
一、概述
1.1 遇到的挑战
不知道大家在日常工作中是否会经常遇到如下类似的问题:
- 商家:为什么 A 页面上的数据和 B 页面上的数据对不上?开发:我去看看(一段时间后),A 是来自 a 表,B 是来自 b 表,一个包含 XXX 状态的订单,一个不包含 XXX 状态的订单。
- 数据开发:同样的指标在不同的项目里被用到,开发 A 同学从 a 表里取了数据,开发 B 同学从 b 表里取了数据,我应该从哪里取数据? 指标的逻辑变了2张表都需要做对应的修改?
- 数据开发和 BI 工程师:没有现成的指标,我要的指标数据怎么来? 问数仓同学然后口口相传?
- ......
如果大家遇到过上述类似的问题,说明需要指标库这样的一套指标管理工具来规范指标的定义与维护。
问题1体现的可能的一种情况是指标定义不够清晰明确,两个页面上的指标定义其实是不同的,但是展示给商家看到的可能是同一个中文名称。又或者同样一个含义的指标在不同的界面上展示的名称却不相同,让人产生歧义。
问题2体现的问题是同一个指标因为由不同的数据开发同学来制作,可能会被重复开发,不但造成资源浪费,还会造成维护困难。
问题3体现的问题是对于需要新开发的指标,不仅缺少开发工具简化开发流程,甚至该使用哪些表,不该使用哪些表很大程度上都要凭借数据开发同学与数仓同学的经验。如果稍微马虎一点或者缺乏经验,比如使用了某些业务域下特有的表或者不是由数仓提供的统一中间层的表就可能会使用错误的数据,造成后期返工等情况。
随着数据需求越来越多,数据中台提供的指标也日益丰富。
