一、背景
2020H1我们开展数据中台-离线数据成本治理并取得了一定的成效(详情可以参考往期文章:从量化到优化,详解有赞离线降本之路)。文中预告了下半年会拓展成本治理的范围,H2我们便开始思考并投入有赞数据的全局管理。不限于离线数据,实时数据、内部的平台工具均需要做到可管理、可治理。
此外,数据成本透明度同样需要提升。目前成本只能覆盖至数据中台内部,和前台业务关联度低的问题需要解决。用户层面,我们也收到了诸多需求,例如需要相对灵活的成本分析功能、可满足多种角色的分析视角等。
带着这些问题和用户需求,我们开始构建数据中台的全域成本账单,力求达成如下几个目标:
- 成本多类型支持
- 成本全业务覆盖
- 多分析手段提供
- 运营全渠道开展
本文将围绕这四个目标,分享下我们在构建全域账单过程中的所做的工作,克服的困难以及收获的成果。
二、 成本多类型支持
2.1 成本梳理
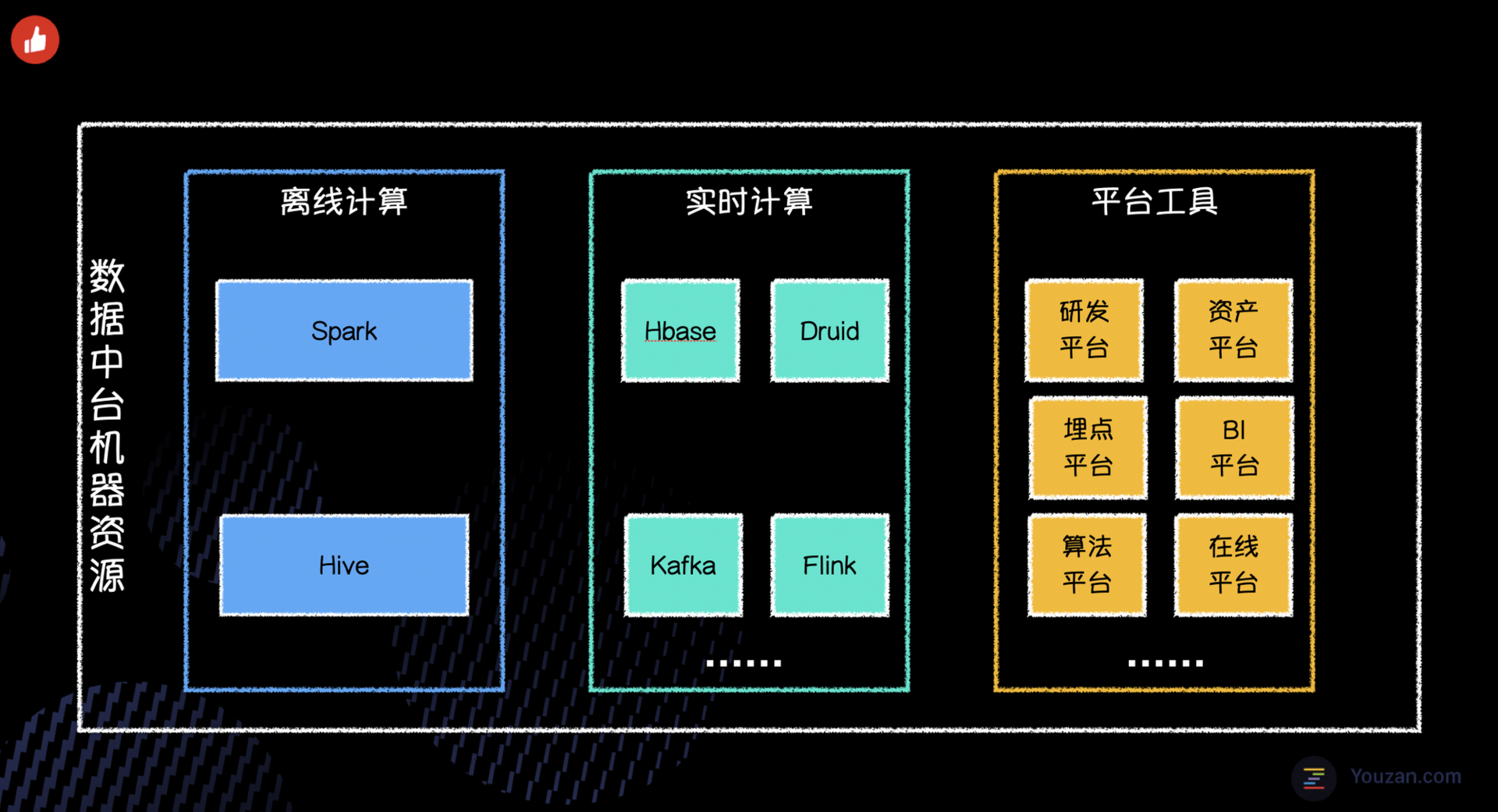
数据成本多类型支持,是指我们要支持数据中台所有类型的资产进行成本的量化。首先我们来看一下成本到底都花在哪里。我们重新审视了数据中台的成本组成,从服务类型的视角,可分为如下3种类型:
- 离线计算
- 实时计算
- 平台工具
如下图,离线计算主要包含 Spark 、 Hive 等离线计算组件;实时计算主要包含 Hbase 、 Druid 、Kafka 、Flink 等实时计算组件;平台工具即为中台内部的平台型产品,例如数据研发平台、资产治理平台、BI报表平台等。
从硬件的角度来看,其实我们付出的成本就是各类机器资源,机器资源一般会包含 cpu 、内存、磁盘、网卡等等。基于大数据运维同学较为完备的机器资源获取服务,可以快捷的拿到每一台机器的硬件信息以及采购成本(当然这里的成本是脱敏后的成本)。这样我们就完成了成本量化的第一步,明确各类型资源的实际耗用成本。
2.2 信息采集
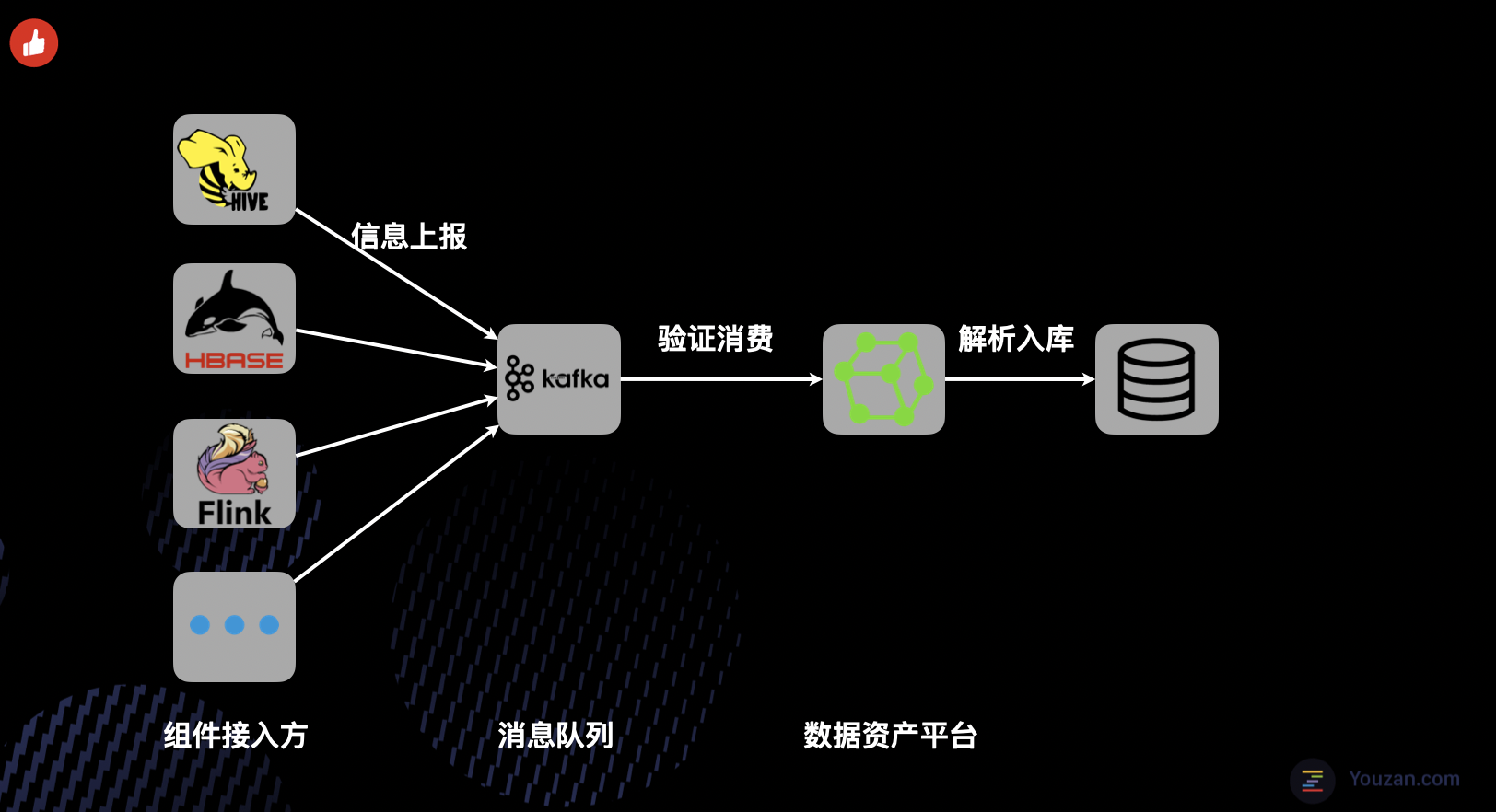
