Original NSQ
NSQ is a realtime distributed MQ platform written in Golang. NSQ is composed of three main parts: nsqd as a messages storage service, nsqlookupd as a topology collect and query service, nsqadmin as a web UI to watch the cluster in realtime.
In nsqd, data flow is modeled as a tree of streams and consumers. A topic is a distinct stream of data. A channel is a logical grouping of consumers subscribed to a given topic. In original nsqd all messages are in Golang channel if not overflow and every consume channel receives a copy of all the messages for the topic.
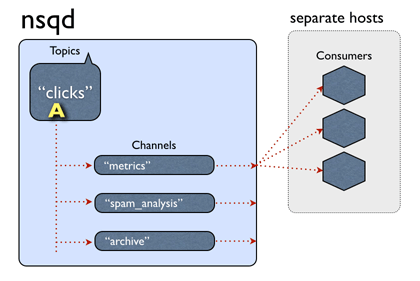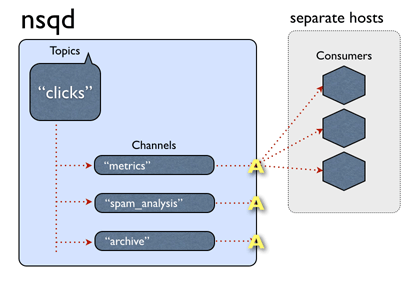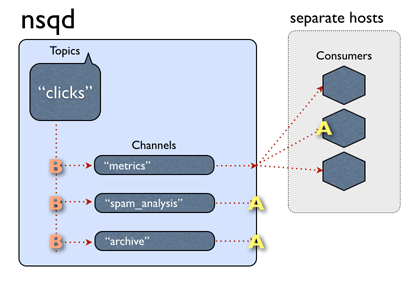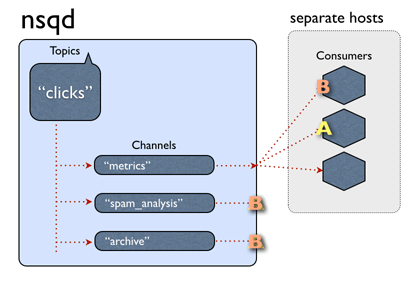
The original NSQ supports distributed topologies with no SPOF and can easily scale out. It provides a simple TCP protocol talking between client and server and the client libraries are available in many languages such as Java, PHP, Golang and so on.
Why we need to redesign it
Due to the simpleness and the features of NSQ, we used it as our main MQ system for a while without any issue. However, with the increasing services we found we can not satisfy several new demands without redesigning it. Some demands are so common in MQ system and we think maybe other NSQ users need them too, so we decided to redesign the NSQ so that others can benefit from our works. And for ourselves we can reduce the migration work a lot.
Not Easy To Deploy
The original NSQ promotes a consumer side discovery model that alleviates the upfront configuration burden, so we do not have to tell consumers in configuration where to find the topics they need.
However, it does not provide any means to solve the problem of where a service should publish to. By co-locating nsqd, we solve the problem partially. With the increasing services it is hardly to deploy co-locating nsqd for every service. So we need a coordinator to balance all the topics while creating them and tell all the services which nsqd they should publish to.
Lost on exception
The original NSQ stores the messages using the Golang channel which is in memory and only persists messages while overflow. This is good in some situations but may cause the data lost if we get exceptions that cause the process crashed or even worse we encounter unexpected machine shutdown.
Hard to trace the message status
Since in original NSQ the messages are kept in memory mostly, and will be cleaned after consumed, we can not find out whether a message has ever reached into the NSQ. Also the consume status of a message is completed unknown(inflight or timeout or finished).
Hard to consume history messages
There are some cases we need re-process some history messages so we can fix errors after upgrade the message handler. In original NSQ it is not possible to do this since it just handle messages in memory and do not persist all the history messages to disk. To consume history we need retain messages with a configured time window after they are consumed.
Hard to receive messages in order
In some situations, we need make sure all the messages are transferred in order from one system to another to make two system eventually consistence even there are some exceptions (network failure or crash). To achieve this, persistence of the messages is a prerequisite, and beyond that we need make sure both producers and consumers are under our control.
Hard to debug online
In the original NSQ the logs are too few to be debugged and the log level can not be adjusted dynamically. Dynamic log level is a very useful feature to debug problems without affecting the online system.
The redesign road
Because of the above reasons, we decided to redesign the NSQ. What is important is we have to try our best to make it compatible with original NSQ. Only in this way we can migrate to the new system more smoothly. A notable modification is the internal ID of the message. In original NSQ it is 16-byte hex string, we changed it to 16-byte binary string. We changed this because we noticed that client SDK just use the id as 16-byte data and it is not a problem while migrating.
