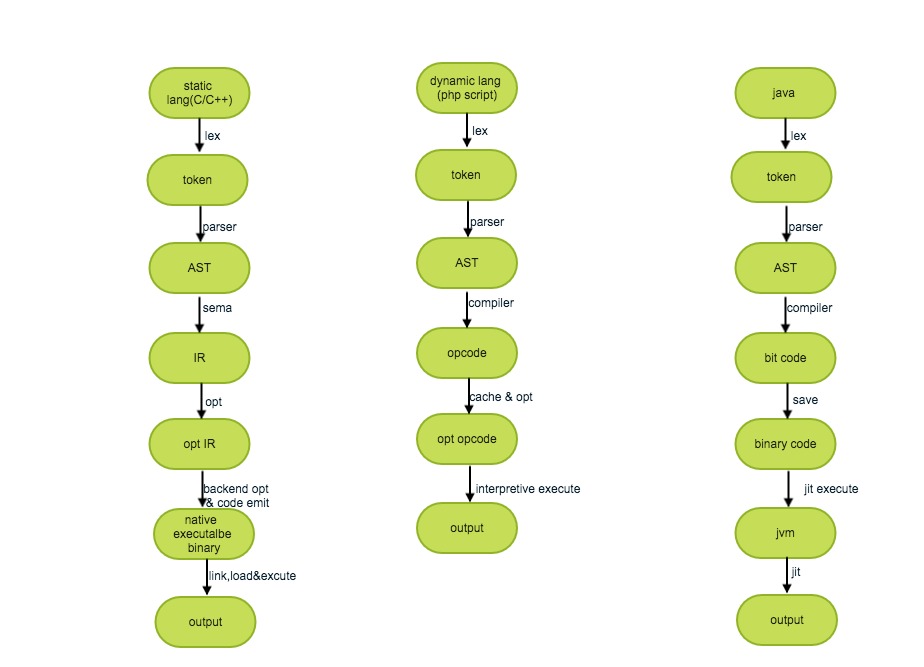
1.概述
PHP(本文所述案例PHP版本均为7.1.3)作为一门动态脚本语言,其在zend虚拟机执行过程为:读入脚本程序字符串,经由词法分析器将其转换为单词符号,接着语法分析器从中发现语法结构后生成抽象语法树,再经静态编译器生成opcode,最后经解释器模拟机器指令来执行每一条opcode。
在上述整个环节中,生成的opcode可以应用编译优化技术如死代码删除、条件常量传播、函数内联等各种优化来精简opcode,达到提高代码的执行性能的目的。
PHP扩展opcache,针对生成的opcode基于共享内存支持了缓存优化。在此基础上又加入了opcode的静态编译优化。这里所述优化通常采用优化器(Optimizer)来管理,编译原理中,一般用优化遍(Opt pass)来描述每一个优化。
整体上说,优化遍分两种:
- 一种是分析pass,是提供数据流、控制流分析信息为转换pass提供辅助信息;
- 一种是转换pass,它会改变生成代码,包括增删指令、改变替换指令、调整指令顺序等,通常每一个pass前后可dump出生成代码的变化。
本文基于编译原理,结合opcache扩展提供的优化器,以PHP编译基本单位op_array、PHP执行最小单位opcode为出发点。介绍编译优化技术在Zend虚拟机中的应用,梳理各个优化遍是如何一步步优化opcode来提高代码执行性能的。最后结合PHP语言虚拟机执行给出几点展望。
2.几个概念说明
1)静态编译/解释执行/即时编译
静态编译(static compilation),也称事前编译(ahead-of-time compilation),简称AOT。即把源代码编译成目标代码,执行时在支持目标代码的平台上运行。
动态编译(dynamic compilation),相对于静态编译而言,指”在运行时进行编译”。通常情况下采用解释器(interpreter)编译执行,它是指一条一条的解释执行源语言。
JIT编译(just-in-time compilation),即即时编译,狭义指某段代码即将第一次被执行时进行编译,而后则不用编译直接执行,它为动态编译的一种特例。
上述三类不同编译执行流程,可大体如下图来描述:
2)数据流/控制流
编译优化需要从程序中获取足够多的信息,这是所有编译优化的根基。
编译器前端产生的结果可以是语法树亦可以是某种低级中间代码。但无论结果什么形式,它对程序做什么、如何做仍然没有提供多少信息。编译器将发现每一个过程内控制流层次结构的任务留给控制流分析,将确定与数据处理有关的全局信息任务留给数据流分析。