但是各种指标定义混乱,描述不清。同样的指标存在于多张物理表内,造成取数混乱。谁也不知道我们到底有多少个指标,更没有沉淀出指标资产。
制作指标需要人工咨询数仓开发,口口相传,没有工具提供支撑。
BI 分析师在传统 BI 系统上分析数据,制作图表也仅仅局限在表,字段的层次,而不是维度,指标的层次。
......
为了解决上述问题,指标库应运而生。
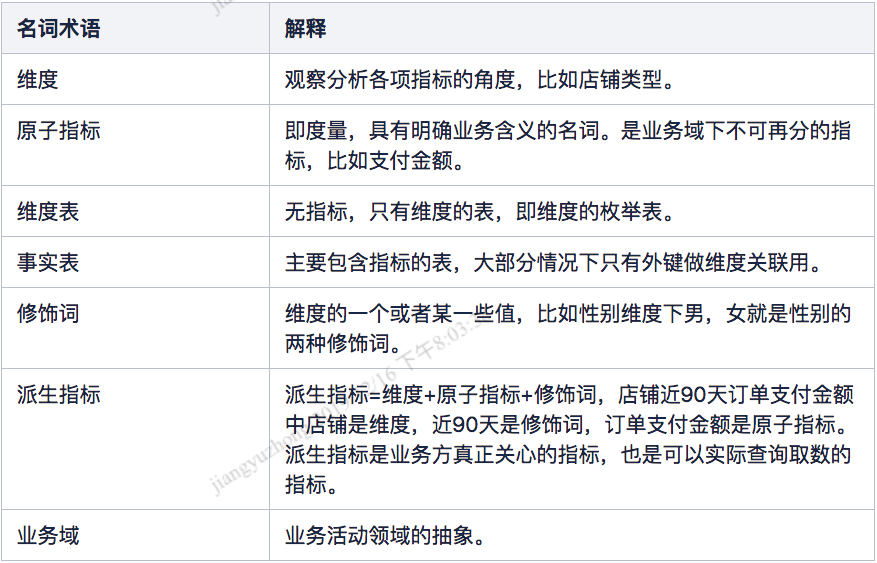
1.2名词术语
1.3 产品定位与功能
指标库给予每个指标一个精确且唯一的定义。通过指标库可以快速且规范的查询,开发和使用指标。
指标库主要提供如下服务:
- 通过设置指标的组成要素来唯一精确定义每个指标(派生指标)。
- 通过指标在业务域内唯一的性质,解决指标重复定义,重复开发,部分数据对不上的问题。
- 通过将数仓中间层录入指标库为新制作指标提供指导性的 SQL 或库表推荐。
- 打通其他各数据平台:
- 打通数据开发平台和统一数据服务平台,为指标的定义,调度,在线使用提供一条龙服务,简化开发流程。
- 打通数据资产管理平台,沉淀指标的资产价值。
- 打通 BI 平台,提供拖拽维度,指标生成报表的功能。
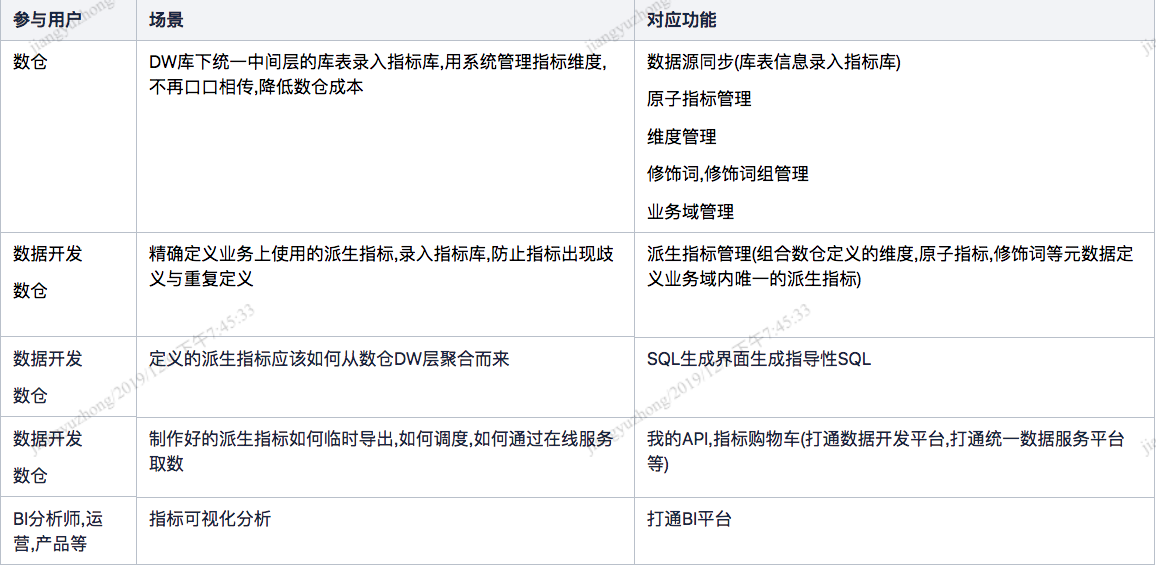
主要功能和参与用户
1.4 开发流程
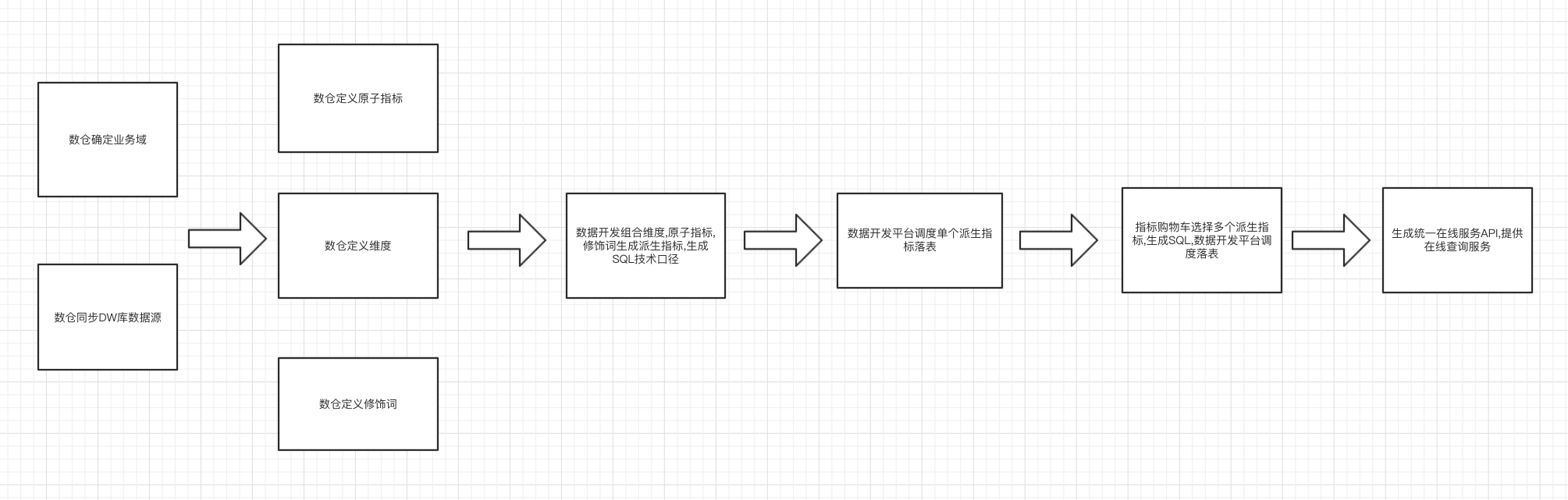 第一步:数仓先确定业务域并导入 DW 库统一中间层的表。要录入的维度指标属于哪个域先确定下来,例如店铺属于店铺域,订单支付金额属于交易域。只要数仓内部自己有统一的规划即可。然后就可以导入中间层的表到指标库。
