
前言
有赞发展初期,随着公司业务的增长,原本许多单机上定时执行的 crontab 任务越来越多,配置的维护成本变高,运行结果不能可视化,管理不统一,存在单点风险,运维和监控空白等等诸多弊端的显现,促使了第一代定时调度系统 Watchman 1.0 的诞生。Watchman 是一款集中式定时任务调度系统,根据业务提供的任务服务信息,参数和 cron 表达式,周期性发起回调。支持 Agent(脚本执行器),HTTP,Dubbo 三种类型的任务回调方式。
随着时间的继续推移,业务需求的沉淀;从交易团队诞生出了一款延时任务产品 TOC (timeout center),TOC 最初聚焦解决的问题是:订单超时关单,订单自动完成,退款提醒,订单补偿重试等场景,后面由于业务需求的扩大,逐渐下沉到中间件团队维护迭代。
TSP 的诞生
由于 Watchman 和 TOC 在架构上有类似的地方, 都是为了满足业务方在指定的时间按照一定的策略回调业务代码的能力。同时,我们也发现有部分业务为了满足一些定制化需求,自己也实现了一部分的任务调度功能。比如框架组提供了异步执行引擎(Poseidon);零售团队实现了一个基于 Watchman 引擎的导入、导出、异步耗时任务框架。这几个零散的产品都是业务因为 TOC 和 Watchman 无法直接满足业务的定制功能而做的额外的功能开发。目前分散在几个团队,不好管理,也存在一些通用功能的重复开发工作。为了将各种任务调度类型的产品整合起来,并且具备业务扩展能力,诞生了 TSP(Task Schedule Platform) 这样一个任务调度平台。
TSP 设计与实现
TSP 主要集成了 TOC 和 Watchman 两种任务调度产品,兼具定时调度(根据cron表达式调度) 和 延时触发(根据用户提交任务的执行时间去调度)的能力。为了统一任务流转的处理流程,TSP 承袭了 TOC 的系统组件分类,主要分为 tsp-client、console、tsp-web、tsp-fetcher 和 tsp-worker 5个部分。