单单知道机器资源的组成和付出成本还是不够的,因为机器资源并不是100%被使用了呀。我们还需要知道实际运行在机器上的数据任务信息、客户端的访问信息、数据的存储信息等等。要采集上节中提到的这么多种基础组件的运行信息,想想都让人头大。
如果一一和这些基础组件进行对接、评审、联调,必定会花费大量的时间。同时如果采用 API 接口的采集上报方式,会造成系统之间的耦合,后续的运维成本较大。基于这些考虑,我们设计开发了资源信息采集的 SDK。
采集 SDK 主要具备如下特点:
- 统一的数据模型抽象,新增接入方无须工作量投入。
- 使用 Kafka 进行系统间解耦。
- 完善的数据验证和质量保证机制。
下图为目前大数据基础组件的信息上报方式。基于这种形式,新接入组件的耗时可以控制在1天以内。
2.3 成本量化
各类资源的总成本和资源消耗信息我们都有了,接下来就到了最关键的一步-成本量化。和服务场景一样,我们也来分为3部分介绍成本量化的方式。
2.3.1 离线成本
离线成本的核算方式此处不再赘述,有兴趣的同学可以参考我们之前的文章。
2.3.2 实时计算
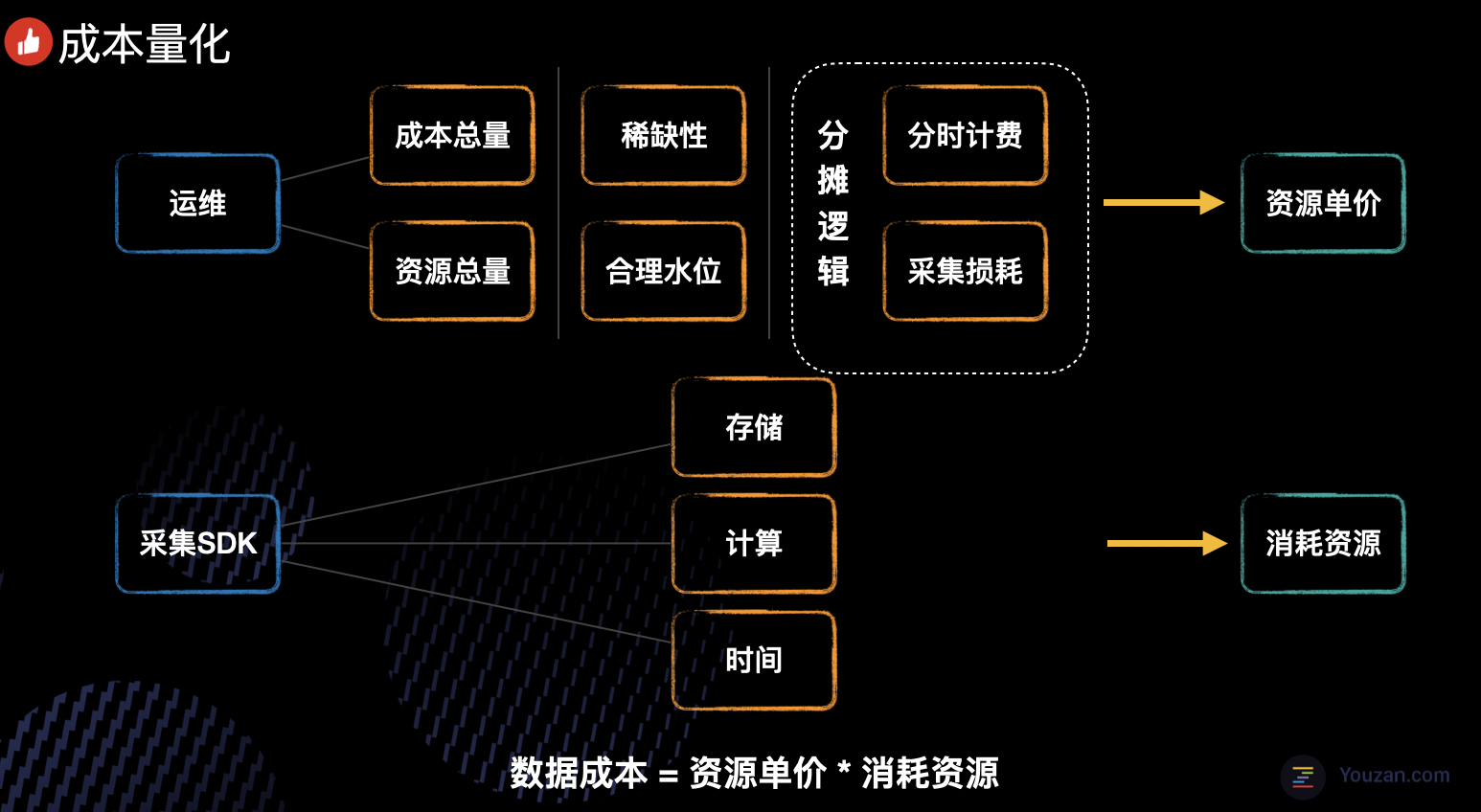
实时计算相比离线的场景会更加复杂,因为涉及到的组件种类很多,同时每个组件的核心资源和理想水位也是不同的。比如 Hbase 的资源瓶颈在磁盘大小和 IO,cpu 利用率往往很低;而 Flink 实时计算,更消耗 cpu 和内存。但是万变不离其宗,所有组件的成本量化可以归纳成如下的几个过程:
- 采集到成本总量和资源总量。
- 根据不同资源的稀缺性及合理水位,再结合一些分摊逻辑,计算出对应的资源单价。
- 最后结合采集SDK采集到的资源消耗信息,算出最终的数据成本。
下面以 Flink 为例进行说明成本计算的方式,首先我们来准备成本计算需要的核心信息