第一步:数仓先确定业务域并导入 DW 库统一中间层的表。要录入的维度指标属于哪个域先确定下来,例如店铺属于店铺域,订单支付金额属于交易域。只要数仓内部自己有统一的规划即可。然后就可以导入中间层的表到指标库。
第二步:数仓定义原子指标,维度,修饰词。如果之前没有定义过,就新建维度指标等,并关联到正确的表字段上,在第一步导入表的过程中也可以快速关联到已经存在的维度指标。
第三步:生成派生指标。 有了维度,原子指标等元数据,就可以定义派生指标了。利用指标库的 SQL 生成功能可以快速生成技术口径。同时在指标库上可以快速创建单个派生指标的数据开发平台调度任务。
第四步:应用派生指标 选择需要的多个派生指标后可以通过指标库快速创建多个派生指标的数据开发平台调度任务和统一数据服务的在线 API。至此就可以在线上查询一批指标的数据了。当然指标库上也支持临时查询指标的数据。
二、主要功能
2.1 数据源同步
指标库中指标数据的来源一般都是从 DW 库,数仓统一中间层的表中通过计算得来。不是所有的库表都可以进入指标库。试想一下,如果任意业务方 DM 库下的库表都允许添加进指标库,如何保证指标的口径是正确的?甚至各业务方可能会在任意时间修改自己的库表结构。所以指标库最基础的元数据,比如维度信息,原子指标信息等都是使用数仓统一中间层。
数仓可以通过指标库快速添加某一张表,同时将表上的字段关联到指标库推荐的维度和原子指标,这也有助于数仓规范库表字段的命名。