控制流 是获取程序控制结构信息的形式化分析方法,它为数据流分析、依赖分析的基础。控制的一个基本模型是控制流图(Control Flow Graph,CFG)。单一过程的控制流分析有使用必经结点找循环、区间分析两种途径。
数据流 从程序代码中收集程序的语义信息,并通过代数的方法在编译时确定变量的定义和使用。数据的一个基本模型是数据流图(Data Flow Graph,DFG)。通常的数据流分析是基于控制树的分析(Control-tree-based data-flow analysis),算法分为区间分析与结构分析两种。
3)op_array
类似于C语言的栈帧(stack frame)概念,即一个运行程序的基本单位(一帧),一般为一次函数调用的基本单位。此处,一个函数或方法、整个PHP脚本文件、传给eval表示PHP代码的字符串都会被编译成一个op_array。
实现上op_array为一个包含程序运行基本单位的所有信息的结构体,当然opcode数组为该结构最为重要的字段,不过除此之外还包含变量类型、注释信息、异常捕获信息、跳转信息等。
4)opcode
解释器执行(ZendVM)过程即是执行一个基本单位op_array内的最小优化opcode,按顺序遍历执行,执行当前opcode,会预取下一条opcode,直到最后一个RETRUN这个特殊的opcode返回退出。
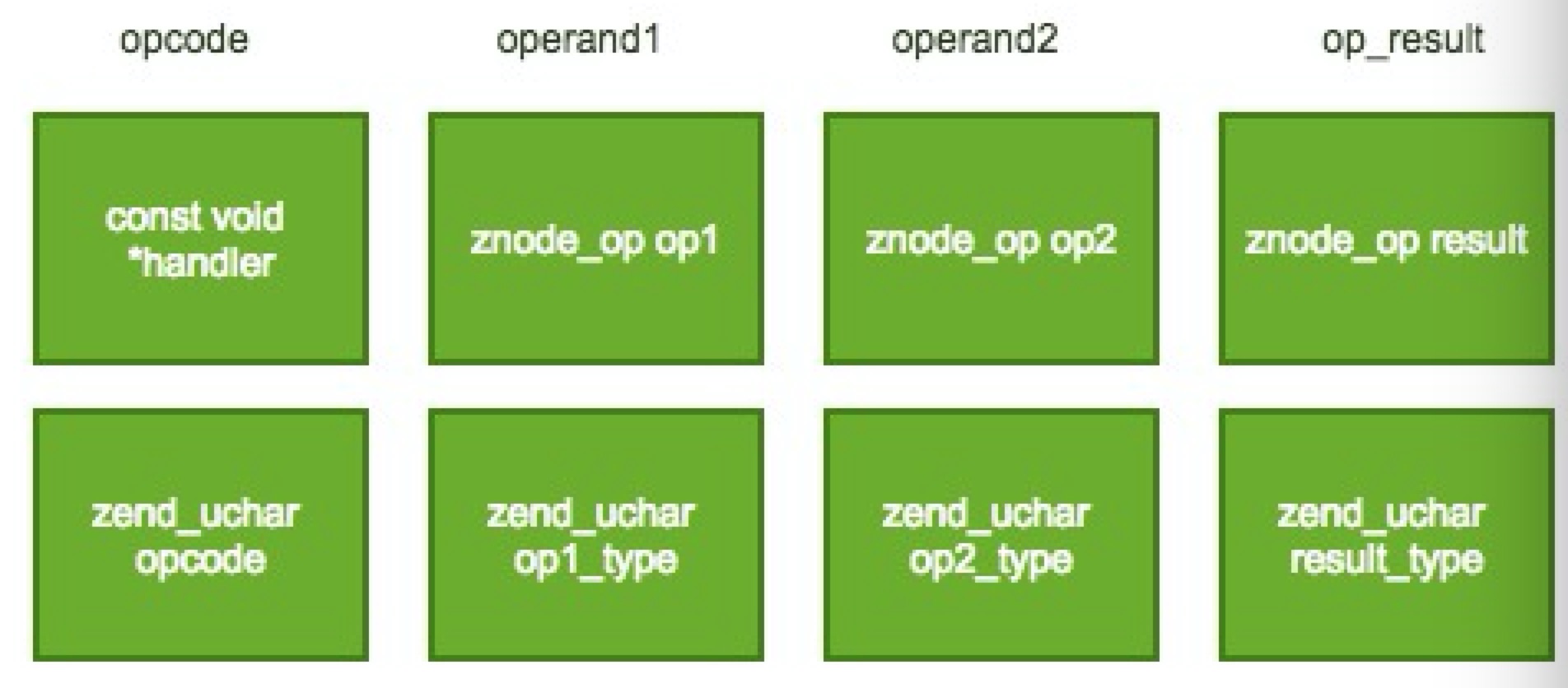
这里的opcode某种程度也类似于静态编译器里的中间表示(类似于LLVM IR),通常也采用三地址码的形式,即包含一个操作符,两个操作数及一个运算结果。其中两个操作数均包含类型信息。此处类型信息有五种,分别为:
- 编译变量(Compiled Variable,简称CV),编译时变量即为php脚本中定义的变量。
- 内部可重用变量(VAR),供ZendVM使用的临时变量,可与其它opcode共用。
- 内部不可重用变量(TMP_VAR),供ZendVM使用的临时变量,不可与其它opcode共用。
- 常量(CONST),只读常量,值不可被更改。
- 无用变量(UNUSED)。由于opcode采用三地址码,不是每一个opcode均有操作数字段,缺省时用该变量补齐字段。
类型信息与操作符一起,供执行器匹配选择特定已编译好的C函数库模板,模拟生成机器指令来执行。
opcode在ZendVM中以zend_op结构体来表征,其主体结构如下:
3.opcache optimizer优化器
