
1.背景
1.1 介绍
订单优惠计算是指买家选择商品加入购物车,交易系统根据会员等级,会员资产(优惠券/码、积分、权益卡),商家优惠活动,计算出订单实际需要支付的金额。
在有赞零售业务板块中,线上线下都有订单优惠计算场景。线上使用场景是买家在H5/小程序端选品加车、下单结算,中台在这部分已经有很充分的沉淀,所以主要使用中台提供的能力实现。而在线下使用场景深度契合垂直行业,业务场景比较特殊,不适合放在中台去实现,所以这部分能力由零售业务自己完成。
1.2 业务场景
在线下开单收银场景,零售提供了多种客户端供商家选择,买家使用的端:门店小程序、自助收银大屏版。商家收银的端:PC 收银(浏览器/桌面),Phone/Pad 收银端等。
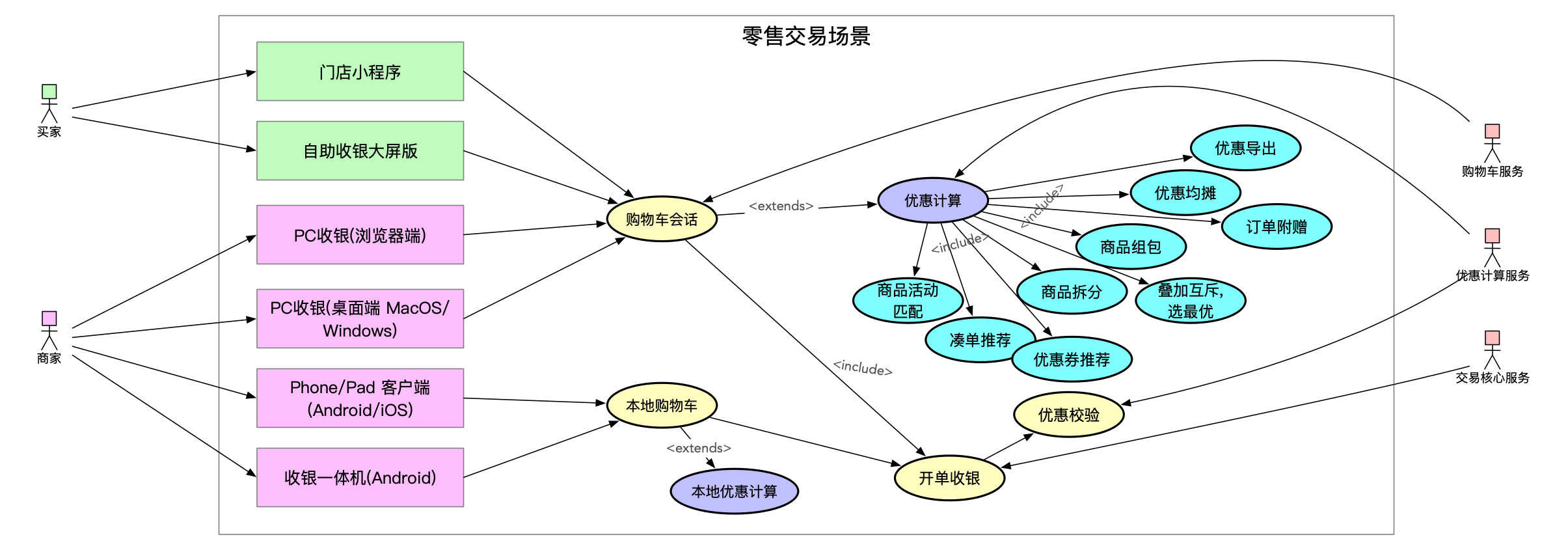
总结下零售线下场景优惠计算的难点和痛点:
- 属于交易核心逻辑,涉及到资产,如果计算出问题,容易对商家或买家造成资损
- 营销活动较多,迭代速度快,业务逻辑复杂 耳熟能详的有:限时折扣、优惠券、满减送、买一送一、打包一口价、积分抵现等。为了促进消费,营销玩法会不断地更新,同时原有的活动也一直在往细致化发展,贴合商家使用需求
- 开发量冗余 业务场景对应的客户端多,使用的技术栈也是不同的。部分端实现了本地计算,部分端暂时依赖后端优惠计算
- 各端实现细节可能不一致,维护起来费时费力
- 如果发生计算错误,很难及时修复问题
1.3 前世
零售移动端团队在每次营销项目迭代中,Android、iOS两端小组都需要投入开发资源,影响团队整体的项目迭代效率。
于是,移动端团队基于 JavaScript 开发了第一版跨平台订单优惠计算,它统一了 Android/iOS 订单本地优惠计算和优惠详情展示的逻辑,还有动态热更的能力。
在后续迭代中,后端也希望能够接入这套能力,并共建这套系统,但是发现了有一些问题急需解决。
- 计算过程中依赖了共享全局变量,有并发问题,无法同时计算多笔订单,对后端使用场景来说,虽然可以通过多个执行引擎实例来实现并发安全的计算,但此方案实属下策
- 没有领域模型,营销活动模型各不相同,实现的计算逻辑差异较大,导致代码重用度不高
- 没有设计活动互斥,互斥逻辑是硬编码在活动处理类中的
- 订单的数据结构冗余,商品和活动模型应该是独立的,但实际上商品模型下挂载了可以使用的活动,这样即增加理解成本,又增加了数据序列化的开销
- 没有类型约束,开发起来,代码提示全凭记忆,对于初次接触该系统的人,代码理解成本较高,开发新功能也束手束脚
- 处理逻辑繁琐,在商品特别多的情况下,性能不太理想
2.新生
2.0 设计目标
新的方案需要满足以下几种需求:
- 能够提供给现有场景的多个端使用,已有的活动都需要支持。
- 统一的模型设计。商品和活动要有对应的模型,一个活动一个模型是不能接受的,这样代码复用率太低。
- 扩展性强
- 对后续的需求迭代,能够很轻松的扩展原有功能或新增营销活动
- 多个端的使用差异需要满足
- 性能优化。就算在商品特别多的场景,也不能出现耗时长的问题。
其实,最重要的还是提升研发效率,相同的营销计算逻辑不需要在多端都开发一遍。
2.1 重构还是重写?