- Flink 核心的资源信息主要是 cpu 和 memory ,根据集群的资源配置,确定 cpu 和 memory 的分摊比例分别为 cpu_index 和 memory_index。
- 确定 Flink 集群合理的水位,记为 load (水位可结合历史趋势以及预留资源情况来确定)。
- 采集到集群总的资源成本为 total_cost。
- 采集到总硬件资源 total_cpu 、total_memory。
基于上述的数据,最终我们可以得到 cpu 和 memory 的定价分别为
cpu_price = total_cost * cpu_index / (total_cpu * load)
memory_price = total_cost * memory_index / (total_memory * load)
之后我们再根据采集到的每一个Flink任务配置占用的 cpu 和 memory 资源,就可以得到 Flink 任务的成本了
task_cost = cpu*cpu_price + memory * memory_price
依据于这个思路,我们对其他的实时组件,例如 Hbase 、Druid 、Kakfa 均进行了成本量化,使得每一张表、每一个任务都有数可依。
2.3.3 平台工具
由于这部分的成本占比相对较少,平台工具类的成本计算就比较简单了,直接使用平台机型的价格即可。当然,和上面的各类成本信息一样,我们提供的成本信息均为脱敏后的数据,我们更关心的是成本的相对趋势,而不是绝对值。
2.4 小结
经过成本梳理→ 信息采集 → 成本量化这几个流程,我们完成了数据中台的3类服务场景(离线、实时、平台工具)、6类数据资产类型( Hive 、 Hbase 、Flink 、Kafka 、Druid 、平台工具)的成本覆盖,其他类型的数据资产依照于上述方式均可快速接入成本账单。
三. 成本全业务覆盖
有赞目前的业务线单元已经有很多,不可避免的都在使用着数据中台的数据能力。中台的管理者想要了解支撑不同的业务线到底花了多少钱,业务线的负责人也想要了解自己为拥有的数据资产到底付出了多少。简而言之,我们要提升数据成本的透明度,算好每一笔账。
