有赞数据仓库背景
- 业务系统使用mysql数据库,有统一的DDL规范和SQL规范
- 数据仓库基于Hive构建
- 业务快速变化,员工数量持续增加
第一版:手工维护的表格
在有赞大数据平台发展初期,业务量不大,开发者对业务完全熟悉,从ETL到统计分析都可以轻松搞定,当时没有想过要做一个元数据系统。
随着公司规模扩大,开始有专职的数据分析师,作为大数据平台的新用户,希望能够记录和查看核心表的信息。最简单的方法就是去业务数据库里查看注释,但是一方面业务数据库的注释不全或不准,另一方面分析师的视角和开发者不同,需要从不同角度去描述表或字段,比如完整的枚举值含义、业务统计口径等。
于是有了第一版的数据字典,手工维护一系列核心的业务表和统计报表,记录了字段含义、统计口径的业务描述和sql语句等,用一个web界面展示。
第二版:自动采集的数据字典系统
第一版的数据字典,其实就是一堆表格,像个wiki,大家都可以上来编辑。当公司业务快速发展,靠人工维护这些表格已经力不从心。新增加了几个业务线,很多新增的表格无法查到,旧业务线也不断增加新表、新字段,手工维护的表格里的信息会不准。此时最强烈的需求是希望能获取到最新的表和字段信息。
我们尽量使用了拉取的方式,而不是订阅消息,开发成本更低:
- 对于mysql,定时从DDL管理系统查询最近有变更的表及其表结构;
- 对于Hive每半分钟扫描查询一次Metastore,获取最近DDL的表名,再通过Hive JDBC做表结构同步
- 定期全量从mysql、Hive里同步所有的表
技术方案落地的同时,我们还推行了mysql DDL的规范,表和字段必须加上注释,一个简单的规范可以省去很多后续的维护成本。
我们还遇到了因为业务变更,引起的报表不准确。在同步表和字段的基础上,我们又做了DDL变更的告警,这是首次做到通过元数据发现问题。
第三版:元数据驱动数据仓库
公司业务继续快速发展,又多了几个新业务线,有更多部门的用户在使用数据仓库。作为数据仓库的管理者,会遇到更多的问题。数据仓库的管理者希望能方便的看到系统或各个表的状态,数据仓库的用户希望能查到更多表的业务信息。而此时数据仓库还是一个黑盒,双方需求都不能满足,日常沟通、问题验证的成本很高,需要更多元数据的采集和展示。