(如下图,导入一张库表以后检测库表字段,推荐关联到已经定义过的原子指标和维度上,当然也可以在维度和原子指标界面上去关联表的字段)

2.2 维度管理
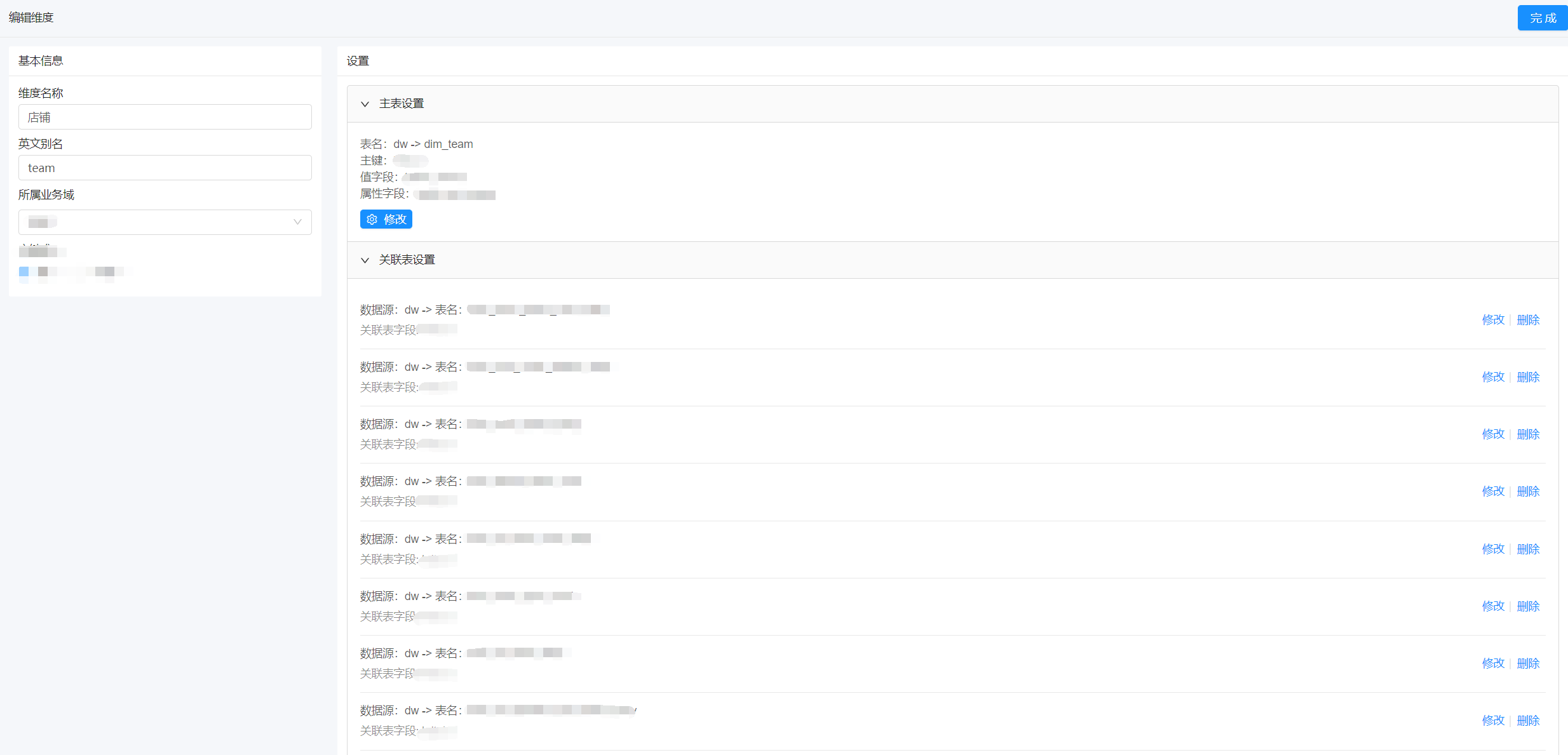
维度是观察事物的角度,比如店铺维度下近90天支付金额中,店铺是一个维度。在 SQL 中一般是 group by 的部分。数仓定义好维度以后需要设置维度的维度主表和关联的事实表。
2.2.1 维度主表
一般来说每个维度都会有一张主表。维度主表上一般会有三种类型的字段:
- 维度主表主键:一般都是 ID 这种,比如店铺的 ID 。有些情况下会有多个字段做联合主键。在维度主表上有1-N个。
- 维度主表值键:一般都是名称,比如店铺名称。在维度主表上有1个。
- 维度主表属性:一些其他的辅助信息。查询的时候也可以查询出来,用于提示。比如店铺的负责人是谁,店铺 URL 是什么,类似这些信息。在维度主表上有0-N个。
2.2.2 关联的事实表
维度需要关联事实表(存在指标字段的表)。关联事实表的操作其实就是在标记当前这个维度出现在哪些事实表上(可以和哪些指标组合)。事实表上一般会有维度的两种字段:
- 外键:一般字段名字和维度主表的主键一致,是事实表的外键。用于事实表和维度表做 join 操作。在事实表上有1-N个,数量和维度主表主键一致。
- 值键:有些情况维度表在事实表上会有值键的冗余,这种情况下事实表可以不需要和维度表做 join 就能取出维度信息。在事实表上有0-1个。
