一、有赞搜索平台整体设计
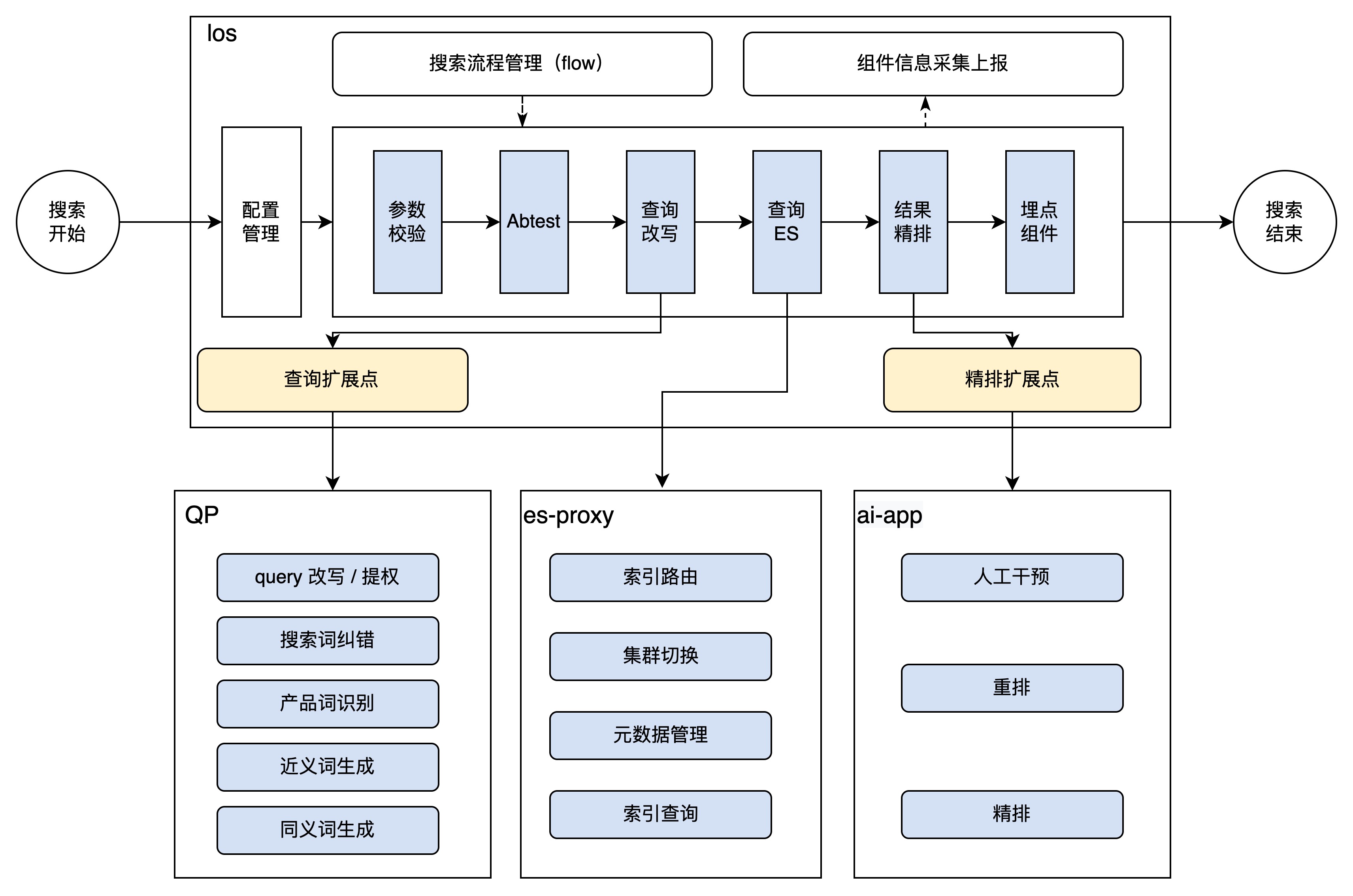
在介绍QP前先简单介绍一下搜索平台的整体结构,方便大家快速了解QP在搜索平台中的作用。下图简单展示了一个搜索请求开始到结束的全部流程。业务通过简洁的api接入los,管理员在搜索平台新建配置并下发,完成整个搜索接入,并通过abtest验证QP带来的优化效果。
二、QP的作用
在NLP中,QP被称作Query理解(QueryParser),简单来说就是从词法、句法、语义三个层面对query进行结构化解析。这里query从广义上来说涉及的任务比较多,最常见的就是搜索系统中输入的查询词,也可以是FAQ问答或阅读理解中的问句,又或者可以是人机对话中用户的聊天输入。
在有赞,QP系统专注对查询内容进行结构化解析,整合了有赞NLP能力,提供统一对外接口,与业务逻辑解耦。通过配置化快速满足业务接入需求,同时将算法能力插件化,并支持人工干预插件执行结果。
以精选搜索为例,当用户输入衣服时用户往往想要搜的是衣服类商品,而不是衣服架,衣服配饰等衣服周边用品。通过将衣服类目进行加权,将衣服类的商品排在靠前的位置,优化用户搜索体验。
 QP目前应用在新零售,微商城、精选、爱逛买手店、分销市场、帮助中心知识库、官网搜索等场景,通过类目加权,产品词识别,搜索词纠错,同近义词召回提升用户搜索效果。