参考Kimball的数据仓库理论,把元数据分为这三类:
- 技术元数据,如表结构、文件路径/格式;
- 业务元数据,如责任人、归属的业务、血缘关系;
- 过程元数据,如表每天的行数、大小、更新时间。
尽量把这三类数据都自动采集或计算获取,然后在web页面上展示或对外提供接口。这是当前版本的元数据系统,下面列举我们实现的核心功能。
血缘关系
“表”是元数据系统的后台逻辑核心,数据仓库是构建在Hive之上,而Hive的原始数据往往来自于生产系统,也可能会把计算结果导出到外部存储,所以我们认为Hive表、mysql表、hbase表、BI报表都是“表”,这些“表”间关系是一个DAG,也就是血缘关系。
表间的关系全部体现在SQL和ETL任务里。
- SQL:早期我们把SQL提交到Hive服务端做explain,得到import和output。为了支持字段级血缘分析,以及支持Presto SQL方言,我们对Hive提供的抽象语法树解析代码做了修改。
- ETL:我们的ETL工具基于开源的datax,数据源/目标包括了Hive、mysql、Elasticsearch、HBase、kafka等,每天收集这些ETL任务,并记录好源头和目标即可。
- MapReduce/Spark脚本:有不少这类离线计算,大部分都会用到Hive表,但是很难从python/scala这样的高级编程语言代码里解析出表名,此处做人工介入,创建或修改任务时,需要记录这个任务读写了哪张表。
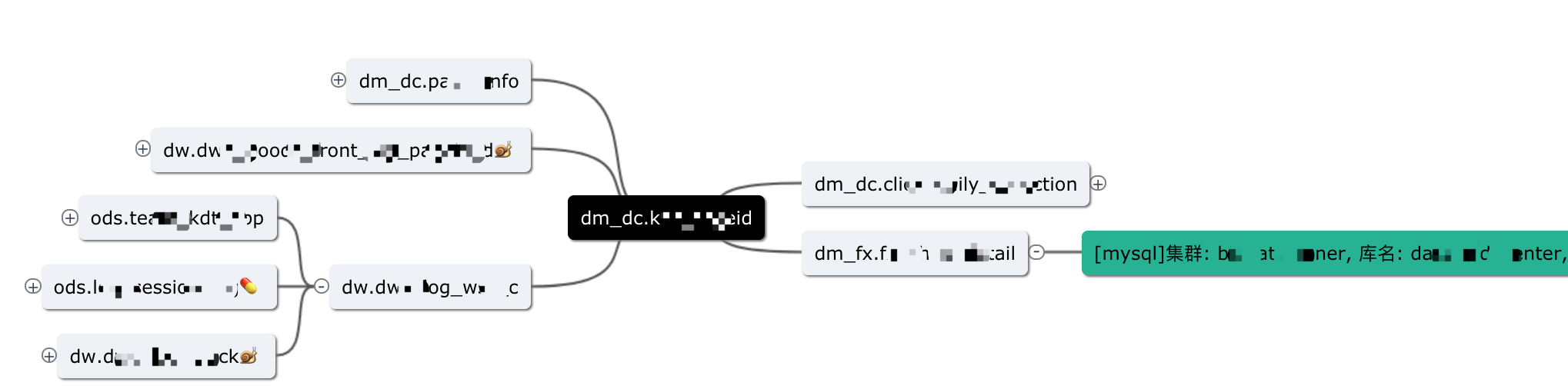
血缘关系案例
有了血缘关系,基于开源jsmind库做了展示,可以让用户清楚看到一张表的上下游,更方便地查找表。基于血缘关系可以做很多事情,例如:
- 结合表的更新时间,还可以找到调度DAG的关键路径,协助定位性能瓶颈;
- 当表出现变更时,可以通知下游责任人,以及自动对下游任务做SQL的静态检查;
- 辅助生命周期管理,找到没有被使用的表/字段;
- 辅助维护字段的一致性,如注释、校验规则复用。
Hive表行数/更新时间