方案 1: 重构活动模型成本巨大,改动贯穿所有文件,加上动态语言一时爽。
方案 2: 从长远看,用TypeScript 重写对后期开发效率提升会很大,同时也会大大降低代码理解成本。 ✅
简单介绍下TypeScript特点:
- 提供了静态类型,编译时静态类型检查可以避免不少低级错误
- 对代码重构和补全提示友好
- 多人协作起来,降低了沟通成本
- 可以编译成
JavaScript运行在各端
2.2 静态类型玩得更好
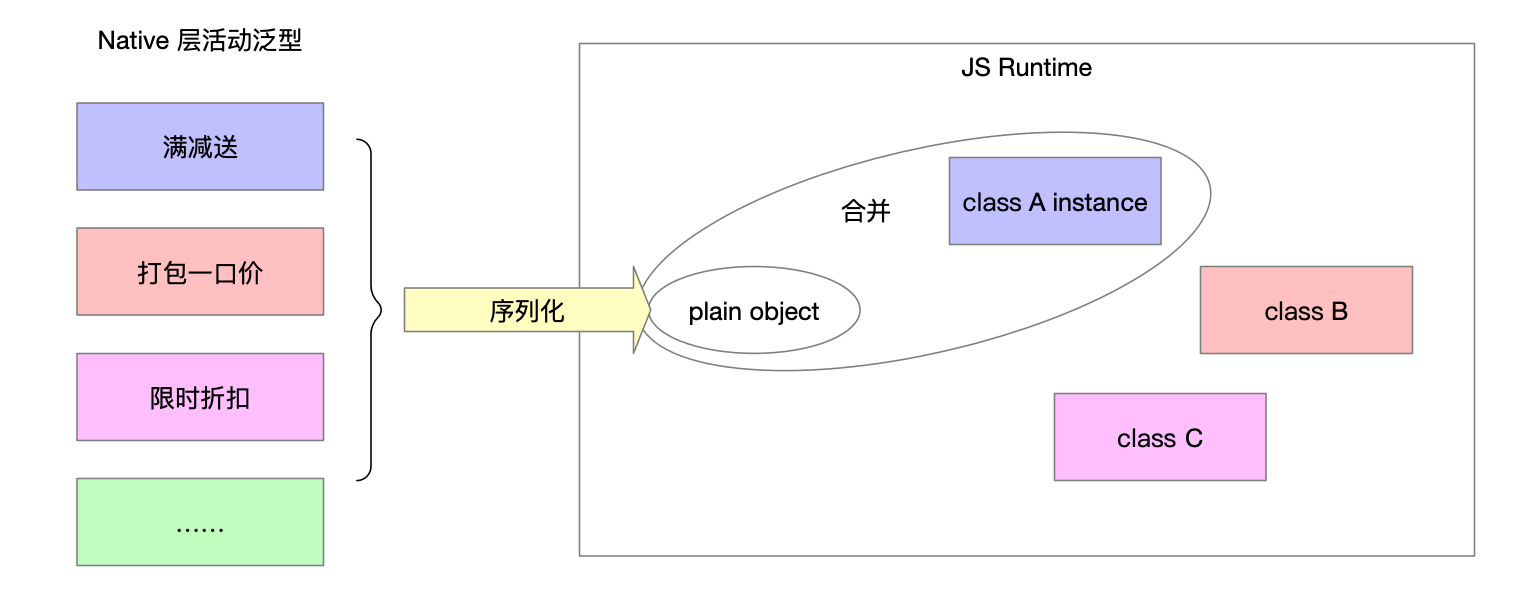
在Native这边的泛型,经过序列化之后,在JS Runtime反序列化得到的是普通对象,没有了自身行为和类型约束。
当然这不是语言层面的问题,但我们仍然可以设计得更完善。
我们可以通过合并对象的方式,让对象实例既有数据,又有行为和类型检查。
2.3 业务模型分析
2.3.1 营销活动模型
“满 300 减 30、2 件 8折,3 件 7折、全场 100 元任选 3 件……”
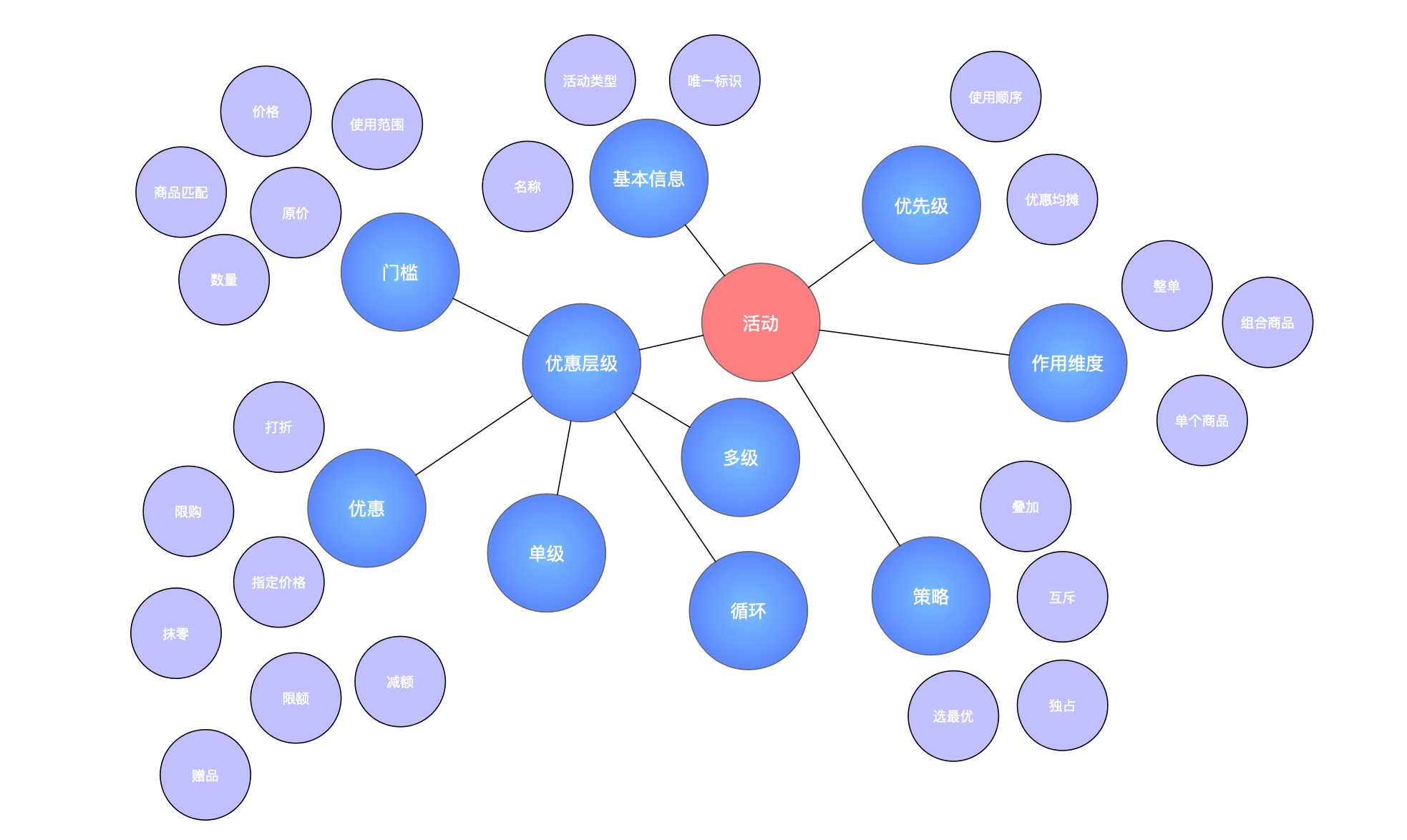
其实营销活动本身最核心的三个部分是:
- 门槛 如需要满足多少金额或商品数量,是否原价使用等
- 优惠 如直接打多少折,减多少钱,或者 3 件 100 元这种指定金额的玩法
- 基本信息 包含了活动唯一标识、活动类型、活动名称
仔细想想,对这个门槛和优惠扩展一下,然后组合起来,就是一个新的营销活动玩法。
除此之外,营销活动优惠计算处理逻辑还有:
- 计算优先级 多个活动计算优惠时,需要有优先级定义,然后按照顺序计算使用
- 使用策略 多个活动都可以使用时,要考虑它们之间的关联关系,互斥,可叠加,选最优
- 作用维度 单个、多个商品使用,或者整单立减
2.3.2 扩展性
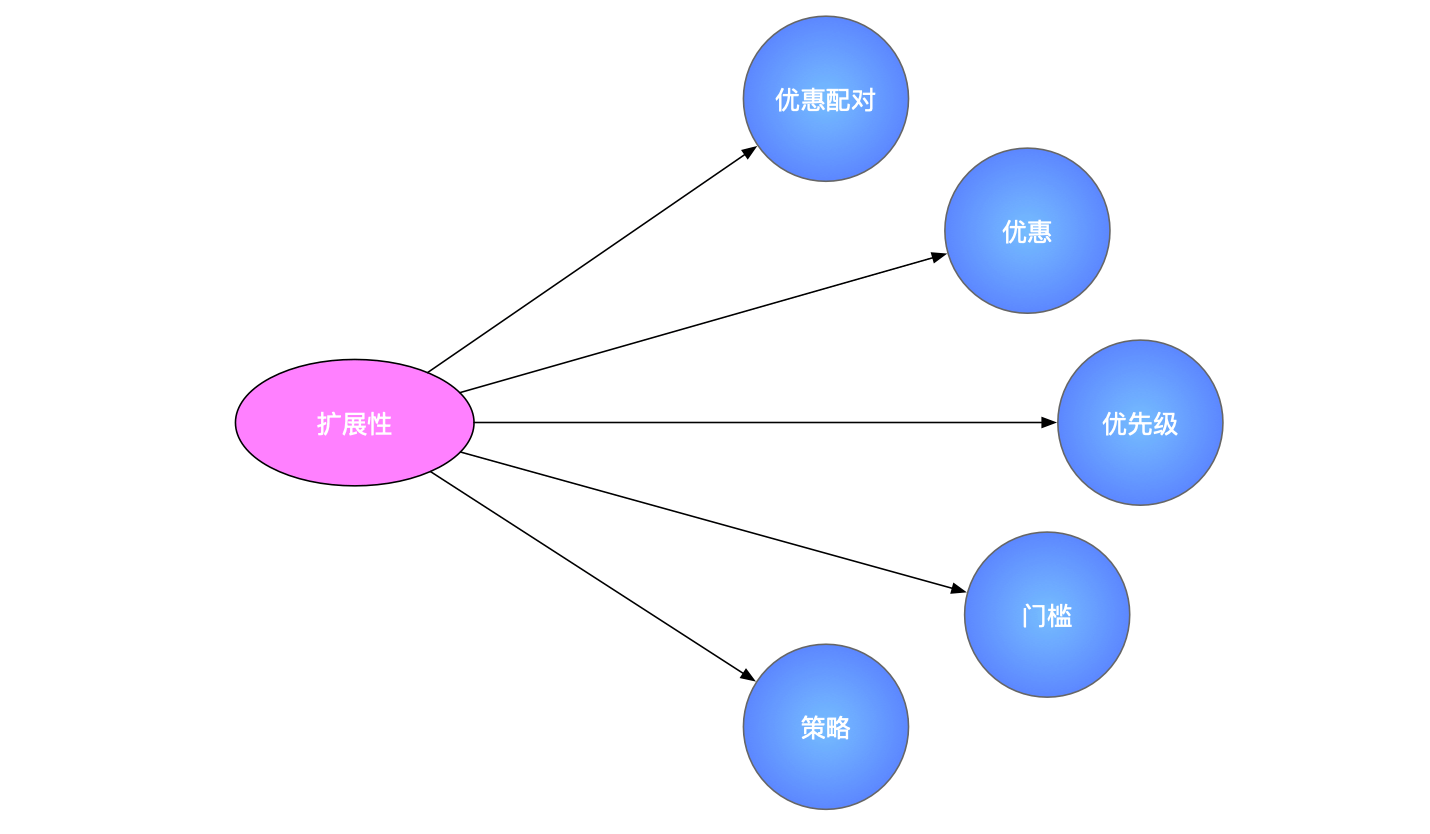
通过对营销活动的模型分析,可以预见的是,未来营销活动需求迭代,会出现以下几种场景:
- 商家可以任意配置门槛和优惠来创建活动,万能的营销插件
- 商家可以任意配置优惠活动的使用顺序和使用策略
- 增加优惠方式,如现有抹零分为抹分、抹角、四舍五入到角,商家想要新增四舍、五入等
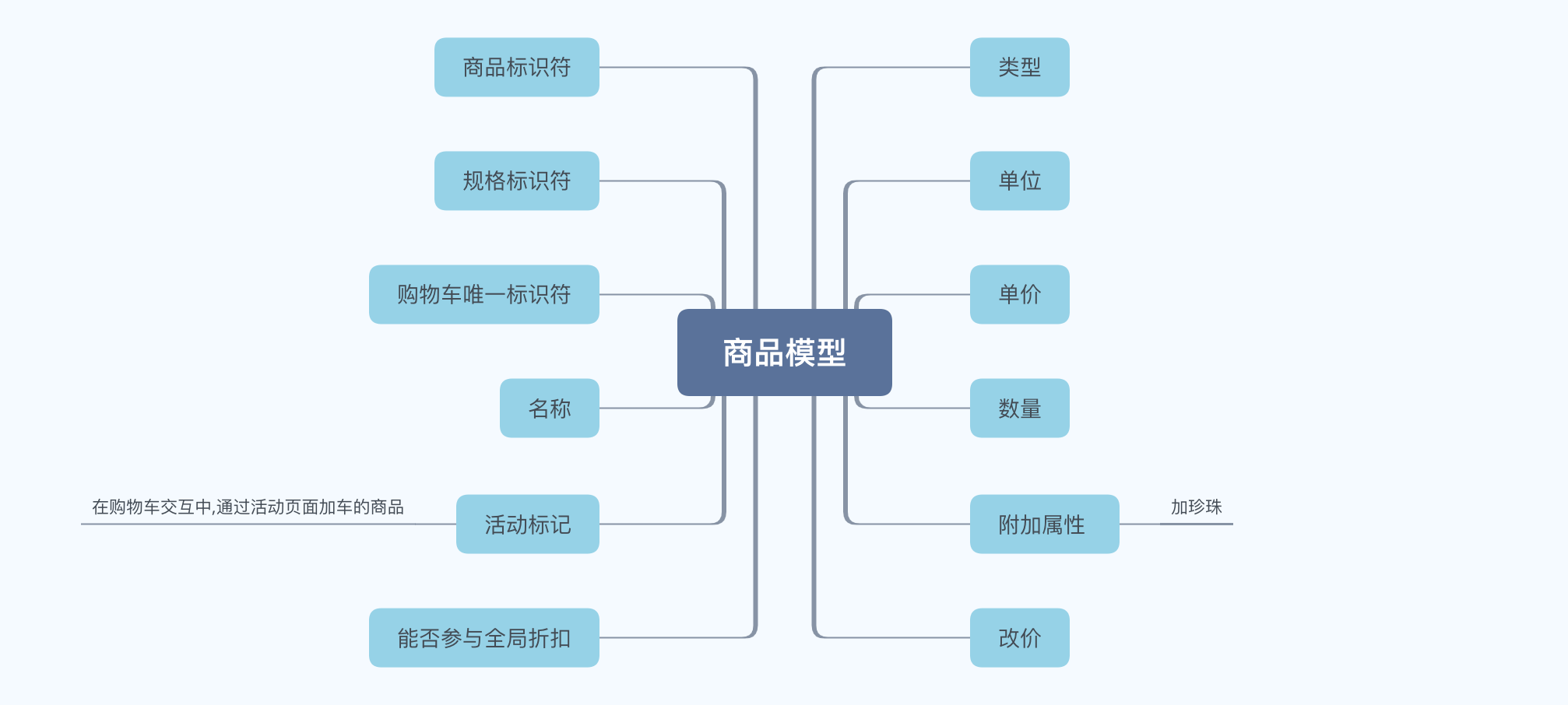
2.3.3 商品模型
商品本质是一个纯数据的模型,包含一些基本属性:标识符、类型、单位、数量、单价等,但是在实际开发过程中,需要为其增加自身能力。
2.3.4 活动优先级问题
将营销活动的计算逻辑抽象成处理器,串联起来使用,这样的方式可以解决活动优先级问题,也比较适合我们的业务场景,可以很好地实现以下目标:
- 规范了活动处理流程
- 活动处理顺序可配置化
- 活动处理之间可以任意插入逻辑节点
在实际开发中,可以插入 2 个 「数据调整」 的处理器。
- 多个 SKU 级别优惠算完后,比较优惠额度,选择最优的方案
- 所有活动处理完后,整理订单概要数据

2.3.5 活动互斥模型
活动之间有一定的使用策略:叠加、互斥、选最优。
目前的使用策略主要是由产品设计决定的,部分活动互斥情况如下所示:
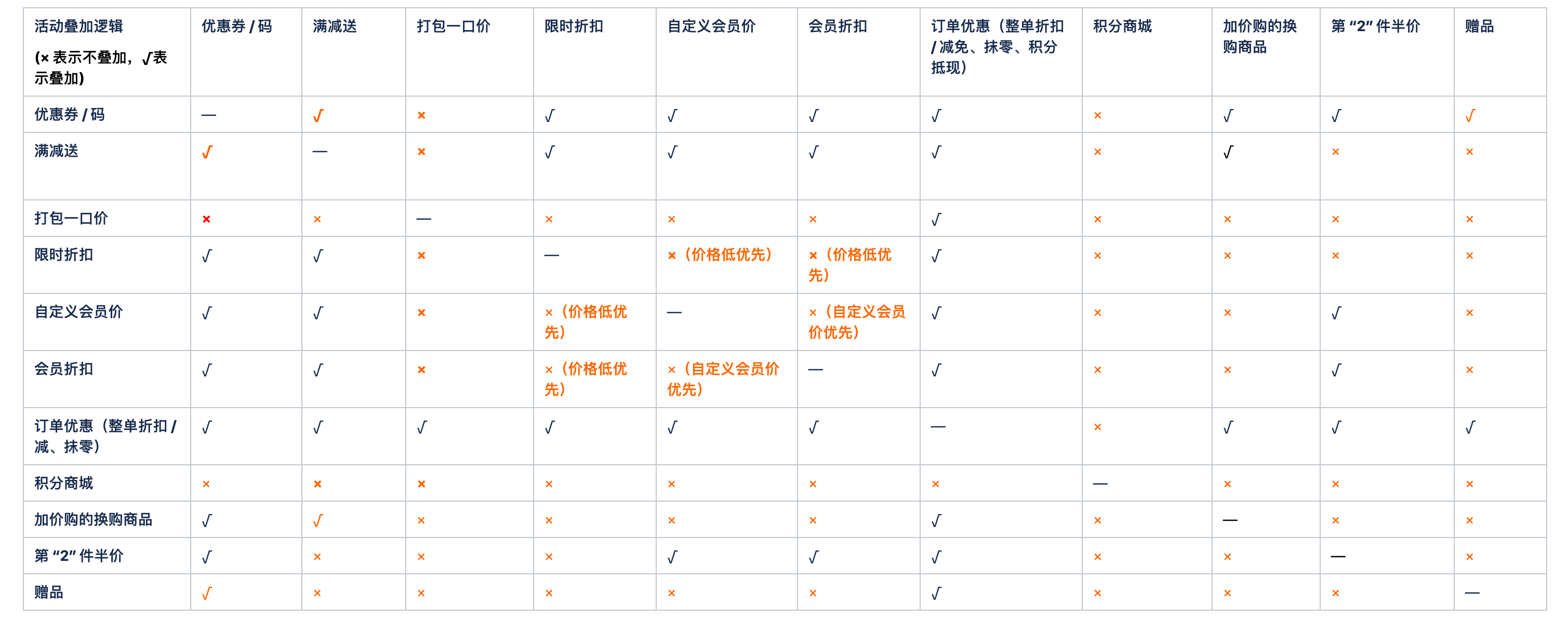
对于活动之间的互斥关系,需要一个合适的数据结构来存储,然后封装起来,简化外部对其的使用。最终选择使用无向图来存储,在实际开发中,使用邻接链表的方式实现。
无侵入的活动互斥
为了避免活动互斥的逻辑硬编码在活动处理类中,在执行营销活动计算的处理方法时,排除掉了已经参与互斥活动的商品,这样活动处理器不用感知活动互斥,只需要关心自己的处理逻辑。
大致代码如下:
// 活动互斥容器
class PromotionMutex {
test(a: PromotionType, b: PromotionType): boolean;
}
const promotionMutex = new PromotionMutex();
// 活动优惠计算处理
abstract class Processor<T> {
process({ skuWrappers }) {
// 获取处理器关心的活动类型
const type = this.getType()
// 迭代SKU列表, 筛选出可用的商品(没有参与互斥活动)
const availableSkuList = skuWrappers.filter(
sku =>
!sku.allAvailablePlan.some(plan =>
promotionMutex.test(plan.type, type)
)
);
// 交给处理器
this._process({ availableSkuList });
}
}
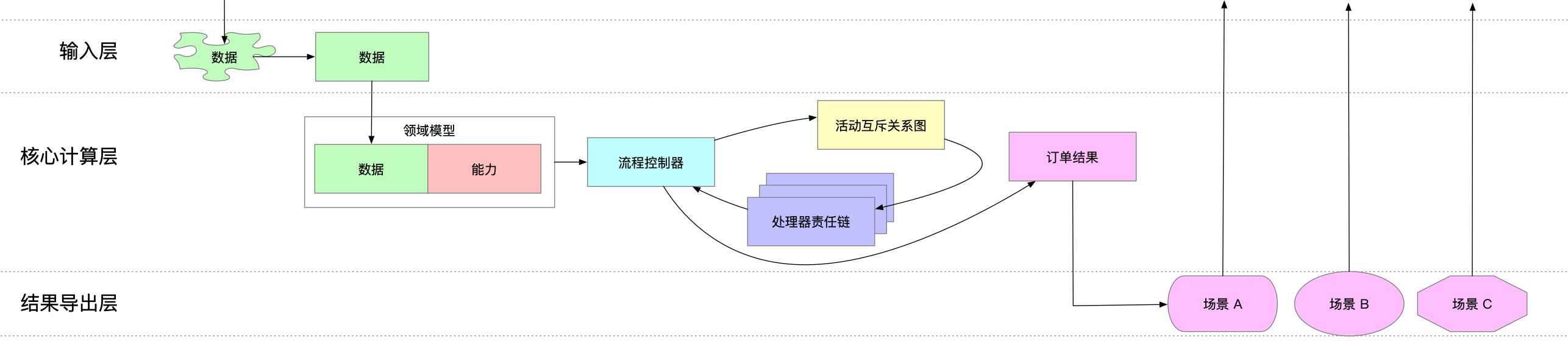
2.4 整体设计
2.4.1 分层设计
输入层
主要把外部传入的数据做整理转换。 这部分是可选的,可以在Native层就做好适配,不同的端可以通过扩展 Entry来实现自己的处理。
核心计算层
- 构建领域模型,实际是为输入层的数据增加了自身能力的处理逻辑。如商品应有的能力:使用改价价格、计算总价、拆分一部分数量出来、应用优惠等
- 将合适的商品和活动交给处理器,计算出优惠结果
结果导出层
Native端不再需要做多余的模型转换,减少了很多工作量。JS 这边针对不同场景,数据直出。 JS 做起来简单且合适(拥有所有数据)
例如:移动端需要的不仅仅是订单优惠详情,还有移动端两端之间约定的渲染模板(什么地方用啥颜色,字体大小等)
通过扩展输入层和结果导出层,共享核心计算层的方式,满足不同端的业务场景需求。
2.4.2 核心类图
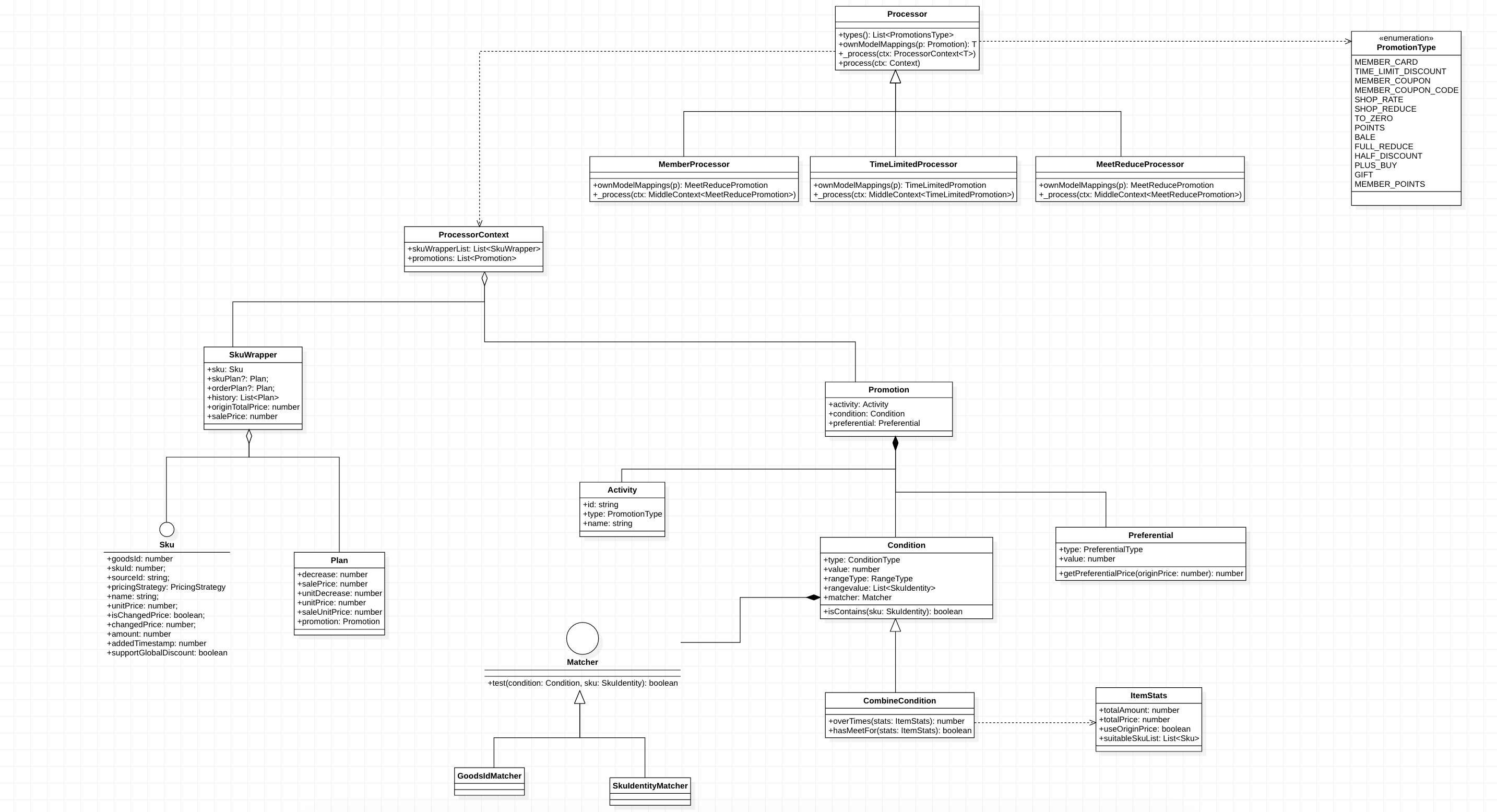
2.5 细节设计
2.5.0 写在前面
总结下几个设计原则
- 领域模型应该拥有自身的能力,而不是交给
XXXManager处理 - 内聚的模型,代码复用率很高
- 增加中间层,解耦活动模型变化和计算逻辑,提升扩展性
- 多用组合。
compose(A,B) => Foo, compose(A, C) => Bar - 避免使用扩展字段(字典),看起来大而全,实则并不能节省开发量,还浪费了类型检查,能明确的字段就直接定义出来
- 通过包装原有数据对象的方式,为其添加能力,始终不会修改源数据。
