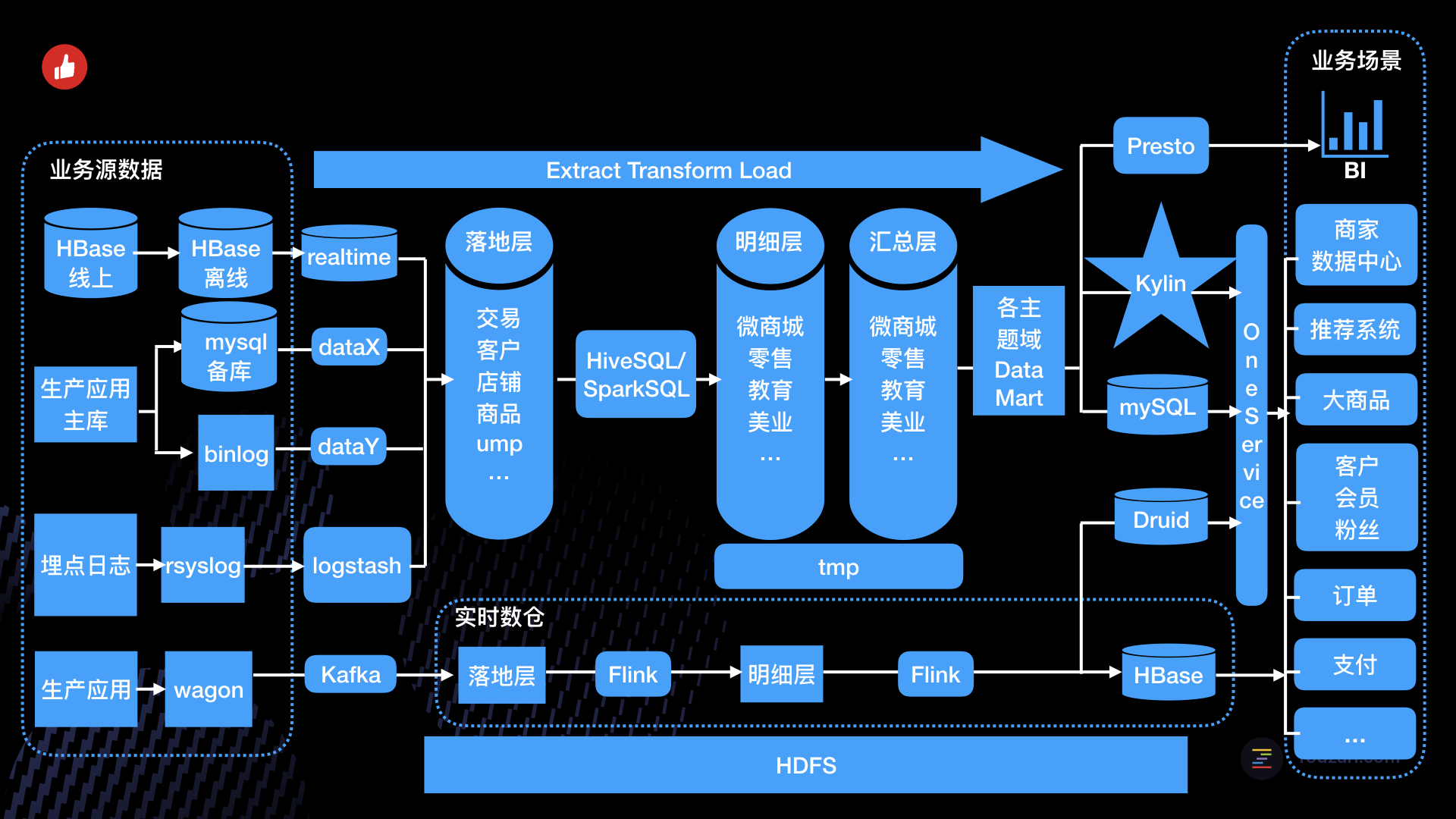
一、大数据环境下的有赞数仓
关于数据仓库,在维基百科中将它定义为用于报表和数据分析的系统,是商务智能 Business Intelligence 的核心部分。在数据仓库诞生之初,它只被设计成面向管理层所需要的决策支持系统,并不对业务方(这里指各应用系统)提供数据支持。
然而在大数据环境的背景下,当 Hadoop 生态已然成为大数据现实意义上的载体,以 Hive 为基础的数据仓库已经不能仅仅只提供决策支持的需求了——它需要同时满足某些业务上对数据的统计需求。
因此,当下的数据仓库应该有一个新的定义:大数据环境下的数据仓库是指对全局数据(包含时间和空间:历史的以及所有业务部门的)的存储及使用的一整套方法论。
有赞的数据仓库就是在这样一个大数据环境下,同时需要满足内部分析数据和商家侧数据的各类需求。
二、发展历程
有赞的数据仓库经历了混沌期、建设期,目前在成熟期中蜕变着……
2.1 混沌期
2.1.1 背景
在有赞大数据的初期,严格来说是没有数仓概念的:没有分层,没有主题域,也没有规范。
当整个 Hive 里就只有一个 st 库,并且不做规范性命名的时候,便会出现两个同名的 mysql 表先后导入同一个库,后者把前者的表结构和数据都覆盖了。
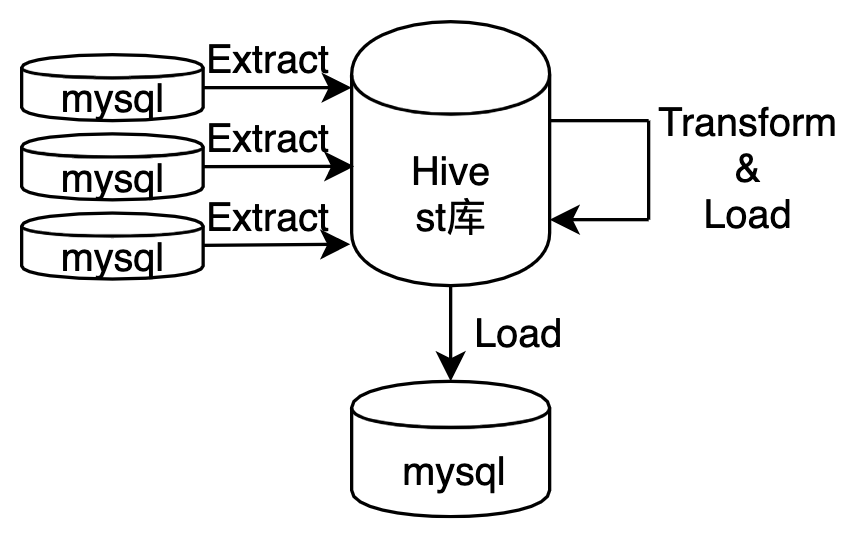
没有 ETL 工具,没有工作流的概念(或者说所有任务就是一个工作流),没有调度平台,当然更不会有数据字典和血缘关系了。
所有的数据处理任务都是用 python 写的,SQL 自然也就都作为字符串写在 python 文件里了。在一个大 python 项目里,任务之间的依赖关系,则是维护在一个配置文件里的。
2.1.2 痛点
可以说在缺乏方法论的混沌期,数仓在稳定性和可用性方面都是存在问题的。
业务方单方面修改了表结构,我们凌晨收到告警;业务方修改枚举值未通知到位,我们凌晨收到告警;集群资源分配不合理,我们凌晨也会收到告警……频繁的凌晨告警、延迟的数据产出、不准确的数据结果、分析人员对数据的吐槽……各类问题交织着,令我们焦头烂额。
2.1.3 Action
随着有赞业务的快速发展,这种烟囱式的开发模式已经支撑不了每天增长的各式各样的数据需求了。