我们记录了每个离线计算任务对应的Hive表,当某个任务执行结束,会立即做表行数/更新时间的采集。
- 文件大小/更新时间:metastore有记录但是不准。我们完全基于hdfs,读取文件的属性作为Hive表的大小与更新时间。再根据任务的启动时间,就可以得到计算出表所对应任务的执行时长。
- 行数:非常重要且明智的选择,使用Presto对全表或分区做count计算,这个SQL的执行效率是惊人的。对orc文件,简单的count计算,Presto并不会整个文件扫描,而仅仅读取orc文件的index data部分就可以得到行数。在实际运行中,几亿行的表都可以秒级得到行数。为了采集表的行数,我们下定决定把所有Hive表的存储格式改成orc。
表行数、文件大小、更新时间、运行时长的数据采集一段时间后,就可以形成曲线图,数据仓库管理员和开发者都可以从这个图中发现规律或数据质量问题,甚至业务系统开发者也会通过这个曲线图来查看业务量变化趋势。在行数采集的功能基础之上,我们还做了数据质量校验、数值分布探查等功能。把多个关键表的产出时间绘制到一张图里,可以清楚的看出数据仓库的稳定情况。
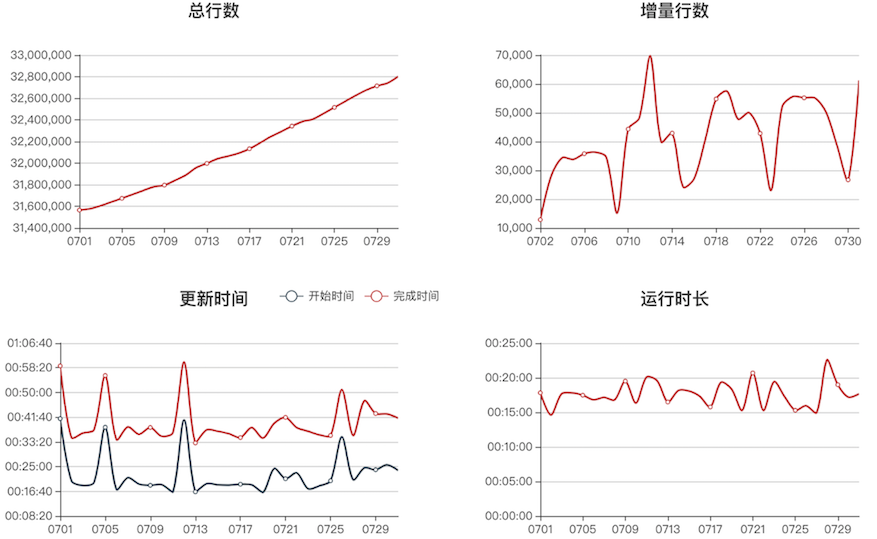
Hive表历史趋势案例
计算资源管理
前面提到离线任务结束,会做表大小/行数采集,同样的道理,也可以到yarn上采集相关任务使用的资源情况。如果是MapReduce任务,可以采集到完整的CPU、内存、磁盘IO使用情况,而spark任务则只能采集到CPU使用情况。把这些资源使用情况绘制成曲线图,很容易发现SQL的变更或异常情况。也可以把消耗的资源换算成硬件成本,找到最消耗资源的表或业务,督促开发者优化。
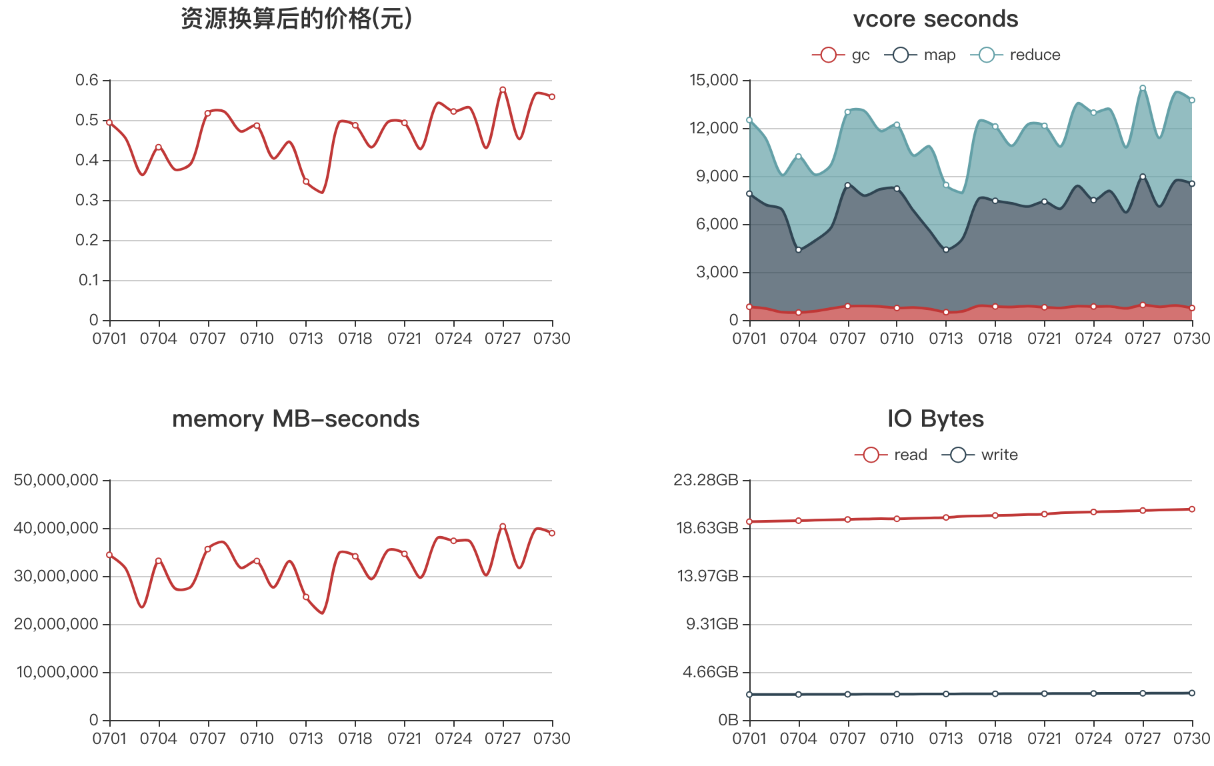
计算资源趋势图案例
数据同步规则描述
有赞的业务发展快,同时也意味着业务数据模型变化快,经常会发生业务表增减字段、拆表、迁库等动作,基于元数据的数据同步配置,很大程度避免了因为配置不一致导致的错误。在mysql侧,基于表结构的准实时同步,元数据维护了字段-表-库的映射关系,甚至记录了表迁移前后的地址映射关系,根据最新的状态动态生成数据同步配置。在Hive侧,记录了表是否分区、分区键、文件格式、hdfs路径等信息,用于生成读写Hive或HDFS的配置。