PHP脚本经过词法分析、语法分析生成抽象语法树结构后,再经静态编译生成opcode。它作为向不同的虚拟机执行指令的公共平台,依赖不同的虚拟机具体实现(然对于PHP来说,大部分是指ZendVM)。
在虚拟机执行opcode之前,如果对opcode进行优化可得到执行效率更高的代码,pass的作用就是优化opcode,它作用于opcde、处理opcode、分析opcode、寻找优化的机会并修改opcode产生更高执行效率的代码。
1)ZendVM优化器简介
在Zend虚拟机(ZendVM)中,opcache的静态代码优化器即为zend opcode optimization。
为观察优化效果及便于调试,它也提供了优化与调试选项:
- optimizationlevel (opcache.optimizationlevel=0xFFFFFFFF) 优化级别,缺省打开大部分优化遍,用户亦通过传入命令行参数控制关闭
- optdebuglevel (opcache.optdebuglevel=-1) 调试级别,缺省不打开,但提供了各优化前后opcode的变换过程
执行静态优化所需的脚本上下文信息则封装在结构zend_script中,如下:
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //栈帧
HashTable function_table; //函数单位符号表信息
HashTable class_table; //类单位符号表信息
} zend_script;
上述三个内容信息即作为输入参数传递给优化器供其分析优化。当然与通常的PHP扩展类似,它与opcode缓存模块一起(zend_accel)构成了opcache扩展。其在缓存加速器内嵌入了三个内部API:
- zendoptimizerstartup 启动优化器
- zendoptimizescript 优化器实现优化的主逻辑
- zendoptimizershutdown 优化器产生的资源清理
关于opcode缓存,也是opcode非常重要的优化。其基本应用原理是大体如下:
虽然PHP作为动态脚本语言,它并不会直接调用GCC/LLVM这样的整套编译器工具链,也不会调用Javac这样的纯前端编译器。但每次请求执行PHP脚本时,都经历过词法、语法、编译为opcode、VM执行的完整生命周期。
除去执行外的前三个步骤基本就是一个前端编译器的完整过程,然而这个编译过程并不会快。假如反复执行相同的脚本,前三个步骤编译耗时将严重制约运行效率,而每次编译生成的opcode则没有变化。因此可在第一次编译时把opcode缓存到某一个地方,opcache扩展即是将其缓存到共享内存(Java则是保存到文件中),下次执行相同脚本时直接从共享内存中获取opcode,从而省去编译时间。