QP目前应用在新零售,微商城、精选、爱逛买手店、分销市场、帮助中心知识库、官网搜索等场景,通过类目加权,产品词识别,搜索词纠错,同近义词召回提升用户搜索效果。
三、QP应用整体设计
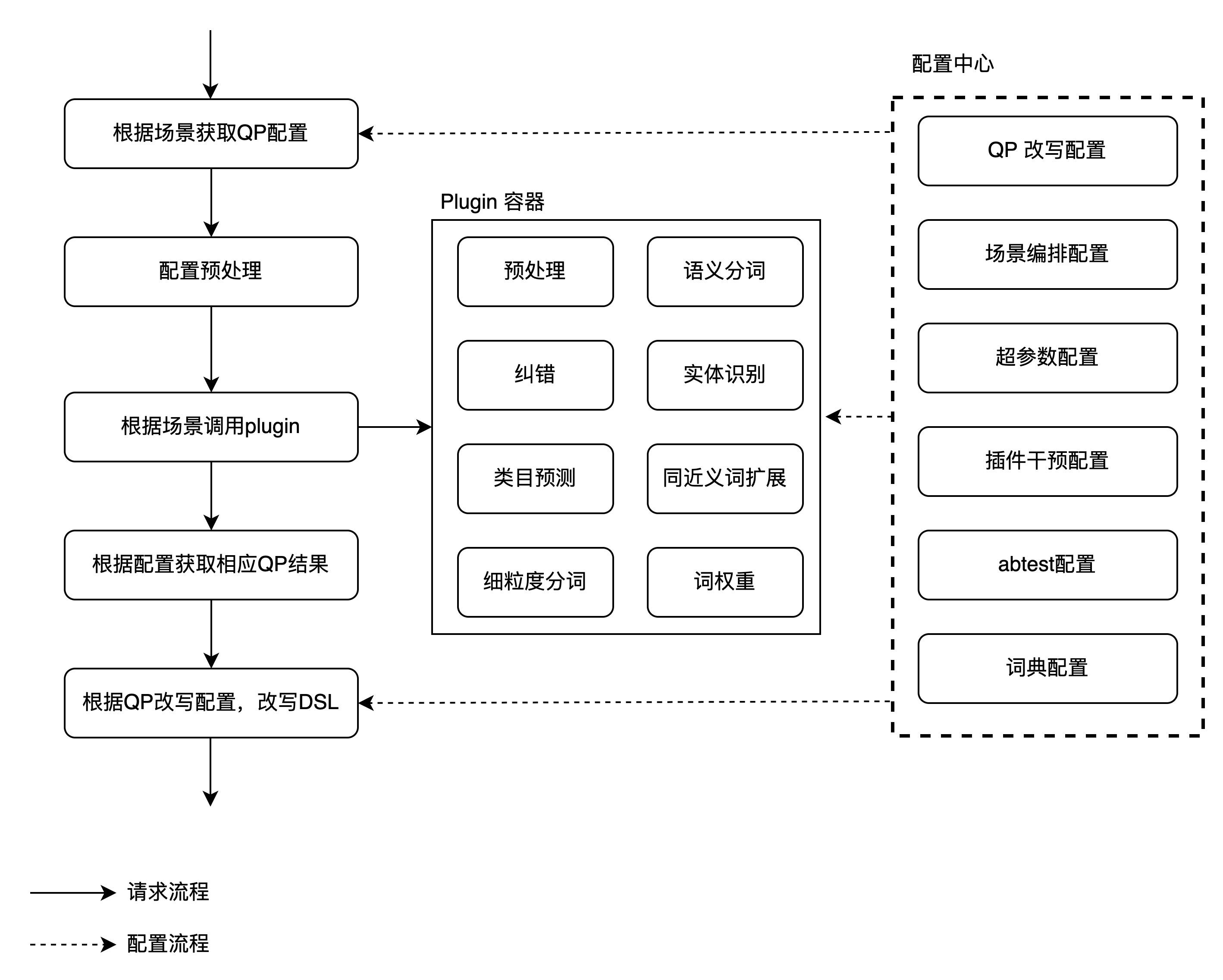 上图完整描述了QP请求流程和配置流程的执行情况。当搜索请求到达QP时,根据请求体中的场景标记获取QP配置。QP配置中包含搜索词位置标记,插件列表,dsl改写脚本等内容。
上图完整描述了QP请求流程和配置流程的执行情况。当搜索请求到达QP时,根据请求体中的场景标记获取QP配置。QP配置中包含搜索词位置标记,插件列表,dsl改写脚本等内容。
QP根据配置,按序执行相应插件。插件在执行后,可通过干预配置以及超参数对结果进行人工干预。
QP在获取到算法插件执行结果后,根据改写配置,对搜索dsl进行改写。如将纠错词放置在搜索词同一层级,将dsl改写成fuction score结构进行类目加权。
四、QP应用分层设计
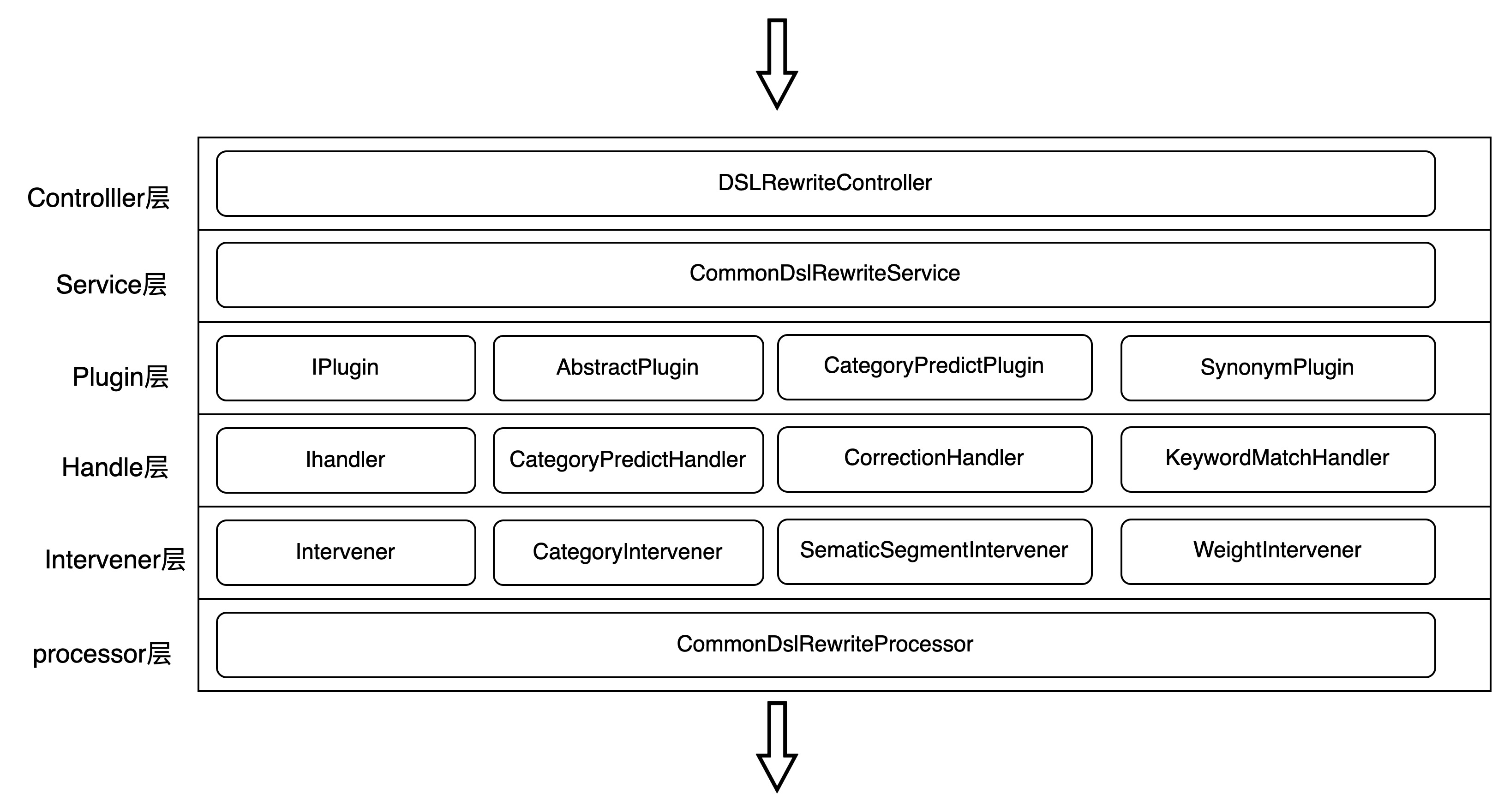 上图按照请求流程从上到下展示了QP的分层设计,接下来将简单描述各层作用:
上图按照请求流程从上到下展示了QP的分层设计,接下来将简单描述各层作用:
controller层:查询改写服务入口,对请求做预处理。
service层:根据场景获取QP改写配置,获取dsl里的搜索词,调用相应的插件返回qp结果。