尽管没有用 Informatica 这类商业化的 ETL 工具,但是调度 scheduler 和监控 monitor 的能力却是数据仓库任务必不可少的。于是,在2016年的最后一个季度,有赞开始了基于 airflow 二次开发的数据平台建设,随之也开启了数据仓库的规范之路。
2.2 建设期
2017年初,有赞正式踏上了数据仓库规范之路。伴随着有赞大数据开发平台的内测,数据仓库首当其冲成为新平台第一个吃螃蟹的人。
2017年6月,我们开始将之前由一堆 Python 文件维护的数据任务开始往大数据平台迁移。迁移持续到了2017年8月,而数据仓库的规范直到今天还在演进……
数据仓库规范首先要考虑的是分层问题以及随之而来的主题域划分。伴随着数据仓库的不断建设,数据权限、数据字典,任务资源分配等需求都浮出水面。
2.2.1 数仓的分层
分层是为了解决 ETL 任务及工作流的组织、数据的流向、读写权限的控制、不同需求的满足等各类问题。
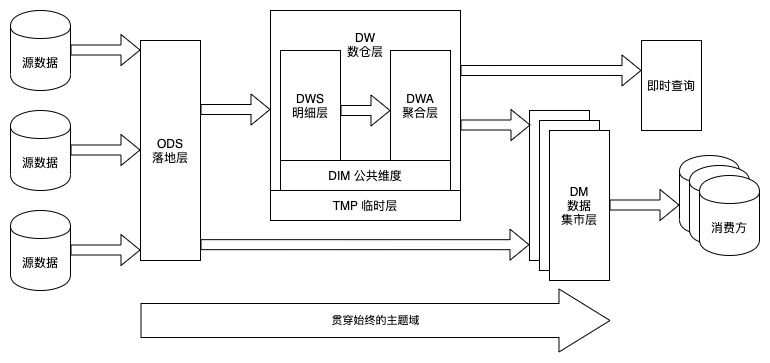
总体来说,我们将数仓划分为了数据落地层、数据仓库层和数据集市层三部分。作为历史遗迹的 st 层,在迁移过程中被保留了下来——有太多杂乱的任务无法清除,最终在2017年底,被快刀斩乱麻式的一刀切掉了。
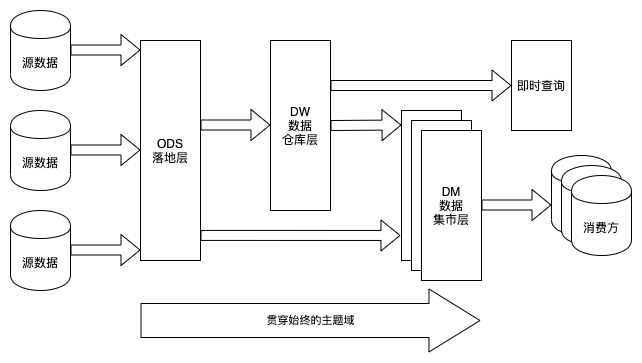
(1)ODS 落地层
落地层 (Staging Area) 最初是作为介于业务源数据和数据仓库 ETL 之间的缓冲区而存在的。在 Hive 里它表现为一个独立的库,所有来自业务方的表都会先落到这个库里。
有赞的 ODS 落地层解决了两个问题:1)导表的冲突,2)落后的数据仓库中间层建设和日益增长的业务需求之间的矛盾。
导表的冲突
由于数据源有各种各样的库,源表表名重复是很正常的情况。因此我们需要给每个表加上主题域前缀,从而避免来自不同主题域的同名表之间的冲突。当同一主题域下出现同名表时,我们辅以额外的表后缀来区分。
落地层解决了统一导表的落地问题,也承担着全局 ETL 中的第一轮 Extract。我们的原则是使落地层里的数据和业务数据保持一致,这也是为了方便将来数据问题的排查与核对。
数仓建设和业务需求之间的矛盾