2.5.1 内聚的模型
将核心逻辑放在对应的模型上,模型聚焦自身能力,隐藏实现细节,简化外部的使用。
这里举几个栗子:
- 商品模型:除开商品自身的数据,应提供
- 计算商品总价的能力、隐藏改价、商品单位、附加属性的计算逻辑
- 应用SKU级别优惠的能力、隐藏使用优惠之后,价格变动的处理
- 门槛模型:
- SKU 级别门槛提供:商品能否使用优惠、隐藏全选、部分选中、反选和无码商品的逻辑
- 组合级别门槛提供:生成商品统计概要之后,是否满足了要求,凑单还需什么或者已经超过门槛了多少倍
- 优惠模型: 提供 计算应该优惠多少金额的能力, 隐藏打折,减钱, 指定价格, 抹零这些优惠方式
// SKU的包装类
class SkuWrapper {
// 应用SKU级别的优惠方案
applySkuPlan(skuPlan: SkuPlan);
// 计算SKU的总价
reCalcTotalPrice();
}
// 对一组商品参与活动的统计
interface ItemStats {
// 数量
totalCount: number;
// 价格
totalPrice: number;
// 使用原价?
useOriginPrice: boolean;
// 可以参与商品的列表
suitableSkuList: SkuWrapper[];
// 源数据
sourceSkuLit: SkuWrapper[];
}
// 活动门槛
class Condition {
// 包含 SKU
isContains(sku:Sku);
}
// 组合级活动的门槛
class CombineCondition extends Condition {
// 是否满足门槛
hasMeet(itemStats: ItemStats);
// 超过门槛多少倍
overTimes(itemStats:ItemStats);
// 还缺多少满足门槛
calcRemainValue(itemStats: ItemStats);
}
// 活动优惠
class Preferential {
// 计算优惠价格
calcPreferentialPrice(originPrice: number);
}
通过这些核心模型的设计,处理一个 SKU 级别活动将变得非常简单,核心代码不会超过20行, 大致如下:
_process({ skuList, promotions }) {
// 迭代活动
promotions.forEach(p => {
// 取出活动门槛和优惠
const {
conditionPreferentialPairs: [{ condition, preferential }]
} = p;
// 迭代SKU列表
skuList.forEach(sku => {
// 如果门槛包含SKU
if (condition.isContains(sku)) {
// 计算优惠后的价格
const preferentialPrice = preferential.calcPreferentialPrice(
sku.salePrice
);
// 生成优惠方案
const plan = {