2.3 原子指标管理
原子指标和度量含义相同,基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,具有明确业务含义的名词 ,如支付金额。原子指标描述的其实是一种指标的类型,比如订单支付金额,支付订单数,下单订单数,PV,UV 等等。但是仅仅一个原子指标是不能直接取数的。
比如访客数是多少? 这个问题就回答不了。因为这个问题没有指定具体的维度(是店铺维度下的访客数,还是商品维度下的访客数)和修饰词( 是最近1天的访客数还是最近90天)等信息。
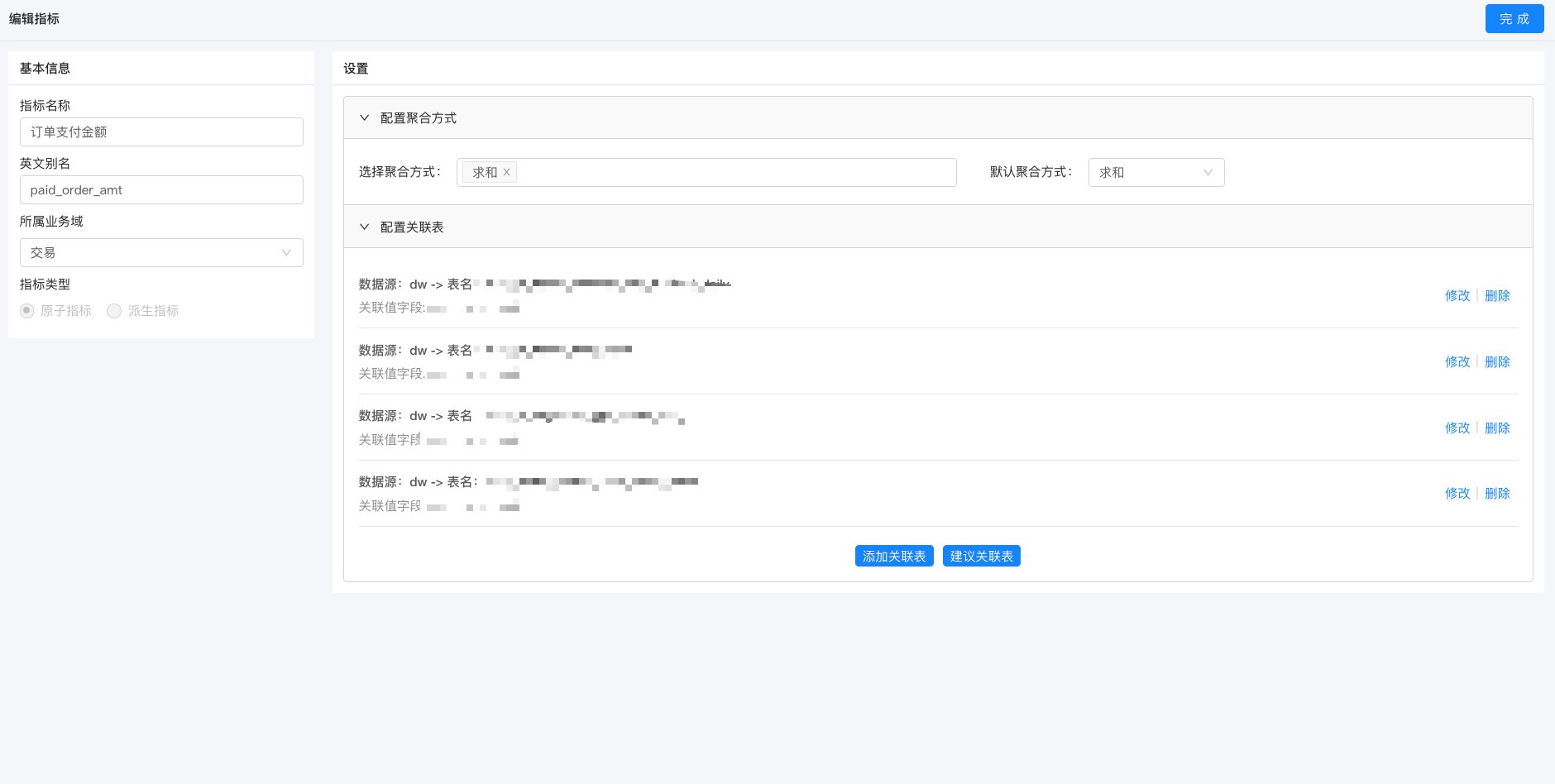
2.3.1 关联表
原子指标需要关联到具体的事实表和字段。 如上图配置了数仓统一中间层 DW 层的4张表。这意味着当前这个指标的数据可以从这4张表里取。 为什么会有4张表而不是1张表? 因为这4张表可能是不同维度的,适用于不同维度情况下的当前指标的取数。 原子指标关联事实表只需要指定事实表上的指标字段即可。每张事实表都是等价的,不需要设置主表。
2.3.2 聚合方式
聚合方式描述的是当前事实表上的指标如果需要做聚合运算,可以使用的聚合方式。 默认聚合方式就是按维度做聚合的时候如果没有指定聚合方式时采用的聚合函数。 比如数仓中间层表提供的表里有店铺,用户,支付金额3个字段。 如果业务需要看店铺维度下的支付金额。那就需要对店铺做 group by ,对支付金额做 sum。 这里的 sum 就是配置的默认聚合方式。