任务相关元数据
- Task: 基本任务单元,一个 Task 代表系统会对业务方发起一次调用,延时任务中用户通过接口提交 ,定时任务是 TSP 周期性生成。
- TaskConfig: 任务配置,用来隔离业务,记录 Task 的回调服务的信息,调度策略等; 一个 TaskConfig 对应有一个 Task 集合;用户可通过 console 界面申请 或 API 方式创建。
TSP架构图
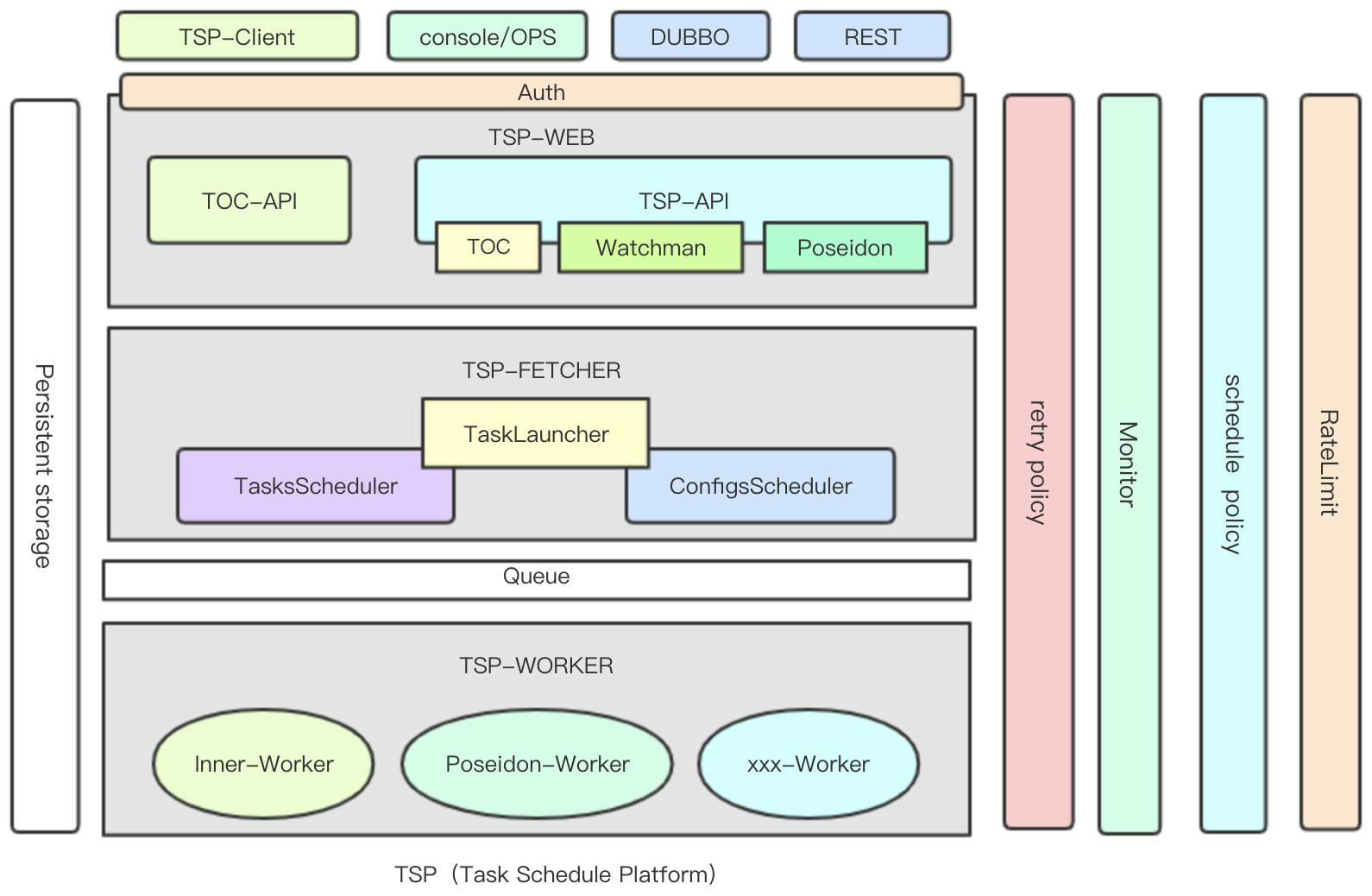
下面将逐个介绍一下几个主要模块(tsp-web、tsp-fetcher、tsp-worker)在 TSP 整个系统中的职责和作用:
tsp-web
整合原有各个产品的管理端能力和系统 API 能力;添加 Task 时若已存在,支持指定处理逻辑(重置执行时间/ignore/添加一个新任务)
- 任务的配置管理(配置创建,修改,状态启用/停用,配置删除)
- 任务管理(创建,暂停/恢复/取消/推迟 等)
- admin 管理 API
- 监控数据 API
- API 权限验证
tsp-fetcher
负责任务到期调度功能,提供按配置(TaskConfig)维度的调度线程池和任务队列隔离调度能力。将到期待执行的任务捞取到任务队列;目前队列由我们的 MQ 产品: NSQ 充当。熟悉 TOC 架构的小伙伴可能会发现该部分去除了 TOC 中引入的 SpringBatch 组件,自己实现相关部分的线程模型,变得更加轻量化。
- ConfigsScheduler:Config 型任务的调度(根据配置驱动的调度)如 定时任务。
- TasksScheduler:Task 型任务的调度,根据业务提交的任务执行时间驱动的调度, 如 延时任务,异步重试任务。
- 回调失败的任务的重新调度。
- 任务调度限流:根据
TaskConfig配置的每个周期调度的最大限流值进行限流调度。
tsp-worker
消费任务队列,执行相应的任务回调,更新任务状态