preferentialPrice
// other properties
};
// 应用SKU级别优惠方案
sku.applySkuPlan(plan);
}
});
});
}
2.5.2 处理器抽象模板类
对于不同的活动,需要实现活动处理模板类中的抽象方法:
- 关心的活动类型
- 处理活动数据(基础信息 + 门槛 + 优惠)到活动泛型的映射
- 处理自身活动泛型和商品,生成和应用优惠方案
abstract class Processor<T> {
abstract types(): PromotionType[];
abstract ownModelMappings(promotion: Promotion): T;
abstract _process(ctx: ProcessorContext<T>): void;
}
活动模型的扩展性:各个活动总是有差异的,不需要全部按照一个固定的模型去设计。把通用的部分定义出来,允许出现特性,同时不会对外部传入的数据做限制。
这里主要通过增加中间层来实现活动模型的扩展性。ownModelMappings()会将数据封装为自身所需的泛型,即使外部活动的门槛或优惠有变化,之前的计算逻辑也不用修改。
例如有这么一个场景:有门槛和优惠关系是 1:1的活动 Foo,定义如下:
// 门槛和优惠比例 1:1
{
condition: {type, value},
preferential: {type, value}
}
// 优惠计算处理
class FooProcessor extends Processor<Foo> {
// 将数据转换为活动对应的泛型
ownModelMappings(p: Promotion): Foo {
return new Foo(p);
}
_process({foo}){
// do sth
}
}
// 门槛模型
class Condition {
constructor(c) {
// 合并数据和行为
Object.assign(this, c);
}
isContains(sku:Sku);
}
class Foo {
constructor(p: Promotion) {
this.condition = new Condition(p.cs.condition)
}
}
需求变更为:多个门槛满足一个即可享受优惠。那么,其实只需要扩展原有condition的封装方式,实际对原来的计算逻辑没有任何影响。
// 门槛和优惠变更为 n:1
{
conditions: [{type, value}, ...],
preferential: {type, value}
}
// 一个门槛满足即可
const anyCondition = conditions => ({
isContains: s => conditions.some(c => new Condition(c).isContains(s))
});
class Foo {
constructor(p: Promotion) {
// 活动门槛的匹配方式修改为 anyCondition 即可