3.1 业务域治理
要做全业务域的成本覆盖,我们先来看看业务域都包含了什么信息?重新审视并梳理之后,我们发现当前的业务域管理模式存在着定义模糊、标准不一、覆盖率低等一系列问题。
3.1.1 定义模糊
业务域应该更加专注于业务本身,当前的业务域中混杂了其他的概念,例如部门、平台组件、系统模块等等。
针对业务域定义模糊的问题,我们将目前的数据域区分为3类
- 业务线,代表着有赞的对外产品
- 通用业务域,包括数仓中间层等
- 平台/模块域
这种模式,可以较为清晰和系统的看到目前的数据流转情况,同时也为接下来的进行成本分摊奠定了基础。
3.1.2 标准不一
数据中台内部的平台组件,因研发周期的差异及统一标准的缺失,造成业务域的标准存在较大的偏差。针对于这个问题,资产治理平台对外提供统一的业务域标准接口,方便数据中台内的平台产品接入,将之前散乱的业务域标准进行统一。
3.1.3 覆盖率低
不同的资产类型进行业务域归属的策略是不同的,离线数据我们按照表命名规则进行业务域归属,整体的覆盖率会比较高。而其他类型就相对没有那么理想了,针对于无业务域归属的数据,我们首先规范数据申请流程,在源头上堵住了新增的异常数据,同时对于存量数据进行集中式整改。
当前我们的业务域整体覆盖率已经提升至90%以上。

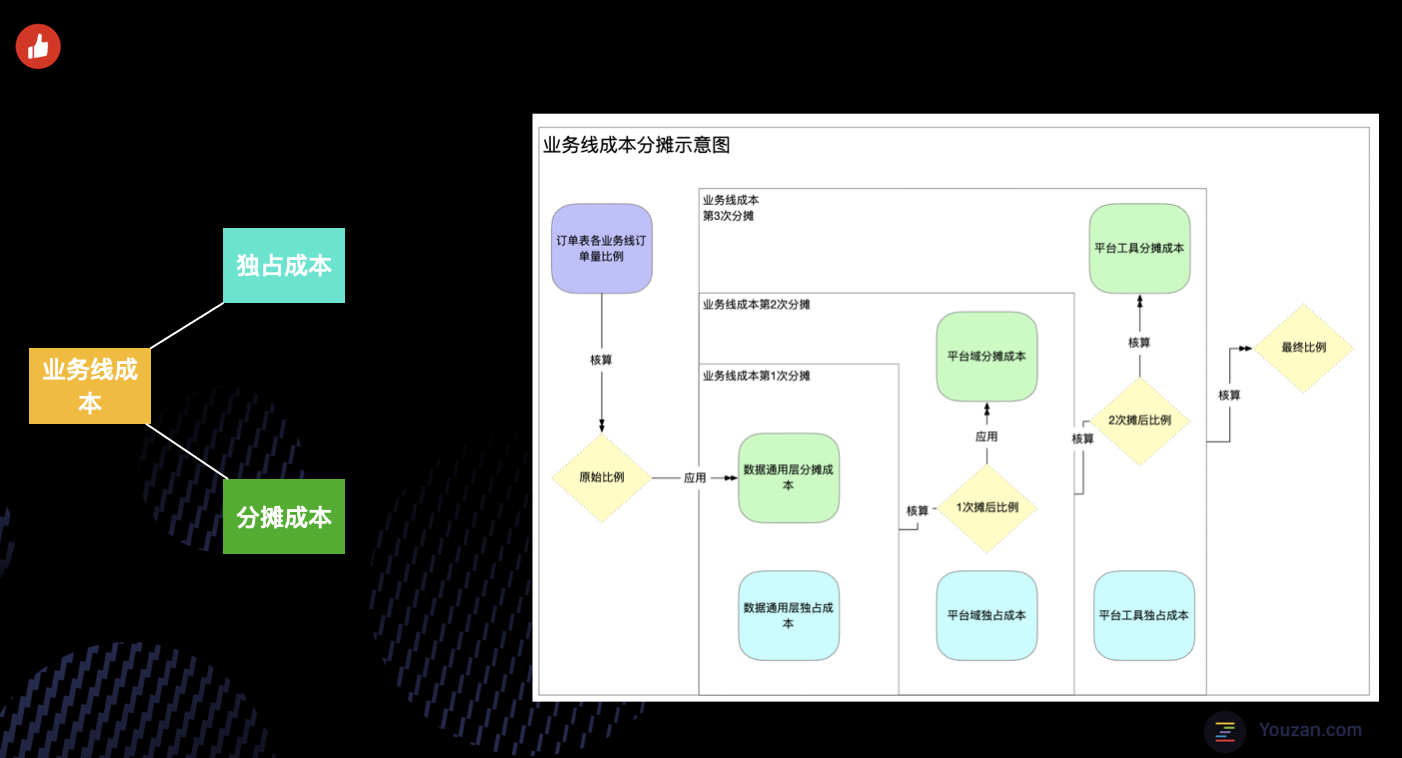
3.2 成本分摊
业务域治理终于告一段落了,可以开始着手将成本分摊至业务线了。根据成本使用的情况,分为分摊成本和独占成本这两个部分。
以有赞美业为例,作为垂直型的业务单元,必然会使用到数据中台的通用数据能力,例如交易、支付、日志、客户等。同时也会有部分独占的美业数据,例如美业数据集市层。独占部分很好理解,使用了多少就承担多少。分摊部分怎么去界定呢,而分摊的比例应该是多少呢?别着急,接着往下看:
- 首先我们会初始化一个默认的业务分摊比例,这个比例目前是每日的业务订单占比。
- 针对于数据通用域的成本,会按照这个比例将成本分摊给其他业务线。同时在数据通用域中也会有单独为某条业务线服务的数据,这部分要和分摊部分进行合并,作为该业务线的总成本。
- 两部分合并计算后,就得到了业务线分摊通用域的成本,同时也得到了一个分摊比例,记为一次摊后比例。
- 使用一次摊后比例作为分摊依据,沿用步骤2中的逻辑进行平台域的成本分摊,得到二次摊后比例。
- 使用二次摊后比例作为分摊依据,沿用步骤2中的逻辑进行平台工具类的成本分摊,最终得到各个业务线的成本。
四. 多分析手段提供
通过需求搜集和用户场景分析,不同角色的小伙伴关心成本的视角是不同的。中台管理者要关心全局视角下的成本情况,业务线负责人关系本业务线下的成本消耗,一线管理者呢,更多关心团队及团队内小伙伴的成本信息。为了满足这么多视角和场景的分析需求,首先我们要来好好设计一下数据模型。
4.1 数据模型
从建模的角度来看,业务线、部门、资源类型这些都是一些维度信息,耗用成本、可降成本、已降成本就是我们要关注的事实指标。我们要做的就是将这些维度信息和成本关联起来,提供多维的分析模型服务于用户。总结来说,其实就是一个典型的 OLAP 场景。
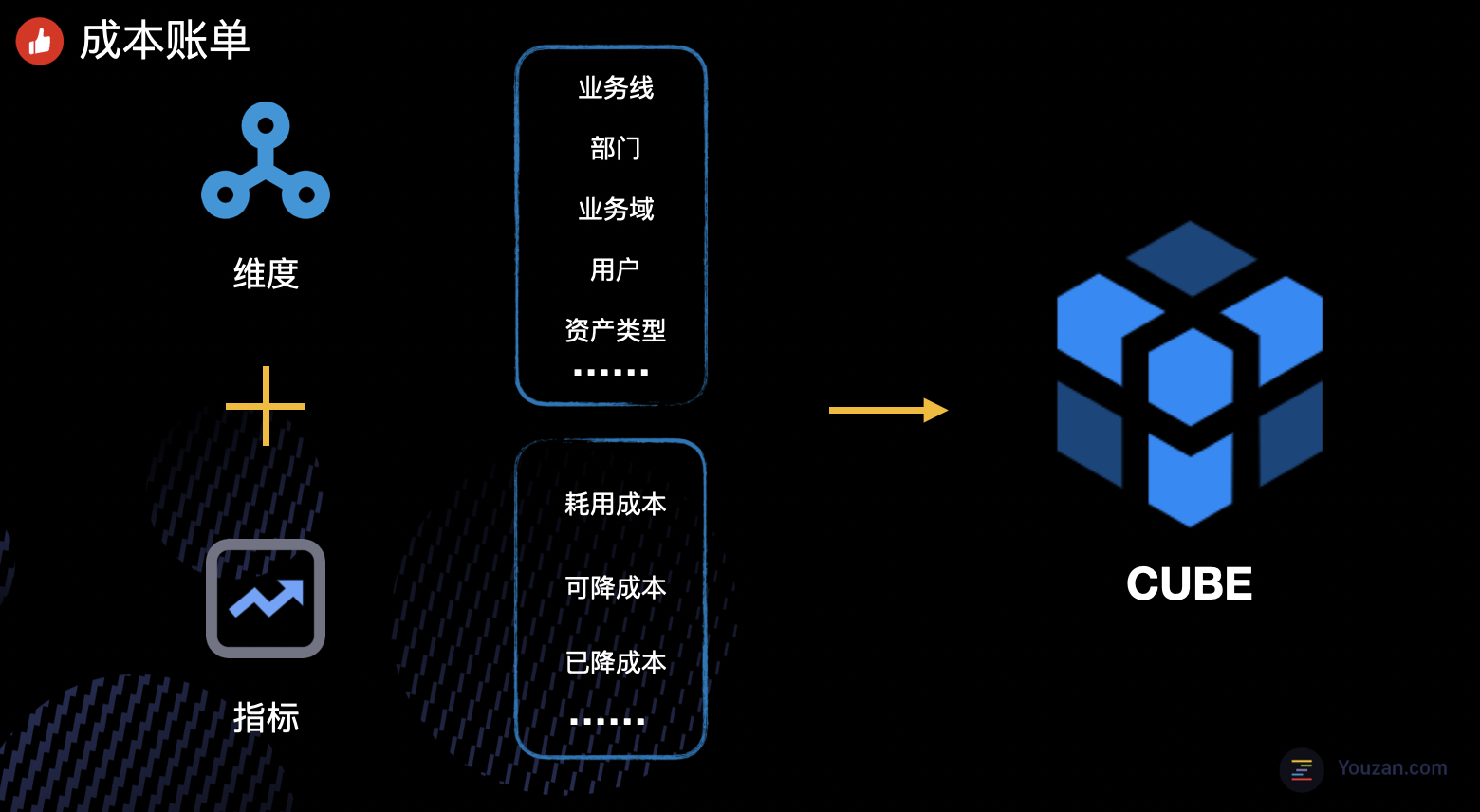
技术选型方面,基于目前的数据量和可预见的数量增长,最终我们没有选择引入 Kylin 或 Clinkhouse 这类 OLAP 引擎,而是借助于 Spark Cube 来生成多维数据集,以此满足多维度的查询。用户在界面上点选的种种查询请求,将转化为后端的动态查询条件,满足每一个用户的需求。
在权限方管理方面,全域账单的用户权限细化到用户级别,保证数据安全。
4.2 交互设计
交互设计方面,我们调研了小伙伴的核心需求,优先支持了如下的3类分析场景。
4.2.1 长周期的趋势分析
关注成本,我们往往不会仅仅关注某个时点。更多的我们要去关注某段周期下的趋势,支持趋势查看乃至分析就显得尤为重要。