Another change we need to make is to persist all messages to disk. Most of the missing features were due to the use of the Golang channel as the memory storage for messages. This change is not easy since it will impact the performance. We did many efforts to make sure the least impaction on performance. It turns out that we got a good result since we can achieve a better performance than the original NSQ after we redesigned. We achieved this by optimizing many performance bottlenecks in both the original NSQ and the redesigned one.
Since all messages go to disk, we can implement the trace and consume history much easier. We use only a cursor to stand for the consume channel and in this way we avoid the copy overhead from topic to all channels.
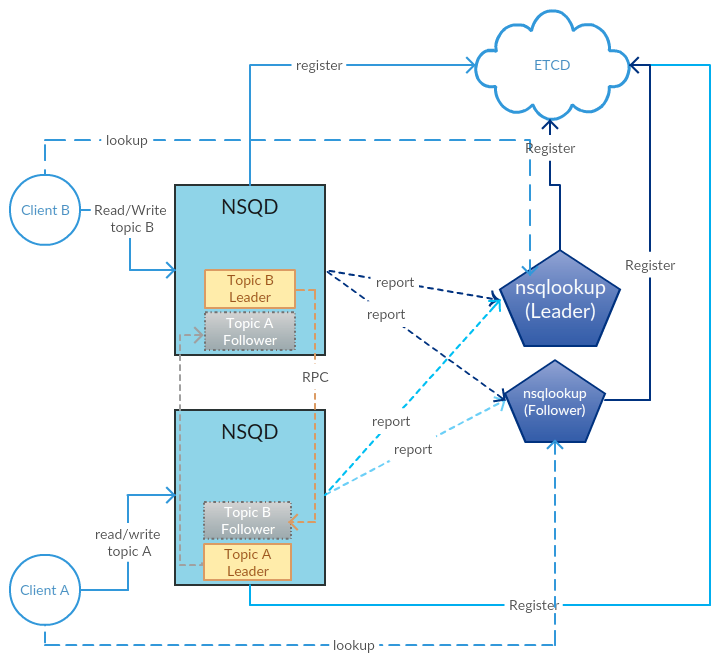
To implement replication and HA, we introduced the etcd as the meta storage and the cluster coordinator on both nsqd and nsqlookupd side. Most of the cluster related codes are outside of the topic so we can easily merge our work into the mainline in future.
We did so many changes to the original NSQ, so we need make sure it will work. Thanks to the unit tests in the NSQ, we can reuse most of them and we add more tests to make sure everything is ok. For distributed system, we introduced Jepsen test to make sure no any unexpected data lost while in terrible network environment.
Summary
Putting all the works together we got the architecture overview below:
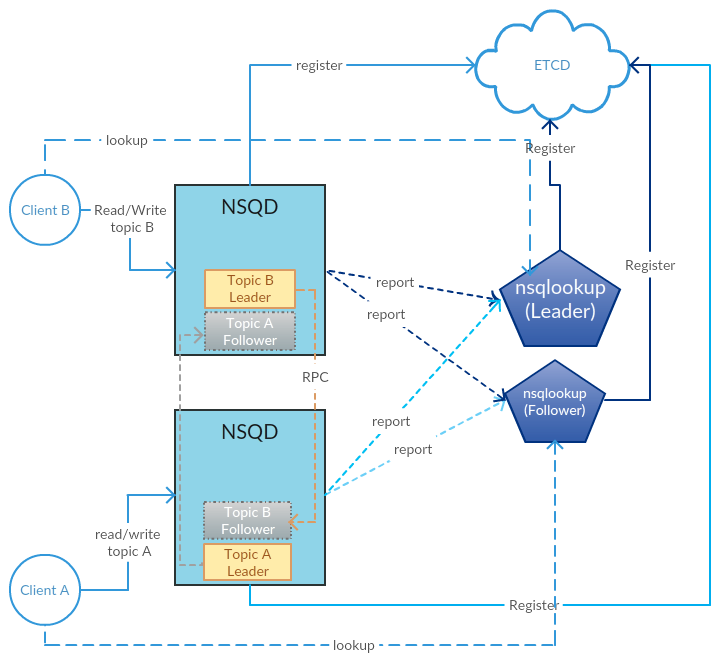 We will disclose the technical details about all these new features in future articles and open source all these works on Github.
We will disclose the technical details about all these new features in future articles and open source all these works on Github.
Thanks to the original contributors of NSQ, without them it will have many more extra works to build a MQ system from the ground up. If you like our works, you can star it on Github and join as contributors which will be great appreciated.