this.condition = anyCondition(p.cs.conditions)
}
}
2.5.3 商品活动匹配
一个商品能不能使用活动的优惠,主要有以下几种匹配方式:
- SPU 级别(商品 ID)
- SKU 级别(商品 ID + SkuID)
- 原价才能使用
- 原价SPU 级别(商品 ID)
- 原价SKU 级别(商品 ID + SkuID)
- 非称重商品才能使用
- 全部能用
- 等
通过以上的几种情况可以看出,如果纯粹按照需求来开发这块功能,会有很大的冗余。为了减少重复开发量,使用组合的方式来实现
// 定义匹配函数
type Matcher = (condition: Condition, sku: Sku) => boolean;
// 原价才能使用
const originPriceMatcher = (condition: Condition, sku: Sku) => true
// SKU维度标识匹配
const skuIdentityMatcher = (condition: Condition, { goodsId, skuId }: Sku) => false
// 组合匹配
const composeMatcher = (a: Matcher, b: Matcher): Matcher => (
condition: Condition,
sku: Sku
) => a(condition, sku) && b(condition, sku);
// SKU维度标识匹配且使用原价
const originPriceWithSkuIdentityMatcher = composeMatcher(originPriceMatcher, skuIdentityMatcher)
2.5.4 性能优化
对于系统的性能优化,做了几点微小的事:
- 简化输入输出数据结构,减少边界开销
- 尽量避免深度复制,尤其是结构层次深的对象
- 选择合适的算法,通过剪枝的方式,缩小计算量。在商品特别多的情况下,时间复杂度依然能保持常数阶
以下是iOS客户端生产环境采集新老计算耗时的数据统计。为了避免影响观感,去除了极端场景下老版本计算超时的记录
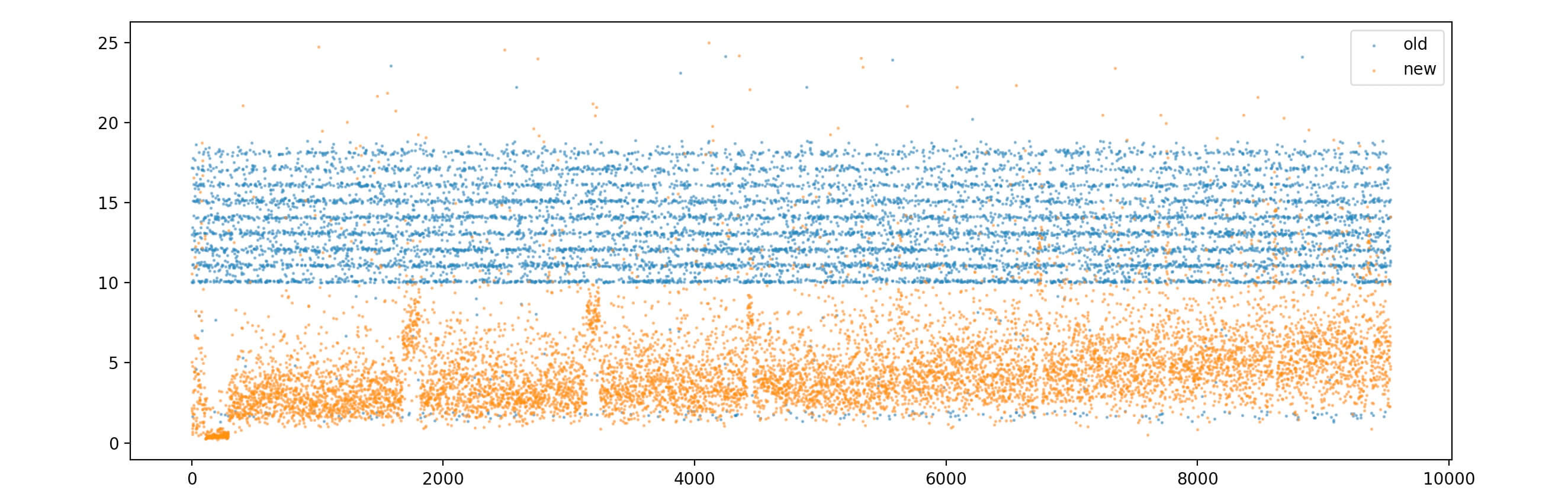
2.5.5 测试覆盖
开发一个项目,测试代码是必须要有的,更何况是涉及到资产,一定要稳。
除了在开发功能阶段编写的单元测试,测试同学还提供了一系列核心用例,加上线上真实订单计算场景的数据,都补充到了集成测试当中。
项目的测试率覆盖如下图:
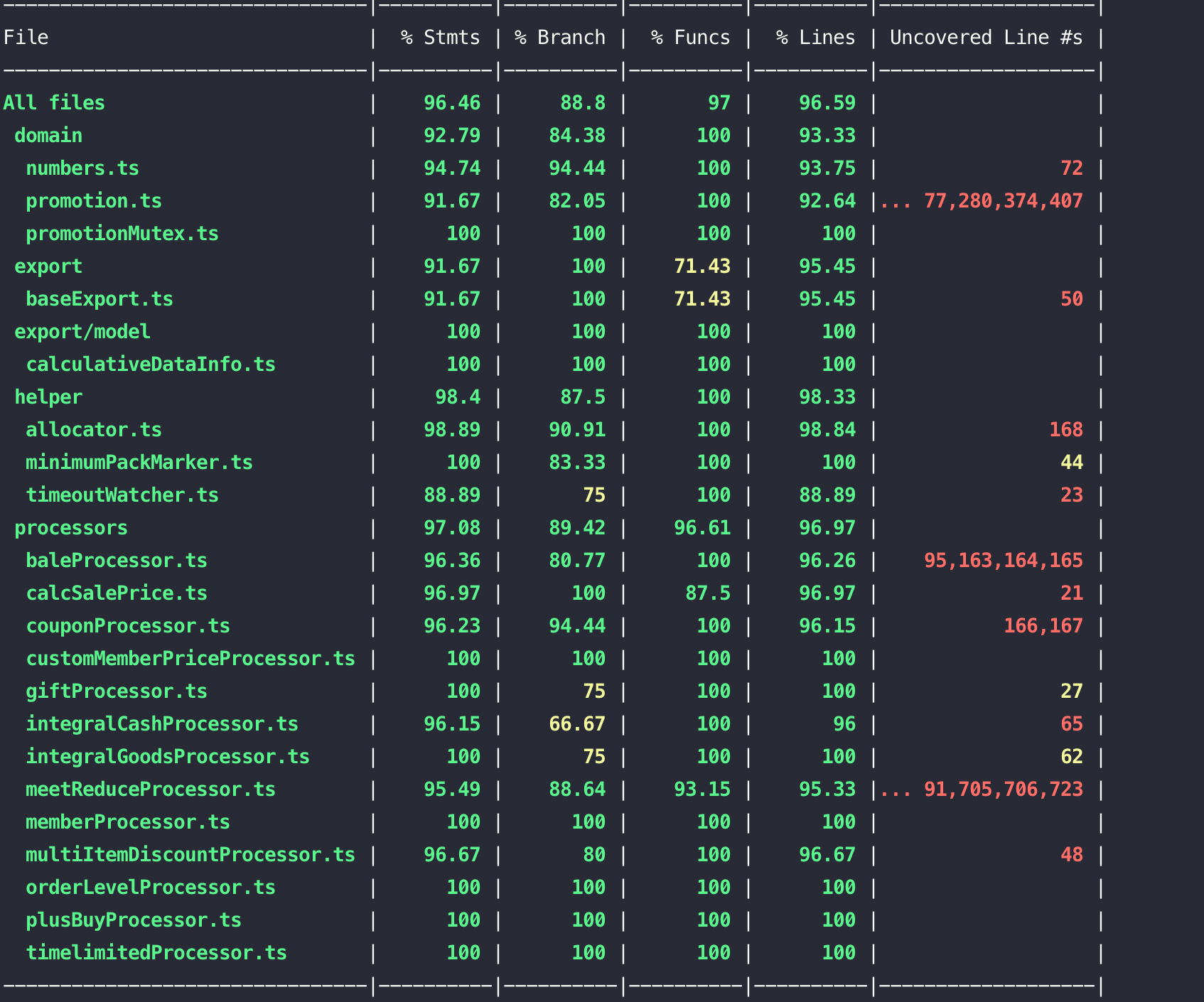
3.后端计算场景
3.1 JavaScript 运行环境选型
J2V8 Google V8 高性能 JavaScript 引擎的 Java 封装
Nashorn JDK 内置轻量级高性能 JavaScript 运行环境 ✅

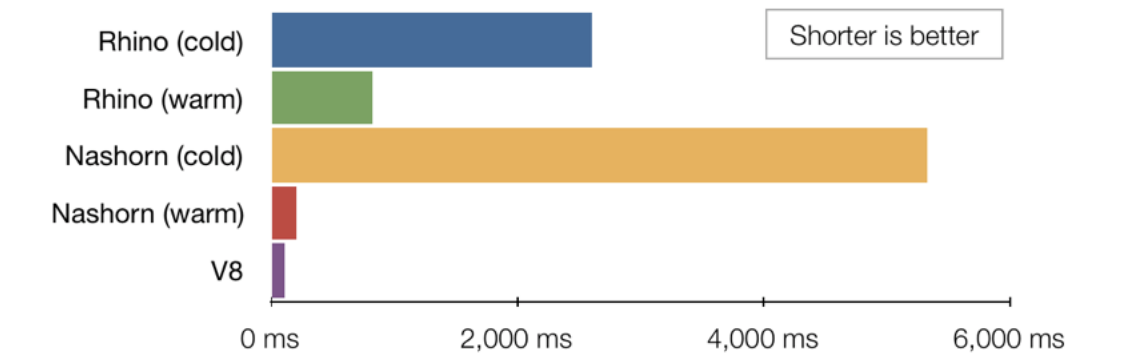
基于不折腾和性能不差的原则,选择了JVM内置的Nashorn引擎作为后端 JavaScript 运行环境.