plugin层:负责算法插件执行,调用插件对应的算法实现handler,对算法结果做干预并针对调用成功或者失败做处理。
handler层:算法具体实现放置在该层,该层会依赖各种算法服务(如小盒子,Milvus等)。
Intervener层:负责对handler结果做人工干预。
processor层:根据QP改写配置,调用改写插件,完成dsl的改写。
五、QP算法插件设计
5.1 预处理Preprocess插件
按照配置规则对搜索词进行预处理,预处理方式如下:
* 删除特殊符号 " “ \ 等;
* 大写转小写,全角转半角;
* 连续英文联合切分,连续数字联合切分,其余单独切分;
* 默认截取list前50个字/词;
* 将list拼接成一个字符串。
样例
输入:"史蒂夫新款\时尚套装夏修身圆领百搭钩花DWF镂空雪纺两件套套裙;"
输出:"史蒂夫新款时尚套装夏修身圆领百搭钩花dwf镂空雪纺两件套套裙"
5.2 纠错Correction插件
纠错插件的作用是对搜索词中错误内容进行识别,返回正确内容。
样例
输入:[上海牛黄皂]
输出:[上海硫磺皂]
当用户输入“上海牛黄皂”时,通过纠错插件能正确输出“上海硫磺皂”,其技术架构如下图所示。
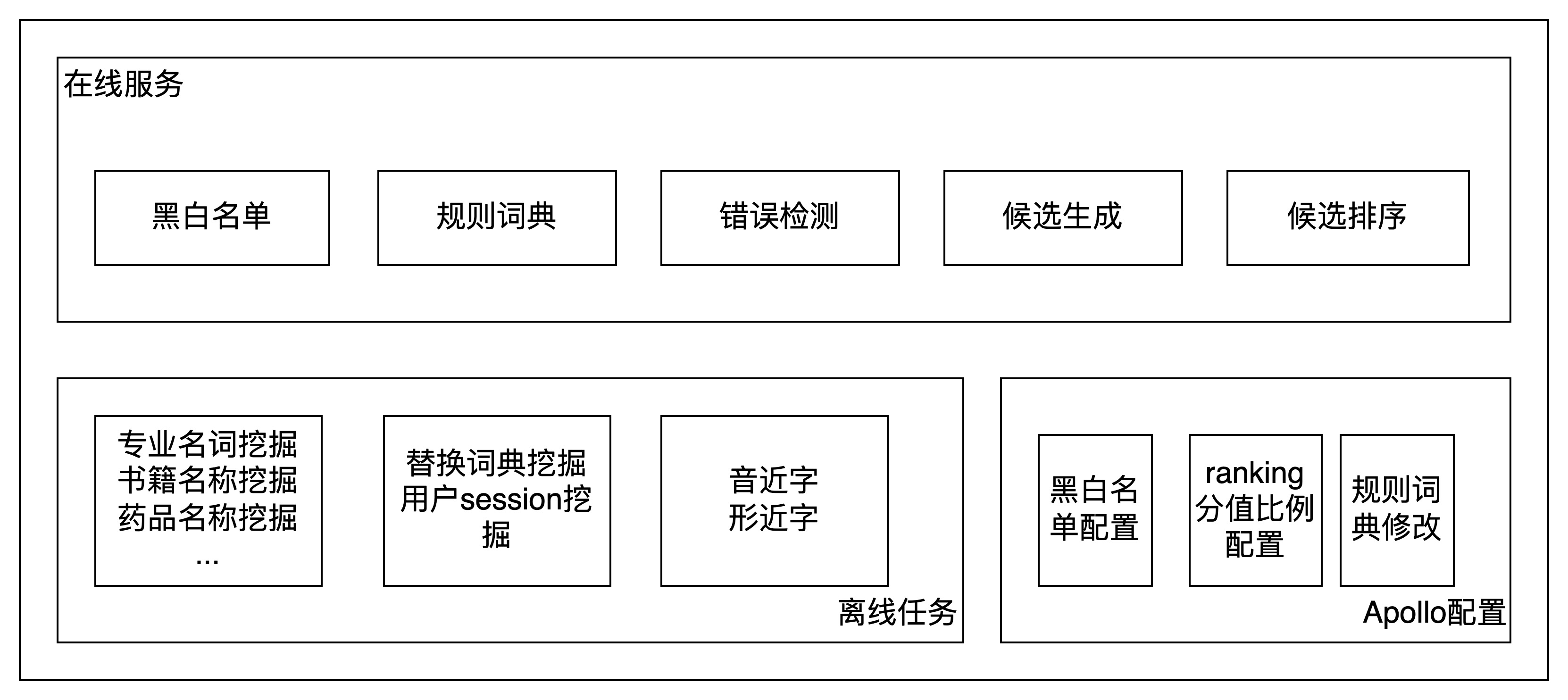 1、纠错模型在bert基础上采用知识蒸馏,提升模型精度降低模型时延。