2.4 修饰词管理
修饰词是维度的某一些特殊的值。对应 SQL 中的 where 过滤条件。 比如业务方想看店铺维度下的 weapp 的支付金额。制作出来的表结构可能是如下图这样的结构。
 weapp 可能只是渠道下某一个值。因为业务方的需求仅仅只是查看 weapp 渠道,不需要查看其他比如 H5, web 等渠道,所以表结构可以没有渠道这个维度,而把 weapp 修饰词直接做在事实字段上。
weapp 可能只是渠道下某一个值。因为业务方的需求仅仅只是查看 weapp 渠道,不需要查看其他比如 H5, web 等渠道,所以表结构可以没有渠道这个维度,而把 weapp 修饰词直接做在事实字段上。
SQL 大致是这样的形式:
select sum(支付金额) from table group by 店铺 where 渠道 = 'weapp'
从中我们可以看出,维度和修饰词有一定的相互替代的作用。什么时候用维度什么时候用修饰词目前并没有严格的定论。只是能用维度来解决的问题尽量用维度,而不是修饰词,因为维度是一种更加通用的形式。业务方可以在自己的 mysql 库再根据自己的需要对维度做过滤。
2.5 派生指标
维度和原子指标更多的是站在数仓和 BI 的角角度设计的,符合数仓的星型模型。每张事实表上存在多个指标,每张事实表含有多张维度表的外键。但是业务方更关心的指标,是有实际业务含义,可以直接取数据的指标。比如店铺近1天订单支付金额就是一个派生指标,会被直接在产品上展示给商家看。