3.2 热更新
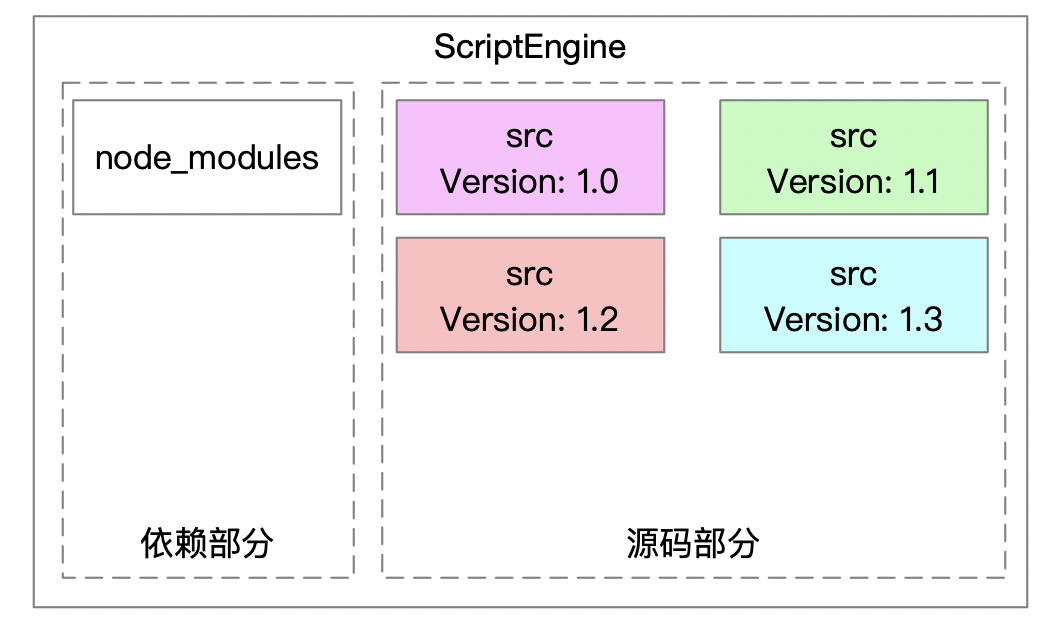
后端服务感知到有新版本的 JS 发布,需要创建新的ScriptEngine,并加载 JS 文件,然后通过静态的订单数据预热,预热结束后替换掉老的版本,对外提供服务.
值得注意的是: 假如服务正在使用 ScriptEngine 处理计算,同时又有新版本发布,创建了新的ScriptEngine,此时直接暴露出去使用,会导致脚本未加载完成的错误。所以需要 ScriptEngine 所有准备过程(创建, 加载脚本和预热)封闭在工厂方法内,准备阶段完成,得到的就是完全可用的 ScriptEngine。
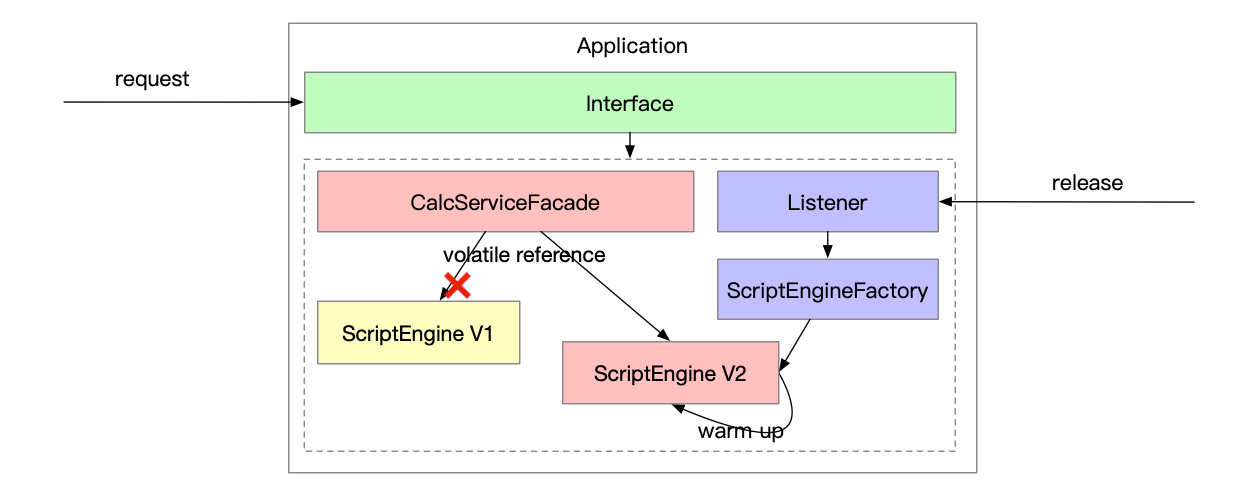
3.3 版本发布
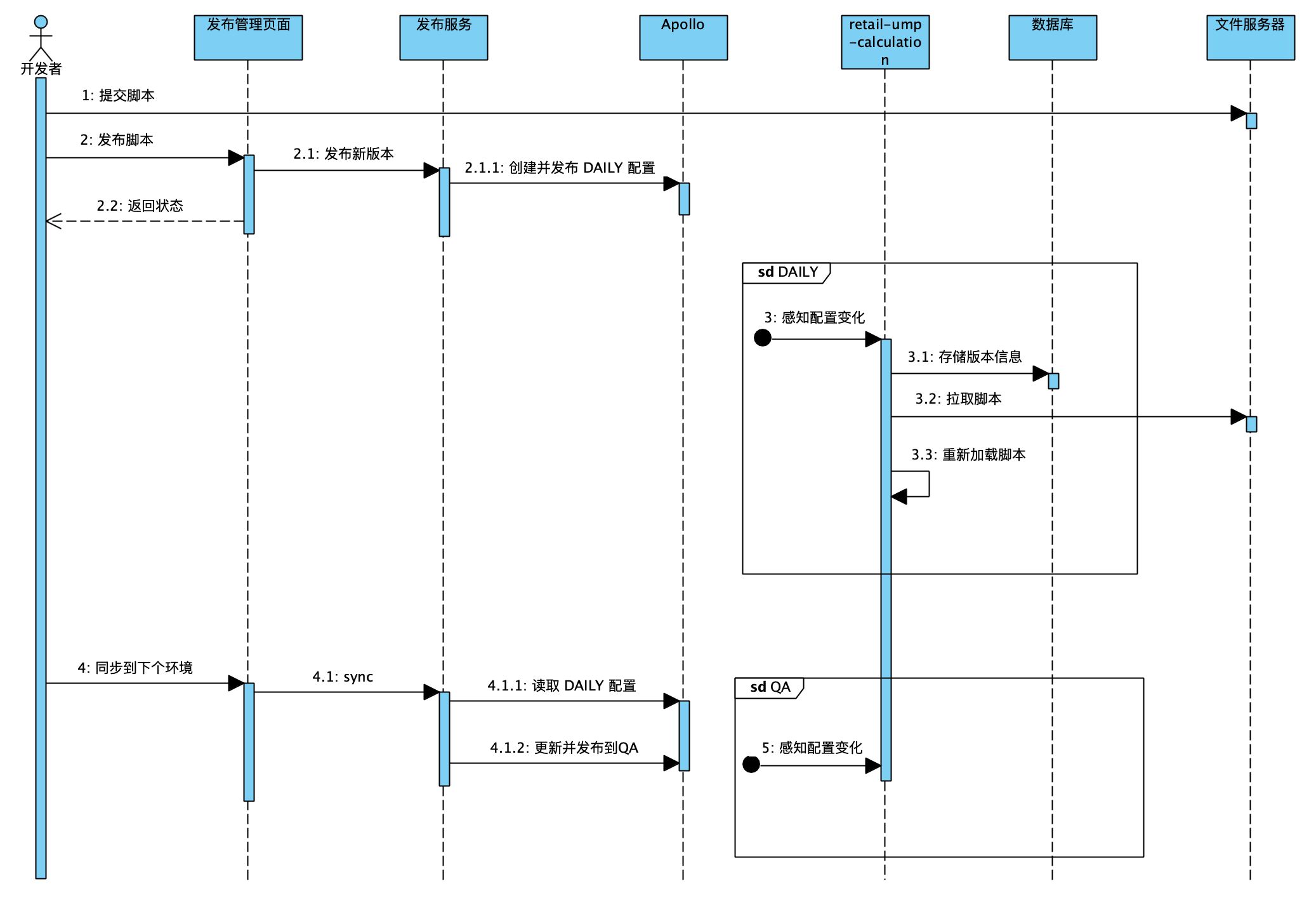
各端的版本发布流程大致相同:
- 将工程通过
webpack以区分Entry的方式进行打包,并上传至内部文件服务器 - 在发布管理页面操作,创建一个新的版本,绑定文件下载地址
- 将新的版本信息发布到配置中心
- 当前环境的服务端感知到配置变化,去文件服务器拉取脚本
- 加载新版本到计算服务中,预热,替换老版本,开始对外提供服务
- 当前环境确认服务稳定,同步至下个环境。跳转至 4
- 当前环境服务不稳定,通过配置中心历史记录回滚。跳转至 4
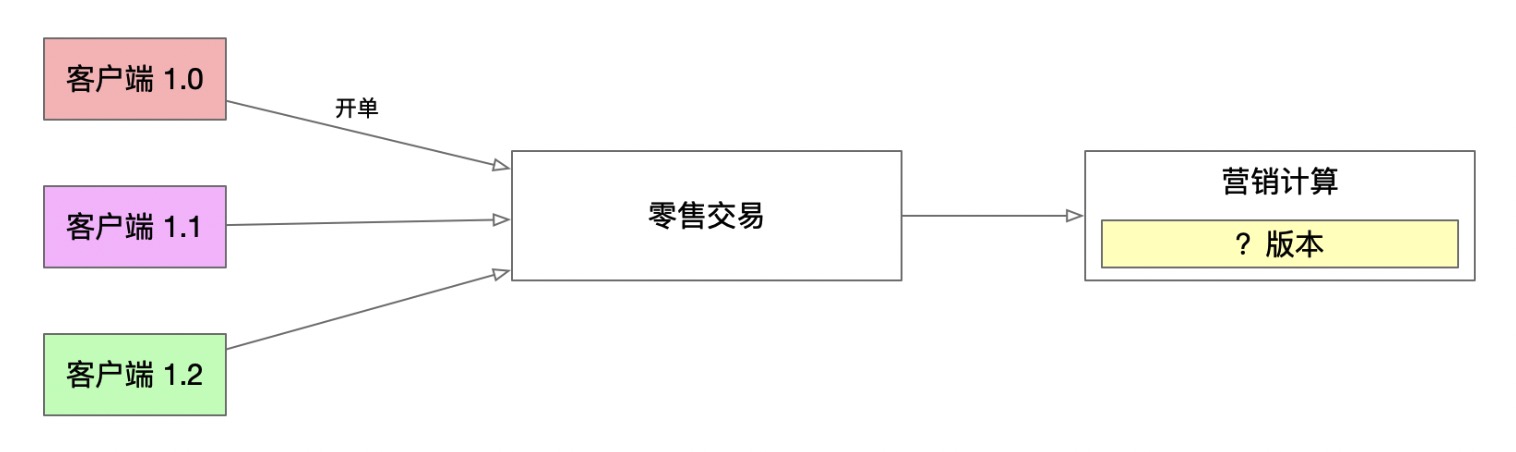
3.3 后续的挑战
3.3.1 支持校验不同版本的计算结果
对于不同版本脚本计算出来的结果,后端应该用什么版本去校验呢?
不同版本的差异可能体现在以下几个情况:
- 支持的营销活动的叠加互斥规则
- 不支持某些活动
- 活动使用顺序变了
- ……
3.3.2 如何向前兼容
方案 1:最新版本兼容所有老版本,需要很多feature-flag。历史包袱会越来越重,维护成本太高了。靠人脑去维护版本的兼容是不可靠的
方案 2:服务端按需加载相应版本在内存中,使用请求对应的版本计算。 无历史包袱,内存占用会越来越大 ✅
3.3.3 内存压力
先看看目前的 JS 文件大小和内存占用情况,JS 编译到 ES5 之后,文件大了一倍多。文件大小约187K
创建了 2 个计算引擎,加载完脚本占用内存 22.2M。经过粗略的计算,JVM ScriptEngine本身占用约 3M,加载一个 JS 计算脚本需要 7M 左右的内存成本


3.3.4 目前 JS 脚本 的模块分析