opcache扩展的opcode 缓存流程大致如下:
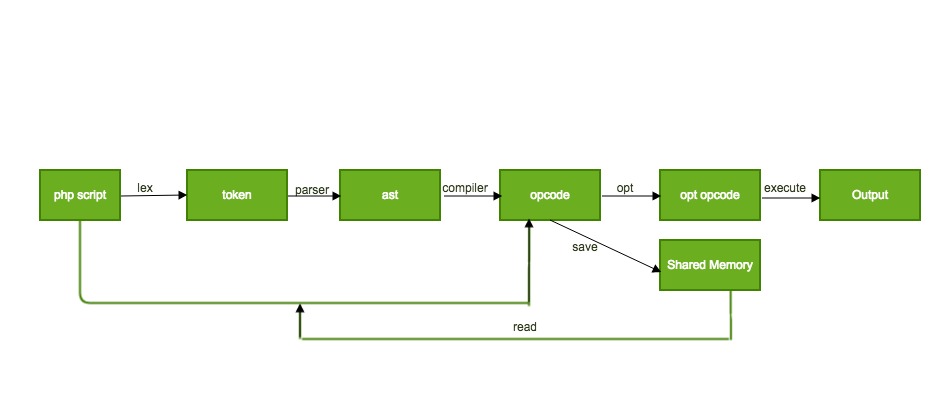 由于本文主要集中讨论静态优化遍,关于缓存优化的具体实现此处不展开。
由于本文主要集中讨论静态优化遍,关于缓存优化的具体实现此处不展开。
2)ZendVM优化器原理
依“鲸书”(《高级编译器设计与实现》)所述,一个优化编译器较为合理的优化遍顺序如下:
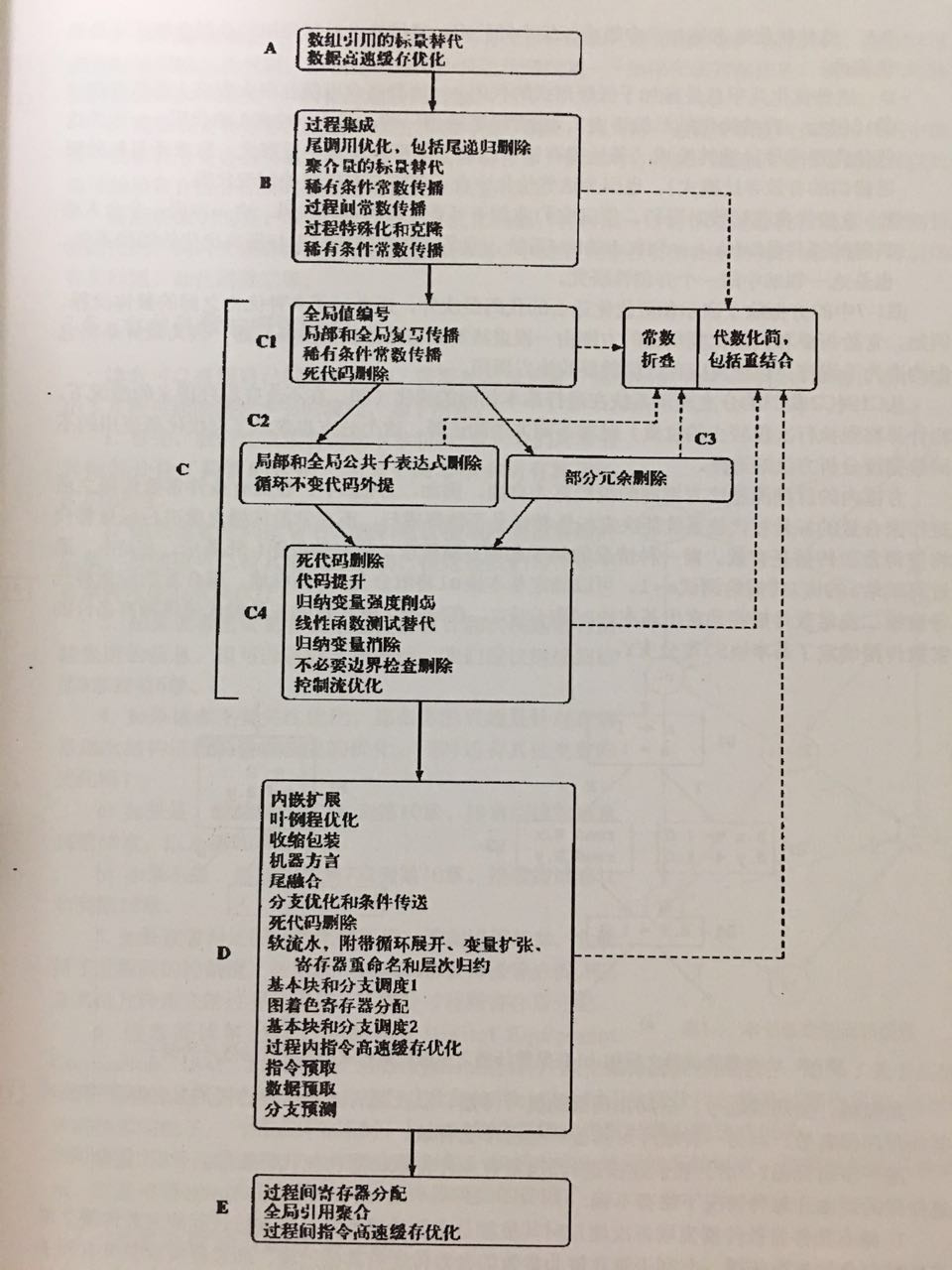
上图中涉及的优化从简单的常量、死代码到循环、分支跳转,从函数调用到过程间优化,从预取、缓存到软流水、寄存器分配,当然也包含数据流、控制流分析。
当然,当前opcode优化器并没有实现上述所有优化遍,而且也没有必要实现机器相关的低层中间表示优化如寄存器分配。
opcache优化器接收到上述脚本参数信息后,找到最小编译单位。以此为基础,根据优化pass宏及其对应的优化级别宏,即可实现对某一个pass的注册控制。
注册的优化中,按一定顺序组织串联各优化,包含常量优化、冗余nop删除、函数调用优化的转换pass,及数据流分析、控制流分析、调用关系分析等分析pass。
zendoptimizescript及实际的优化注册zend_optimize流程如下:
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
实际优化pass,zend_optimize
遍历二元操作符的常量操作数,由编译时转化为运行时(pass2)
|遍历op_array内函数zend_optimize_op_array(op_array, &ctx);
|遍历类内非用户函数zend_optimize_op_array(op_array, &ctx);
(用户函数设static_variables)
|若使用DFA pass & 调用图pass & 构建调用图成功
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
设置函数返回值信息,供SSA数据流分析使用
遍历调用图的op_array,做DFA分析zend_dfa_analyze_op_array
遍历调用图的op_array,做DFA优化zend_dfa_optimize_op_array
若开调试,遍历dump调用图的每一个op_array(优化变换后)
若开栈矫正优化,矫正栈大小adjust_fcall_stack_size_graph
再次遍历调用图内的的所有op_array,