1、纠错模型在bert基础上采用知识蒸馏,提升模型精度降低模型时延。
2、根据同音字召回候选集,使用tri-gram语言模型对候选集排序。
5.3 细粒度分词Tokenizer插件(基础分词)
样例
输入:[雪地靴女2020年新款皮毛一体冬季加绒加厚防滑东北厚底保暖棉鞋子]
输出:[雪地 靴 女 2020 年 新款 皮毛 一体 冬季 加绒 加厚 防滑 东北 厚底 保暖 棉 鞋子]
该分词插件由Java版结巴 jieba-analysis 修改而来,修改内容如下:
* 从全网商品标题数据,有赞行业数据,开源数据中统计出词频,作为基础分词词典;
* 解决词典中由英文单词导致英文字符串被分开的问题;
* 限制DAG的长度,即匹配词的长度,以此控制分词粒度,目前默认是2,分出来的词除英文和数字外,长度不会超过2。
5.4 语义分词sementicSegment插件
样例
输入:[雪地 靴 女 2020 年 新款 皮毛 一体 冬季 加绒 加厚 防滑 东北 厚底 保暖 棉 鞋子]
输出:[雪地靴 女 2020年 新款 皮毛一体 冬季 加绒加厚 防滑 东北 厚底 保暖 棉鞋子]
该插件在细粒度分词的基础上,通过模型生成语义树将关联度大的词列表进行合并,输出语义分词结果。在样例中,雪地与靴关联度更大,所以在语义分词中将雪地与靴合并输出。
5.5 实体识别Tagging插件