当时我们的人力完全无法满足众多需求方对数据的需求——数据中间层的建设赶不上飞速奔跑的业务需求。于是,一个折中的方法是让业务方直接使用落地层,自行处理一些不跨主题域的需求。
这里有业务方非常熟悉的原始表,他们能非常迅速地获得所需要的数据。这也有利于快速、低成本地进行一些数据方面的探索和尝试。
(2)DW 数仓层
数据仓库层在 Kimball 的数据仓库架构中应该映射的是数据展现层 (Presentation Area),它承载了最复杂的 ETL 逻辑和建模,也是维度建模集中体现的一层。
分层的误区
Kimball 并没有对它做更细的层级划分。我们则依样画葫芦,根据当时业界较为通行的做法将整个数仓层又划分成了 dwd、dwb 和 dws 三层。然而我们却始终说不清楚这三层之间清晰的界限是什么,或者说我们能说清楚它们之间的界限,复杂的业务场景却令我们无法真正落地执行。
由于缺乏维度层,我们的维表显得无处安放;由于缺乏临时层,我们的中间结果和对外发布的表混在了一起。最终,三级分层只完成了我们的数据流向规范——从 dwd 到 dwb 再到 dws,层级之间不可逆向依赖。
宽表的误区
带着大数据环境下维度建模是否依然适用的疑惑,我们和许多人一样,在数仓层开始引入了宽表。所谓宽表,迄今为止并没有一个明确的定义。通常做法是把很多的维度关联到事实表中,形成一张既包含了大量维度又包含了相关事实的表。
宽表的使用,有其一定的便利性。使用方不需要再去考虑跟维度表的关联,也不需要了解维度表和事实表是什么东西。
但是随着业务的增长,我们始终无法预见性地设计和定义宽表究竟该冗余多少维度,也无法清晰地定义出宽表冗余维度的底线在哪里。
一个可能存在的情况是,为了满足使用上的需求,要不断地将维表中已经存在的列增加到宽表中。这直接导致了宽表的表结构频繁发生变动。
(3)DM 数据集市层
数据集市层 (Data Mart) 根据主题域的不同在物理上进行划分——它表现为多个相互独立的库,各个数据集市之间不允许做数据依赖。每个数据集市可以由该主题域的使用方在数据仓库规范下自行开发和建设。
这一层可以根据使用习惯,建立一些宽表。但是如果要配合 Kylin 使用的话,依然建议保持星型模型——它能最大限度的发挥 Kylin 预聚合的优势。
2.2.2 主题域的划分