- 内置两种回调处理器(DubboTaskHandler 和 RestTaskHandler)分别处理 Dubbo 回调 与 HTTP 回调
- Dubbo 回调是通过异步泛化调用实现,支持接口方法自定义 POJO(Plain Ordinary Java Object) 参数的设定。
- 任务失败重试,任务回调监控等。
其他模块
- tsp-client: 主要封装了对 tsp-web 的任务操作(添加、修改),便于业务方直接使用
- console: 用于对任务和配置的元数据进行管理和查看,目前这块职责都集成到了内部统一运维平台进行管理
- RateLimit(包含调度限流和任务API限流)、Schedule Policy(任务回调的策略)、Monitor(任务监控和告警) 和 retry Policy(失败/超时的重试策略) 等将会在后续的功能特性文章中进一步详细总结
数据存储和任务扫描
TSP 的任务存储由两部分组成:DB 和 MQ。
- DB 存储任务(Task)和配置(TaskConfig)元数据,任务表建立
configName + status + executeTime联合索引,任务到期扫描configName维度status = 0 & executeTime <= now()的数据,任务状态的流转下文会提到。 - 到期任务扫描之后,将满足条件的任务投递到待执行队列(MQ)中,让任务回调组件
tsp-worker消费,对业务发起异步 RPC 或 HTTP 回调,更新任务的最终状态。
那么,这样的任务扫描如何支撑较大任务量的提交呢?我们针对不同任务量的 TaskConfig 做了相应的任务隔离存储和调度,详情可参看后文的 任务调度隔离。
TSP的任务状态流转
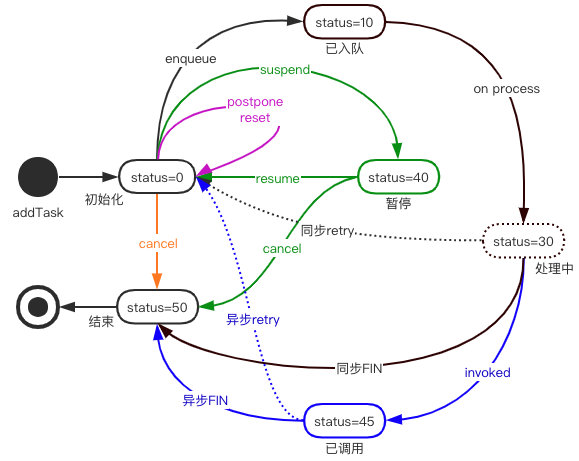