样例
输入:["汽车","脚垫","刷子"]
输出:[{"word":"汽车","tag":"产品修饰词"},{"word":"脚垫","tag":"产品修饰词"},{"word":"刷子","tag":"产品词"}]
实体识别插件主要用于识别出搜索内容中的产品词。比如用户在输入“汽车脚垫刷子”时,如果没有做产品词识别,“脚垫”相关的商品会因为商品分高而排在“刷子”商品前面,影响用户搜索体验。
反之,经过命名实体识别,对“刷子”做产品词提权,刷子类商品就可以排在脚垫类商品前面,优化搜索体验。
目前有赞规划的实体类别列表如下所示:
产品词 eg:“修身连衣裙”中的“连衣裙”
产品修饰词 eg:“汽车脚垫”中的“汽车”
普通词
新词
修饰
品牌
机构实体
地点地域
材质
人名
功能功效
专有名词
影视名称
型号
文娱书文曲
系列
游戏名称
款式元素
颜色
场景
风格
营销服务
人群
时间季节
性别
类目
母婴
规格
新品
前缀
后缀
数字
符号
实体识别方法
基于正则可以识别数字、符号、规格、时间季节。
// 数字
private numWordRegex = "[0-9]+";
// 符号
private String symbolWordRegex = "[\\[\\]\\{\\}【】「」\\\\\\|、|‘'\"“”’;:;:>.。》/?\\?<《,,~`·!\\!@#\\$¥%\\^…&\\*(\\(\\))\\-_—=\\+\\s]+";