业务域管理
以前我们会维护一张表格,记录数据仓库每个业务的对接人,方便用户找到我们。后来我们把这个表格扩展成了业务域管理,除了记录业务与人的关系,还可以看出每张表属于哪个业务。
受到了apache ranger的启发,我们使用表名匹配的方式来动态的计算表所归属的业务域,只需配置几十个业务域规则,而不用对每张表分别配置。而与ranger采样相同匹配规则,使得我们做到了表、用户、业务多个业务视角任意切换,提升了元数据系统的业务扩展性,开发效率大大提升。
业务域扩展的权限管理
前面提到业务域是使用与apache ranger相同的表名匹配的管理方式,这样就天然把业务域扩展到了权限管理上。先给相关业务域的管理员或开发者配置相应权限,其余权限均需要申请。元数据系统并不存储这些权限信息,而完全依靠于ranger,这样避免出现不一致。
用户执行SQL时,利用Hiveserver自动在ranger做表级的鉴权;当用户申请权限并审批通过,会相应的在ranger上增加一条记录。
对于敏感字段,首先我们会通过定期的全库采样并分析的方式,判断字段是否是诸如手机号、邮箱、证件号等敏感字段并标记上密级,同时在ranger上增加masking配置,默认只显示其中的几位,例如证件号只显示最后4位。
下一步工作
我们访谈了公司里的很多元数据系统使用者,新手普遍反应上手困难,找不到想要的信息,而老手不存在这样的问题。究其原因,当前的元数据更多的是从系统管理的角度去描述,对新手并不友好。在管理者视角,数据仓库是表/字段、血缘、变化趋势;从开发者视角,数据仓库有数据模型、指标/算法。我们希望尝试从可视化的数据模型或者指标作为入口,方便新手用户查找。
我们还想提供一个更易使用的影响分析工具,当业务开发者做变更时,一方面能提供从业务mysql表到整个数据仓库的交互式影响分析查询,另一方面可以自动化的根据schema或者数据分布变化,感知对下游的影响。
PS: 大数据团队招聘中,内推邮箱:xiaomu@youzan.com