但是这个指标却不能直接从数仓的统一中间层里取数(因为没有现成的事实字段,数仓提供的一般都是大宽表)。需要有一个桥梁连接数仓中间层和业务方的指标需求,于是便有了派生指标。
从上述的例子中可以看出派生指标=维度+原子指标+修饰词。当维度,原子指标,修饰词都确定的时候就可以唯一确定一个派生指标,同时给出具体数值。 店铺近1天订单支付金额中店铺是维度,近1天是一个时间类型的修饰词,支付金额是一个原子指标。业务方制作每一个派生指标都是通过选择维度,原子指标,修饰词三种元数据来定义的,相对于使用名称来区别不同指标,更可以保证指标的唯一性。 如果2个派生指标是不同的,那他们的组成部分一定会有区别,或是不同维度,或是不同原子指标,修饰词。
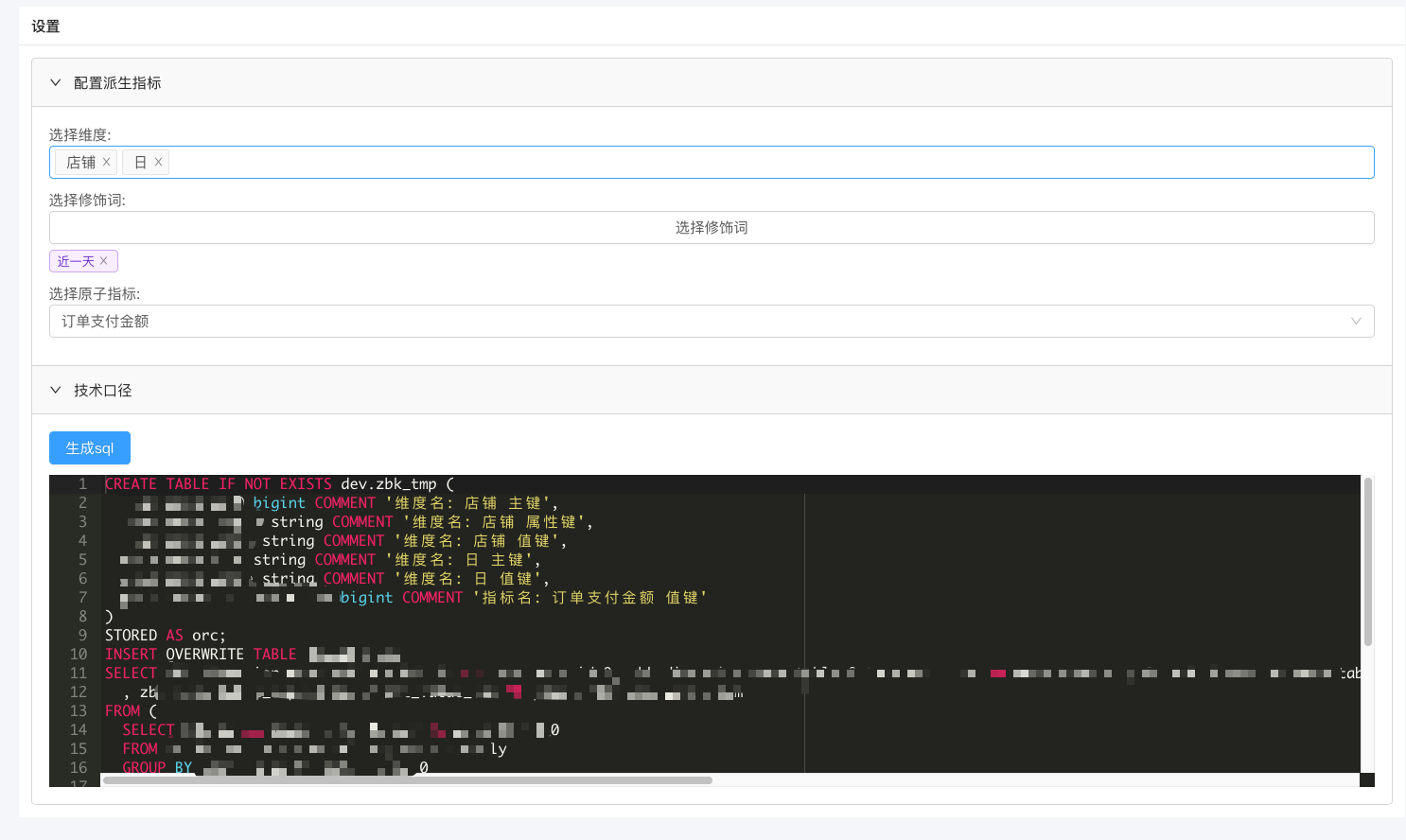
通过这种方式创建派生指标。因为维度和原子指标的在信息指标库里已经被标记,指标库可以生成取数的 SQL(通过数仓 DW 中间层聚合而来)。简化指标的开发。免除数据开发同学因为缺乏经验或者不了解数仓中间层带来的困扰。生成的 SQL(数据同学可以基于这个 SQL 做修改,有些时候需要 SQL 优化)也做为派生指标的技术口径。
当后续项目需要用到这个派生指标的时候,可以来指标库里检索,并查看使用这部分取数逻辑。避免指标重复开发(就算不检索直接新建派生指标也会失败,三要素唯一确定一个派生指标,重复创建可以被检测出来),消除歧义。
2.6 指标购物车与我的 API
单个指标的技术口径确定以后,仍然有一些问题需要解决:
- 需要对单个派生指标进行调度定时产生数据。