针对DFA pass变换后新产生的常量场景,常量优化pass2再跑一遍
调用图op_array资源清理
|若开栈矫正优化
矫正栈大小main_op_array
遍历矫正栈大小op_array
|清理资源
该部分主要调用了SSA/DFA/CFG这几类用于opcode分析pass,涉及的pass有BB块、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode转换的pass则集中在函数zend_optimize内,如下:
zend_optimize
|op_array类型为ZEND_EVAL_CODE,不做优化
|开debug, 可dump优化前内容
|优化pass1, 常量替换、编译时常量操作变换、简单操作转换
|优化pass2 常量操作转换、条件跳转指令优化
|优化pass3 跳转指令优化、自增转换
|优化pass4 函数调用优化(主要为函数调用优化)
|优化pass5 控制流图(CFG)优化
|构建流图
|计算数据依赖
|划分BB块(basic block,简称BB,数据流分析基本单位)
|BB块内基于数据流分析优化
|BB块间跳转优化
|不可到达BB块删除
|BB块合并
|BB块外变量检查
|重新构建优化后的op_array(基于CFG)
|析构CFG
|优化pass6/7 数据流分析优化
|数据流分析(基于静态单赋值SSA)
|构建SSA
|构建CFG 需要找到对应BB块序号、管理BB块数组、计算BB块后继BB、标记可到达BB块、计算BB块前驱BB
|计算Dominator树
|标识循环是否可简化(主要依赖于循环回边)
|基于phi节点构建完SSA def集、phi节点位置、SSA构造重命名
|计算use-def链
|寻找不当依赖、后继、类型及值范围值推断
|数据流优化 基于SSA信息,一系列BB块内opcode优化
|析构SSA
|优化pass9 临时变量优化
|优化pass10 冗余nop指令删除
|优化pass11 压缩常量表优化
还有其他一些优化遍如下:
优化pass12 矫正栈大小
优化pass15 收集常量信息
优化pass16 函数调用优化,主要是函数内联优化
除此之外,pass 8/13/14可能为预留pass id。由此可看出当前提供给用户选项控制的opcode转换pass有13个。但是这并不计入其依赖的数据流/控制流的分析pass。
3)函数内联pass的实现
通常在函数调用过程中,由于需要进行不同栈帧间切换,因此会有开辟栈空间、保存返回地址、跳转、返回到调用函数、返回值、回收栈空间等一系列函数调用开销。因此对于函数体适当大小情况下,把整个函数体嵌入到调用者(Caller)内部,从而不实际调用被调用者(Callee)是一个提升性能的利器。