图中不同的颜色代表不同类型的操作。一个任务周期的开始 status=0;任务进入执行队列 status=10;任务执行中 status=30;任务暂停 status=40;任务已发起异步调用 status=45;任务周期的结束 status=50。需要注意的是 status=30 目前仅是虚拟的一个任务状态,是在内存中的处理状态,由于变化很快,没有持久化,仅代表一个任务消费回调的过程。
一些需求场景下的功能实现
场景1
如何满足特殊的任务回调逻辑?
需求来源是我们要整合另一个任务调度产品: 异步重试任务框架 Poseidon。它的需求是需要任务在执行完成后通知任务提交方任务已完成;任务提交方据此再做一些确认逻辑。
稍微抽象一下:这个功能主要针对于业务方需要在任务回调完后做些别的事情;比如:通知一下任务提交方,该任务的完成状态(失败/成功/进入延时重试),甚至于根据完成状态做一些其他私有的业务逻辑。所以我们需要有可定制实现逻辑的任务回调骨架。同时 TSP 在支持自定义开发 worker 的基础上,可以让业务和中间件一起来共建场景,一起沉淀新的使用姿势。
功能实现
TSP 通过抽象一个 worker 的骨架模块tsp-consumer-core,内部依赖这个模块,实现TaskHandler类,业务就可以自定义出一个tsp-worker,实现自己的任务消费逻辑。UML设计如下:
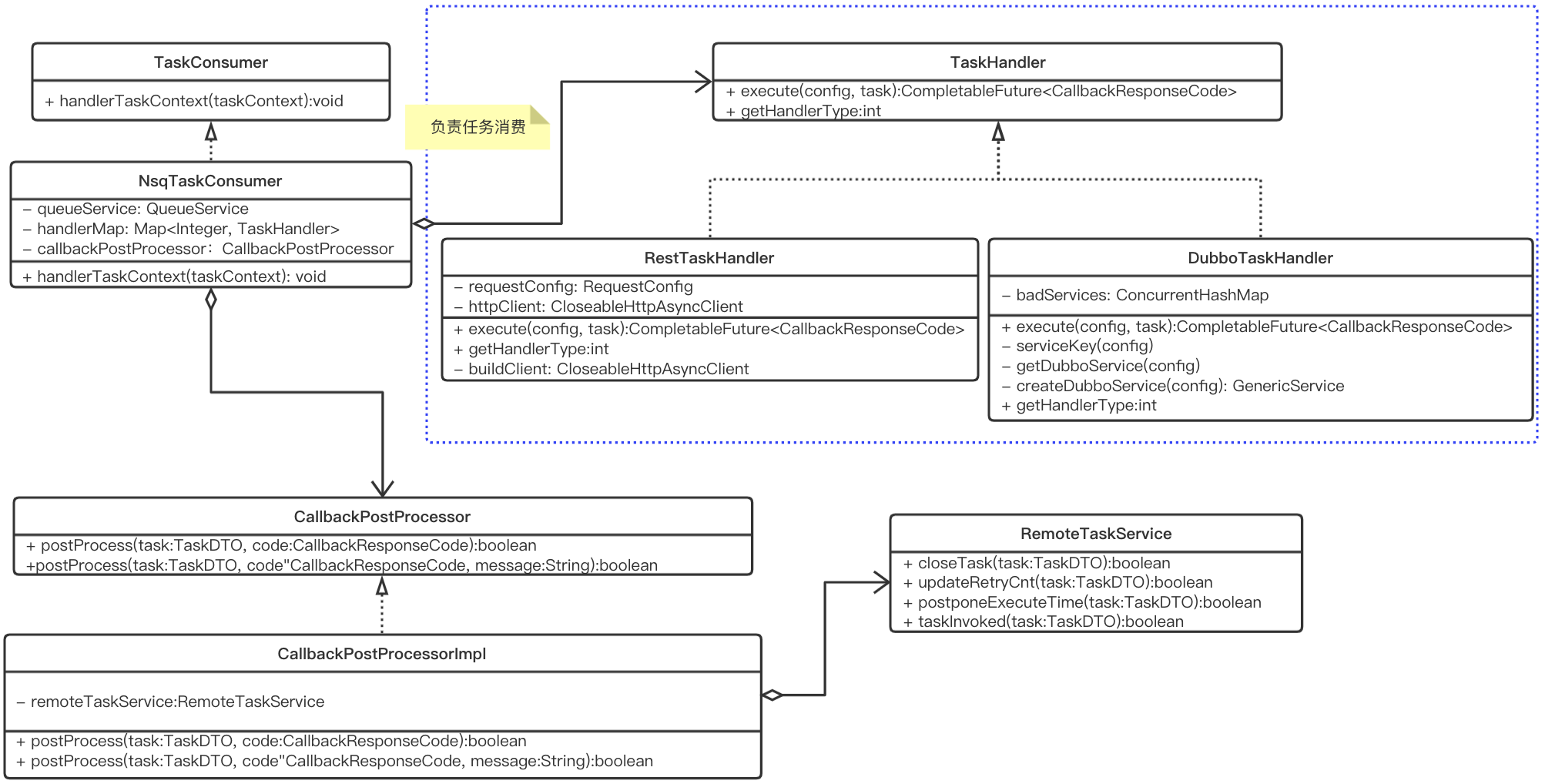
- TaskConsumer: 消费待执行任务队列,将任务交给
TaskHandler执行。 - TaskHandler: 用户通过实现该类进行消费逻辑定制化,实现它的
execute方法,自定义消费逻辑。 - CallbackPostProcessor: 消费完成后的逻辑处理类,主要是通过
RemoteTaskService将任务状态回写到 TSP,内部的DefaultTaskServiceImpl实现是直接修改 DB 的任务状态;外部扩展的 worker 则是通过远程调用的方式(目前有 Http 和 Dubbo 两种可选方式)更新任务状态。
场景2
不同任务配置的调度如何相互隔离?
