赞效能改进团队,请将简历投递至:chenyu_yu@youzan.com,我们共同探讨和实践。