在 webpack 打包文件时,可以通过 webpack-bundle-analyzer 插件,分析出各个模块文件大小。统计如下:

文件占比大头在node_modules第三方包上,当加载多个脚本时,其实有很大的冗余,它们在内存中的表现如下:
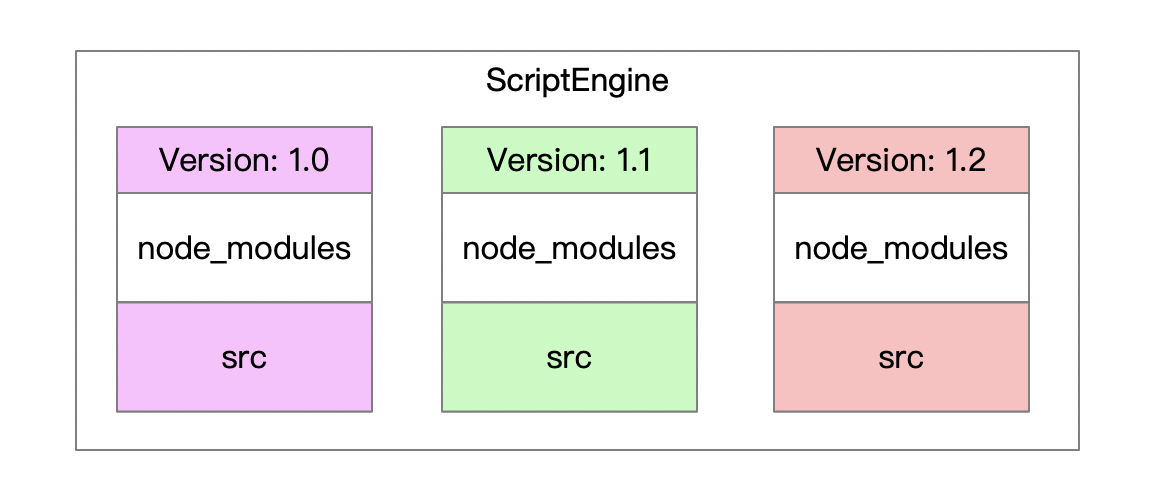
3.3.5 优化
可以通过 作用域隔离 的方式,分离不同的版本。 第三方依赖的包,是所有版本共享的。前提是后面依赖不会有变化,以订单优惠计算的业务来讲,不会需要新的依赖了。
优化之后,加载了 11 个版本。 内存占用 13M,除去JVM ScriptEngine占用的 3M, 加载一个 JS 计算脚只需不到 1M 内存成本。
结合目前的各端发版周期和版本覆盖率的情况来看,后端按需加载对应版本,不会有太大的内存压力。
4.已经遇到的问题
4.1 版本管理
一个代码库,多个平台发布。一般开发新功能,先拉特性分支,开发结束后合并到master,然后用 master来发布版本。但是当两端的开发需求同时进行,想要发布的内容,时间节点也不一样。那么代码如何合并、发布就是个问题。目前采用的方式是,代码仍然合并到master,各端拉发布分支的方式去发布。有新的特性或者修复,可以摘取过来,然后定期和master同步。缺点就是端的负责人需要关注新代码的合并,需不需要合并到发布分支,有没有冲突问题。这种方式只能算折中之举,后续还需要继续思考和探索如何处理会更好、更省事。
4.2 风险
收益与风险总是并存的。各客户端统一的核心逻辑是:开发一次,到处运行。这样可以很大程度上提升迭代速度和一致性。但是,如果有新功能开发,通常需要评估对不同场景的影响,回归核心用例确保稳定性。虽然系统本身有单测/集成测试覆盖,但依然增加了测试同学的工作量。庆幸的是,随着客户端自动化测试和后端沙盒录制回放的用例覆盖率增长,风险和工作量会逐渐减小。
5.总结与展望
截止目前,移动端和后端都已经稳定上线,投入使用。也就是说,有赞零售所有的线下收银场景都使用了这套计算框架。后面需要做的是,将自身平台有能力,但目前依赖后端计算的场景(PC 收银、自助收银大屏版),集成这套计算框架。实现本地计算,优化用户体验。
对于上线后近期的产品迭代,目前的模型设计和扩展性能够优雅的实现需求,如在「营销叠加互斥项目」中,对业务来讲属于大改的,其实对订单优惠计算的影响很小,很容易就实现了,得益于设计之初就将使用策略与计算逻辑分离。
在今后的迭代中,希望能保持项目的代码质量和良好设计 (附上邮箱 wengxiaofei@youzan.com 可内推、聊技术和代码整洁)