由于函数调用与目标机的应用二进制接口(ABI)强相关,静态编译器如GCC/LLVM的函数内联优化基本是在指令生成之前完成。
ZendVM的内联则发生在opcode生成后的FCALL指令的替换优化,pass id为16,其原理大致如下:
| 遍历op_array中的opcode,找到DO_XCALL四个opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| 尝试函数内联
| 优化条件过滤 (每个优化pass通常有较多限制条件,某些场景下
由于缺乏足够信息不能优化或出于代价考虑而排除)
| 方法调用ZEND_INIT_METHOD_CALL,直接返回不内联
| 引用传参,直接返回不内联
| 缺省参数为命名常量,直接返回不内联
| 被调用函数有返回值,添加一条ZEND_QM_ASSIGN赋值opcode
| 被调用函数无返回值,插入一条ZEND_NOP空opcode
| 删除调用被内联函数的call opcode(即当前online的前一条opcode)
如下示例代码,当调用fname()时,使用字符串变量名fname来动态调用函数foo,而没有使用直接调用的方式。此时可通过VLD扩展查看其生成的opcode,或打开opcache调试选项(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
function foo() { }
$fname = 'foo';
开启debug后dump可看出,发生函数调用优化前opcode序列(仅截取片段)为:
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAME
INIT_FCALL_BY_NAME这条opcode执行逻辑较为复杂,当开启激进内联优化后,可将上述指令序列直接合并成一条DO_FCALL string("foo")指令,省去间接调用的开销。这样也恰好与直接调用生成的opcode一致。
4)如何为opcache opt添加一个优化pass
根据以上描述,可见向当前优化器加入一个pass并不会太难,大体步骤如下:
- 先向zend_optimize优化器注册一个pass宏(例如添加pass17),并决定其优化级别。
- 在优化管理器某个优化pass前后调用加入的pass(例如添加一个尾递归优化pass),建议在DFA/SSA分析pass之后添加,因为此时获得的优化信息更多。