- 因为业务方一般一个 SQL 会查询出多个相同维度下的指标,所以需要对多个派生指标进行合并,放到一张表上。
- 业务方一般使用 mysql 等其他组件,需要把数据从 hive 写入 mysql。
- 取数的时候通过统一的 API 操作,而不是为每个指标都写一个 dubbo 接口。因为这样会有很多重复开发接口的工作量。
指标库通过集成有赞数据开发平台解决1,2,3问题,通过集成统一数据服务平台解决问题4。
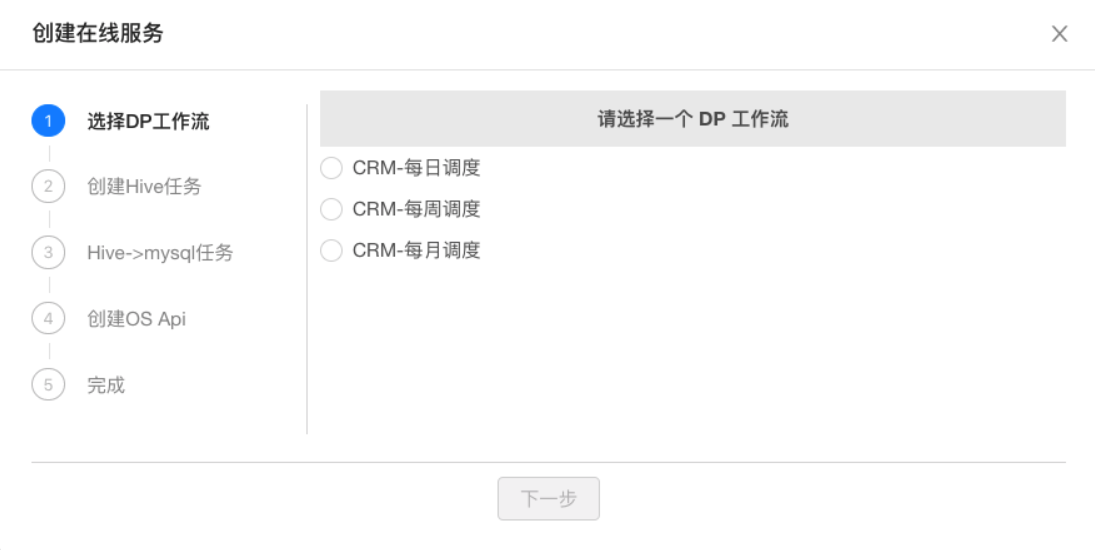
无论是单个派生指标还是多个派生指标,添加到指标购物车内以后可以创建在线服务的 API,指标库会自动在数据开发平台上新建对应选择的工作流下的任务节点,在统一数据服务平台上新建 API。开发者只要稍加完善便可以快速将指标应用到在线服务。
 通过这种方式也可以将指标,数据开发平台的调度任务,导出任务,在线服务 API 关联在一起。指标库打通各内部平台,提供指标从定义到调度生产,到在线查询的一条龙服务来简化开发流程。
通过这种方式也可以将指标,数据开发平台的调度任务,导出任务,在线服务 API 关联在一起。指标库打通各内部平台,提供指标从定义到调度生产,到在线查询的一条龙服务来简化开发流程。
三、小结与展望
指标库是从传统的垂直数据产品开发到数据中台能力复用的过程中出现的项目。指标库在有赞的实践体现了我们对指标数据定义、生产、使用等过程的流程规范化与平台化的一种尝试。当然,指标库在有赞还刚刚起步,还有众多挑战与困难等待着我们去克服。