一般的,不同的应用有着不一样的业务等级和重要程度。业务等级高的应用当然不希望因为业务等级低的应用有大量任务的回调而导致它本身的回调被延迟。其实任何一个业务方都不希望自身的任务回调被其他业务所影响。基于此,我们对不同 TaskConfig 提供了可配置的调度隔离和执行隔离能力。
功能实现
任务调度隔离分为三个方面:
- 在 apollo 配置中心维护一份基于配置分组维度的规则(rules),为不同的分组分配单独的调度器
TaskLauncher - 基于 TaskConfig 维度设置任务的调度队列(queueName) ,对任务量大的 TaskConfig 的任务队列进行隔离,任务量少的 TaskConfig 则可以共用一个调度队列。
- 任务(Task) 根据 TaskConfig 的分片键: sharding 进行分表存储,减轻单表索引扫描压力。
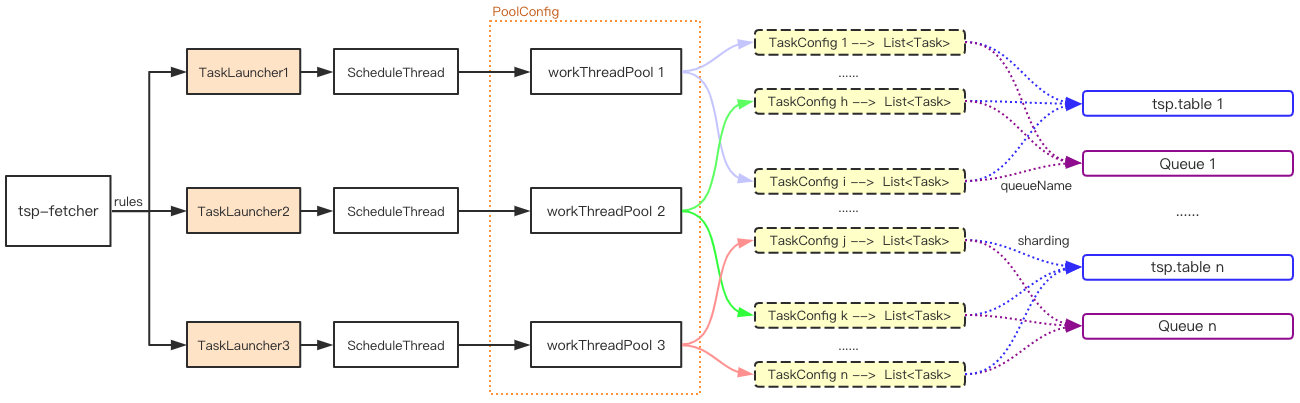
这种方式一定程度上减轻了单棵索引树的量级,单表可以在几亿数据行上表现出良好的扫描能力,这里用好 MySQL 索引也是关键的一环,延迟关联+标签法是较大索引树扫描优化的常用手段,但针对于特大量级的任务配置就需要进一步分表或者分库的方式去组织存储了,另外还可以将执行完毕的任务归档存储,进一步提高待执行任务表索引的效率。关于任务调度的隔离,后续我们会继续演化到不同集群(按存储隔离)的维度。
场景3
是否支持像 ElasticJob 一样的 sharding 功能?