4.2.2 钻取分析
做数据的同学都应该感同身受,大家都有一颗打破砂锅问到底的精神。哈,你告诉我实时计算资源花了好多钱,那我要看看是花在 Flink 还是 Hbase 上了。光告诉我 Flink 花了多还不行,还要告诉我那个任务花的多。目前我们的钻取分析可以支持从全局的成本钻取到最细粒度的数据,满足用户的种种疑问。
4.2.3 级联分析
级联分析呢,所谓级联就是指分析可以联动。例如当用户在分析成本趋势时,发现一周前的某天成本异常,锁定这天时,界面上的其他信息可以得到联动,方便再去做局部的分析。
4.3 小结
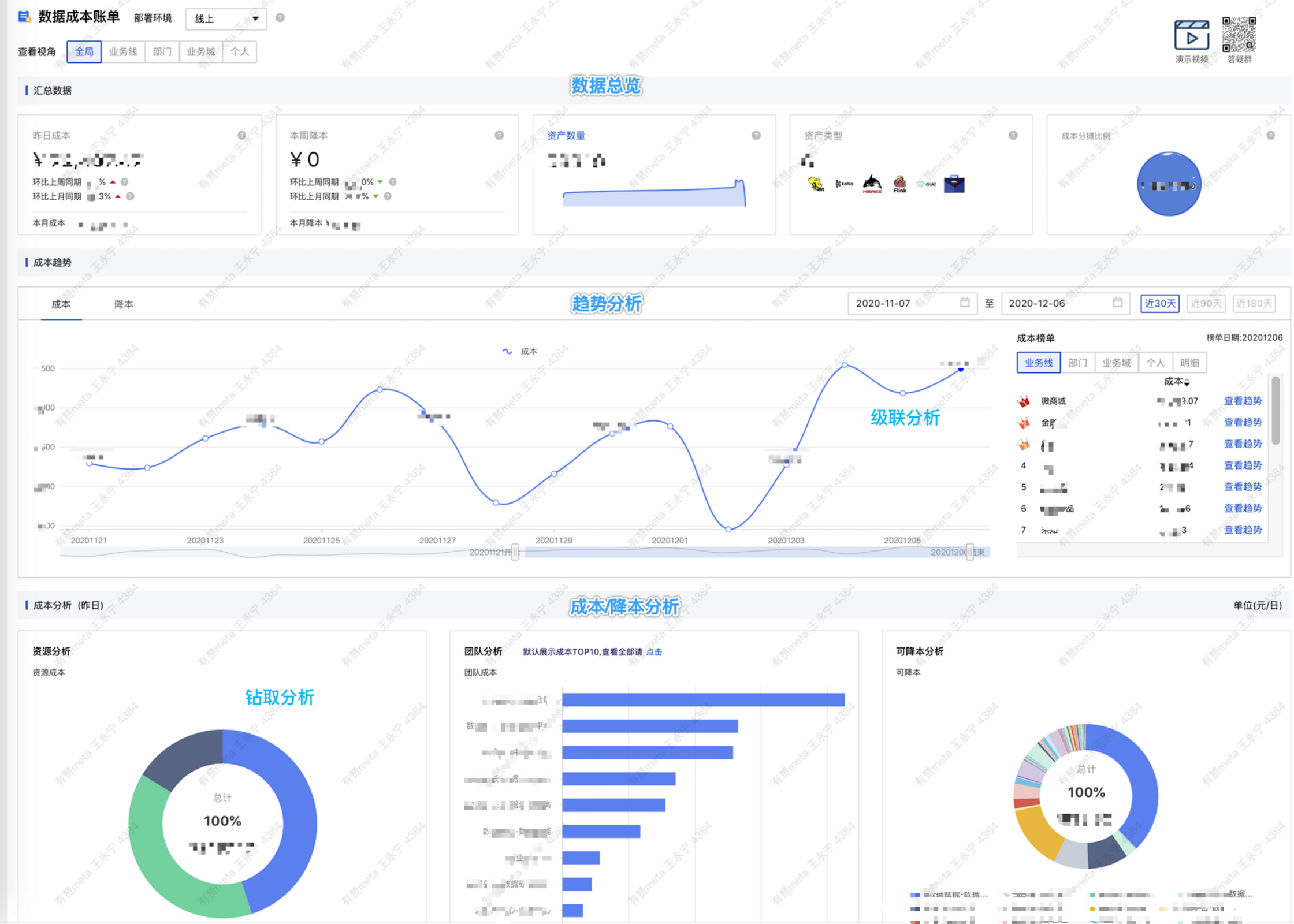
最后贴上全域成本账单的全貌,目前的账单已经提供 5v 视角查看(全局、业务线、业务域、部门、个人),支持动态趋势、钻取、级联等分析方式,方便各个角色完成想要的成本分析路径。
五. 全渠道账单运营
这下全域成本账单有了,是不是就大功告成了呢?怎么让更多的小伙伴用起来,从而达成 感知成本 ⇒ 关注成本 ⇒ 参与降本 这条我们希望的路径呢?当然,我们可以通过人工推进的方式去做,但是更希望通过技术运营的方式去达成。接下来会介绍我们在全渠道运营方面做的相关实践。
5.1 账单发布
全新产品上线,当然要有一次走心的发布会啦。为了让数据成本这个稍显沉闷的话题变得相对有趣,我们量身定做了产品发布小视频。将成本账单的设计思路、使用姿势等以视频的形式向大家呈现,帮我们吸引了一些小伙伴的眼球,快速的了解到底什么是全域账单。同时发布视频也承担了部分价值宣导的功能,让大家感受到我们在做的事情是有价值的。
5.2 受众拓源
全域成本账单,决定了我们的受众一定是广泛的。不光是参与数据开发的同学,需要覆盖到整个数据链路上的所有参与者,包括分析师、运维、数据产品。我们在受众拓源乃至账单运营上做了很多工作,总结来说,线上线下双渠道。
线上渠道,主要分为3个方面:
- 我们在持续的坚持制作并推出《降本小贴士》、《降本名人堂》等系列主题文案。向产品技术同学介绍降本工作的新进展、对降本工作贡献突出的个人及事迹,吸引更多的小伙伴参与进来。
- 就像支付宝的水电煤气账单一样,有赞的数据同样有月度账单。我们会月度向数据的使用者推送账单,帮助用户快速了解成本的使用情况以及潜在的降本点。
- 答疑群组是一个和用户沟通交流的好地方,我们会以意见箱这样的方式搜集整理用户的需求建议。定期同步需求的进度和新功能预告,让用户感觉自己受到了重视。
线下渠道,分为2个方面:
- 我们制作了宣传海报,在公司行政同学的帮助,成功化身厕所小报,帮助我们吸引了很多新的用户。
- 团队的月会这样的好机会我们不会错过,会向小伙伴们分享全域账单的前世今生。
通过线上线下双管齐下,慢慢的提升了全域成本账单的知名度。
下图为我们往期的降本小贴士以及成本账单宣传海报。

5.3 降本转化
通过受众拓源来了一些新的用户,当然是希望用户参与到节能降本中来的呀。怎么让一个账单的访客变为降本的参与者,这个是需要花费一些心思的。
举个简单的例子,我们开发了分区生命周期管理的功能。支持用户一键配置数据生命周期,过期的数据系统会自动清理,堪称“躺降成本”。上线后跟踪数据发现配置情况差强人意。进一步分析平台的埋点数据,我们发现该功能的触发入口点击率是很低的,但是转化率却很高。这就代表,主动点击的用户几乎都配置了数据生命周期参数。我们将这个问题抽象为一个公式:
配置数(即降本量) = 点击人数 * 点击配置率
当前配置率已经很高了,那我们要做的就是吸引更多的人进来。这里我们做了两件事,还记得上面的套路吗?线上+线下双渠道,一方面通过降本小贴士等渠道进行功能推广,另一方面在数据中台月会上进行功能宣讲,让更多人了解这个功能。
同时针对分区数据的负责人,我们会在其访问数据元信息时,进行弹窗提示,提示其可以配置生命周期参数来节省存储成本。 别小看这两件事,前期确实帮我们吸引了40%以上的点击人数,很开心很有效是不是?