- 实现新加入的pass,进行定制代码转换(例如zendoptimizefunc_calls实现一个尾递归优化)。针对当前已有pass,主要添加转换pass,这里一般也可利用SSA/DFA的信息。不同于静态编译优化一般是在贴近于机器相关的低层中间表示优化,这里主要是在opcode层的opcode/operand相应的一些转换。
- 实现pass前,与函数内联类似,通常首先收集优化所需信息,然后排除掉不适用该优化的一些场景(如非真正的尾不递归调用、参数问题无法做优化等)。实现优化后,可dump优化前后生成opcode结构的变化是否优化正确、是否符合预期(如尾递归优化最终的效果是变换函数调用为forloop的形式)。
4.一点思考
以下是对基于动态的PHP脚本程序执行的一些看法,仅供参考。
由于LLVM从前端到后端,从静态编译到jit整个工具链框架的支持,使得许多语言虚拟机都尝试整合。当前PHP7时代的ZendVM官方还没采用,原因之一虚拟机opcode承载着相当复杂的分析工作。相比于静态编译器的机器码每一条指令通常只干一件事情(通常是CPU指令时钟周期),opcode的操作数(operand)由于类型不固定,需要在运行期间做大量的类型检查、转换才能进行运算,这极度影响了执行效率。即使运行时采用jit,以byte code为单位编译,编译出的字节码也会与现有解释器一条一条opcode处理类似,类型需要处理、也不能把zval值直接存在寄存器。
以函数调用为例,比较现有的opcode执行与静态编译成机器码执行的区别,如下图:

类型推断
在不改变现有opcode设计的前提下,加强类型推断能力,进而为opcode的执行提供更多的类型信息,是提高执行性能的可选方法之一。
多层opcode
既然opcode承担如此复杂的分析工作,能否将其分解成多层的opcode归一化中间表示( intermediate representation, IR)。各优化可选择应用哪一层中间表示,传统编译器的中间表示依据所携带信息量、从抽象的高级语言到贴近机器码,分成高级中间表示(HIR) 、中级中间表示(MIR)、低级中间表示(LIR)。
pass管理
关于opcode的优化pass管理,如前文鲸书图所述,应该尚有改进空间。虽然当前分析依赖的有数据流/控制流分析,但仍缺少诸如过程间的分析优化,pass管理如运行顺序、运行次数、注册管理、复杂pass分析的信息dump等相对于llvm等成熟框架仍有较大差距。
JIT
ZendVM实现大量的zval值、类型转换等操作,这些可借助LLVM编译成机器码用于运行时,但代价是编译时间极速膨胀。当然也可采用libjit。