// 规格
private String unitRegex = "(?:\\d+|\\d+\\.\\d+|[一二三四五六七八九十百千万]+)\\s*(?:m|米|cm|厘米|ml|毫升|l|升|度|平米|件|块|元|片|张|本|条|瓶|部|辆|个|桶|包|盒|g|克|kg|千克|吨|寸|斤)";
// 时间季节
private String seasonRegex = "[春夏秋冬]+[季天]?";
private String yearRegex = "(?:18|19|20)\\d{2}";
基于词库可以识别产品词、品牌、产品修饰词。
品牌:query->二级类目->品牌,条件:在当前类目品牌词库里且模型预测不是“产品词”,此时打“品牌”实体标。
产品词:在产品词库且模型预测是普通词。
产品修饰词:多个词出现时,除最后一个,其余打“产品修饰词”实体标。
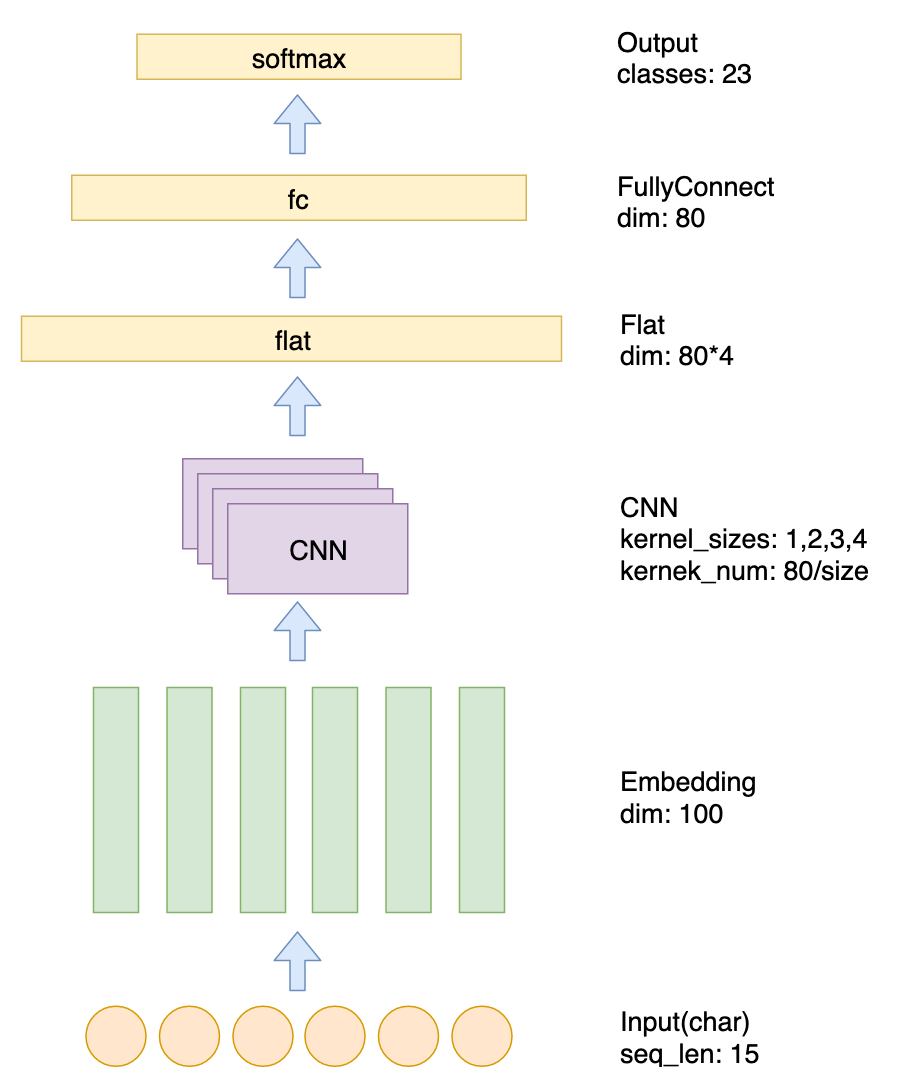
基于模型可以识别剩余23类实体,类别如下所示:
产品词
普通词
新词
修饰
品牌
机构实体
地点地域
材质
人名
功能功效
专有名词
影视名称
型号
文娱书文曲
系列
游戏名称
款式元素
颜色
场景
风格
营销服务
人群
时间季节
模型结构:
5.6 类目预测categoryPredict插件
样例