但是,随后我们发现配置率下来了。通过埋点数据,我们发现部分用户接收到弹窗提醒之后,手动关闭了弹窗。我们和关闭弹窗的 Top N 用户进行沟通,发现用户关闭的原因是对功能不够了解或者对于安全性有所担心,针对这些问题我们答疑或者引导优化,最终提升了点击配置率。分区生命周期功能上线以来已节省了 PB 级的存储资源,释放离线存储资源30%以上。
举这个例子是想要说明,在降本的转化过程中可能会有一些环节导致未能转化,我们可以借助于数据的力量去帮助我们分析,指导我们做出改进。
六、阶段总结
目前我们已开发完成了一种统一采集的 SDK,可方便、高效的采集各类组件信息;一套兼容性高的数据模型,将采集到的离线、实时、平台工具资源进行成本量化及降本支持;一个多维查询服务,支持5v分析视角及3类分析手段,支撑数据管理者、业务负责人、数据开发者等各类角色分析成本、参与降本。至此我们构建完成了有赞数据的全域成本账单。

与此同时,我们实践通过技术运营的手段来进行成本治理,目前来看也取得来一些阶段性的成果。
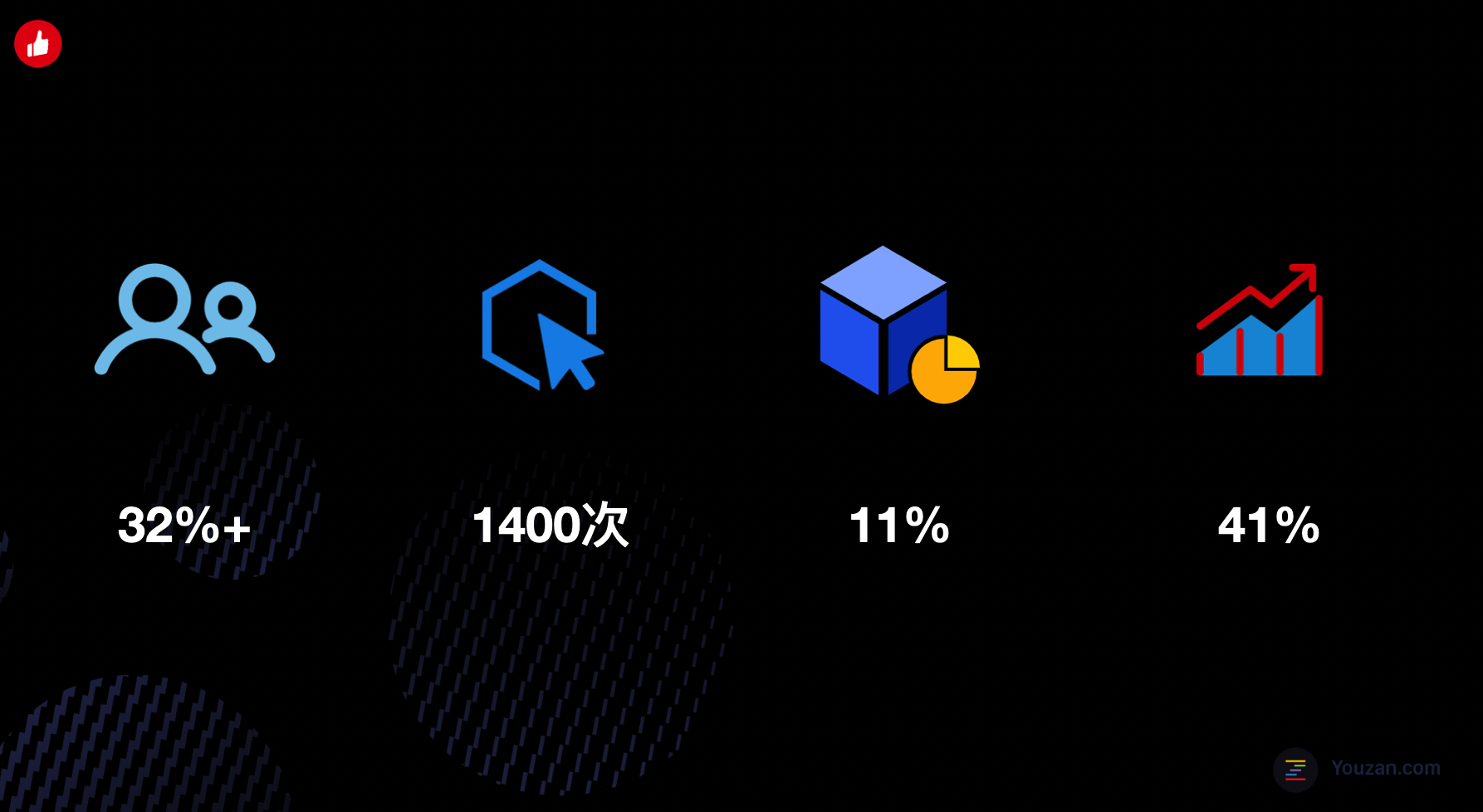
拥有数据成本的同学中有超过32%的用户参与实践了节能降本,累计近1400次降本行为。非数据中台的小伙伴贡献降本比例为10.9%,较上半年提升了41%。
七、后续规划
7.1 成本全资源覆盖
成本账单覆盖了相对稳定的大数据组件,例如 Hbase 、 Flink 、Spark 等。有赞的大数据体系在不断的演进发展中,其他类型的组件也会有序的管理起来。同时我们也将和外部团队沟通协作,希望可以将这套管理模式推广出去,最终将成本管理做大做全。
7.2 成本分析智能化
成本分析目前仍需要用户参与去发现异常的成本信息,我们希望可以更加智能的发现成本异常点并给予个性化的建议,方便用户更加直观、快捷的参与降本。
7.3 持续体系化运营
成本运营乃至技术运营,我们仅刚刚走出了第一步。如何运营的更加体系化?如何将成本运营的经验推广至数据治理的其他方向?这些都是我们接下来需要进行探索的方向。
7.4 降本方向全面化
下半年我们更多的还是在离线侧实践节能降本的工作,针对于实时计算及平台工具所探索的深度不够。降本方向的全面化是未来我们要努力的方向。
最后引用我们团队小伙伴们很喜欢的一句话作为结尾:关注成本,走数据可持续发展道路。