需求来源是某些之前一直使用 ElasticJob 的业务组提出的,他们的任务都有一些共同特点:定期调度,任务每次执行的任务量非常大,执行耗时,单机的计算资源不足以完成。如:一个定期计算1000W用户画像的任务,如果可以拆分成500个分片任务,每个分片可以触发执行2万个用户的计算任务,分布到50台机器上执行。为了统一整个公司的任务调度组件的维护,TSP 也需要有支持这类功能或可替代的方案。
功能实现
TSP 本身和 ElasticJob 是两种不同类别的任务调度系统,TSP 是集中式调度执行,ElasticJob 是分散式调度执行。业务通过给每台机器分配的 sharding 值来决定该机器需要执行的任务范围。所以我们在 TaskConfig 中增加了shardingCnt的属性,用于指定在每个周期生成该 TaskConfig 下的任务的个数,每个任务都携带一个shardingId(取值 [0, shardingCnt) )。而至于任务分配的平均性,目前是由任务回调时,通过设置 Dubbo 服务的负载均衡策略或 HTTP 对应服务的 Nginx 配置来达成的。每个任务分片的请求上下文带有任务分片ID(shardingId)和任务分片总数(shardingCnt)。方便用户根据这两个值计算和执行业务处理逻辑;以此来变相的满足业务需求。
场景4
业务本身能承载的 QPS 很低,突发大量回调怎么办?
延时任务的场景下,业务是通过 TSP 的接口来提交任务的;TSP 通过任务中的 executeTime 进行到期回调。如果业务并不知道他提交到未来某个时间点要执行的任务数量已经大大超过了它本身业务处理能达到的 QPS 能力,那么届时的高并发回调对业务来说将是一个灾难性的打击。
功能实现
为了能保证在回调业务的过程中,业务服务能够正常对外提供能力,我们目前简单设计了一个基于 TaskConfig 维度的调度限流,业务方可以根据压测数据,通过 console 配置每个回调周期最大的回调任务数: taskPerLoop;即每一个调度周期,每个 TaskConfig 最多触发 taskPerLoop 个任务回调,超过数量会被延迟到下一个调度周期再行调度,对被限流调度的配置后续还需要完善通知触达业务方。还可以通过回调组件 tsp-worker 对业务的回调 RT 反馈来动态调整限流值,以应对那些配置的限流值不准确或者突发的不稳定情况。
Roadmap
更全面的任务监控
收集任务从添加,修改(暂停/恢复/延后/取消),调度到回调结束,甚至失败重试的整个链路的监控数据,为用户提供任务执行流程,任务看板,甚至未来几小时内的任务执行预告,任务回调高峰预报等功能。
任务编排
根据FaaS的理念,我们可以理解各个业务服务就是各种不同场景的 function 集合,TSP 可以基于服务注册与发现机制,来组合用户权限之内的这些function,以支持更加复杂的任务定制化流程。各个业务在 TSP 登记的服务也可以自定义可见度,类比于 Java 中的 public,protected,private 关键字来决定一个 TSP 配置(对应于对一个function的调用)的可见域。
在任务编排功能上,我们甚至可以实现一些简单的工作流的事情,并且可以配置每个流程向下一个流程推进的条件,让这个执行流程更加稳定可靠。举个不太恰当的栗子:组合订单查询、用户信息查询、物流信息查询、报表导出等功能,可以定期自动产出一份订单报表(先不考虑这个栗子的实用性)。
集群化
根据不同的用户群,或者用户任务的规模,将 TSP 分成若干个集群(交易集群,物流集群,用户中心集群,公共集群...),将存储和调度进一步隔离。
事务消息
事务消息中,业务在执行事务前提交一个延时回调任务,到期回调时,业务可以根据事务是否处理完/是否失败,决定任务是否稍后重试或立即结束。处理完成,TSP 则向 MQ 发一条事件消息,供下游系统确认并进行后续逻辑处理。
任务动态注册
这个功能是在集中式任务调度管理之外,向分散式任务注册的探索。主要针对于定时任务:任务在业务服务启动后动态注册到 TSP,服务下线之后自动失效。避免业务应用下线或者服务宕机之后,因为配置未禁用而继续尝试回调。
总结
本文从整体上介绍了有赞调度系统 TSP 产生的背景以及解决的问题,同时重点介绍了涉及的主要模块的细节设计,最后对一些未来计划进行了介绍,展望了部分计划中的特性;TSP 是有赞调度系统的历史沉淀,后续会在此基础上不断迭代和完善,总结更多新的特性和改造点,希望感兴趣的朋友可以多多交流。