输入:牛奶绒
输出: {
"categoryId": "101000010001",
"categoryName": "被套",
"categoryChainList": [
"家居建材",
"床上用品",
"被套"
],
"parentCategoryId": "10100001",
"level": 3,
"hasChildren": true,
"percent": 0.9010684490203857
}
该插件会根据用户的搜索内容输出类目结果,主要应用在类目加权上。
例如当用户在有赞精选上输入牛奶绒,期望返回牛奶绒床单。
未使用类目加权,返回的商品大多为牛奶相关产品,不符合用户的搜索期望。
使用类目加权后,将床上用品类产品提权,返回的商品牛奶绒床单,符合用户期望。
类目预测模型是在对比学习基础上实现,具体内容可看对比学习在有赞的应用
5.7 同近义词插件
样例
输入:[衬衣]
输出:[衬衫]
同近义词插件目前非常实现轻量,通过离线同义词表,搜索内容中的产品词作为输入,输出同义词。
六、总结与展望
本文从QP整体设计,分层设计,插件设计较为完整的介绍了QP的架构设计。目前经过一年多的迭代,QP已经实现业务场景小时级接入,优化了零售,微商城,精选,爱逛,分销等场景搜索效果。后续将会继续丰富算法插件能力同时完成QP可视化配置能力方便业务自主接入。
本文由吴鑫强,任艳萍负责收集整理。