主题域的考虑可以从数据仓库层或者数据集市层出发,考虑将全域的数据分散到若干个主题中存放。就像图书管理员需要将书籍分门别类一样,主题域的划分是为了将相关的数据组织在一起,从而使其更容易被寻找和使用。
主题域的划分强依赖于对业务层面的理解。在一个不熟悉全局业务的情况下,划分主题域是非常困难的。有赞的主题域也随着有赞业务的发展,从最初的大约十个到如今的三四十个。
2.2.3 权限的设计
权限的设计分为库级权限、表级权限和字段级权限。权限的实现可以参考有赞大数据平台安全建设实践。
(1)库级权限
在数据集市层,我们大原则上采用库级权限控制——本主题域的相关人员对该库具有完整的读写权限。例外情况可以通过表级和字段级权限控制。
(2)表级权限
表级权限主要应用在落地层和数仓层。表级权限在大原则上也是基于主题域开放——主题域的相关人员对本主题域的相关表有读写权限。当需要跨主题域访问表时,要走额外的审批流程。
(3)字段级权限
字段级权限则主要是对于表中的敏感字段来说的。我们将敏感字段分成几个等级,所有人对于不同等级敏感字段的访问都要走额外的审批流程。当然审批流程会根据字段敏感等级选择不同的审批人。
2.2.4 数据字典
数据仓库的开发离不开对源表字段的理解。2017年4月,我们开始了数据字典相关的规划。当时要解决的首要问题是数据字段注释的缺失以及重要表字段 DDL 变更的跟踪。
自此,有赞的所有业务表字段都被要求填写注释。2017年底,有赞的所有新建表都默认带上了基于系统时间的 created_at 和 updated_at 审计字段。
有赞的数据字典也逐步经由元数据系统演变成如今的数据资产管理平台。
2.2.5 任务的优先级
在 Hadoop 的环境下,任务之间不可避免会出现集群资源竞争的关系。如果没有一个优先级规则,那么大量任务运行时,产出时间的波动是不可控的。于是,我们规范了任务的优先级,在调度层面让高优先级的任务优先进入队列,从而更容易获得资源。
| 任务优先级 | 使用规范 |
|---|---|
P1 |
涉及资损DW任务关键路径优先级 |
P2 |
重要DW任务关键路径优先级 |
P3 |
DW任务关键路径优先级 |
P4 |
DW任务非关键路径优先级/非DW任务关键路径 |
P5 |
非DW任务非关键路径(默认) |
2.3 成熟期
当我们用上述的这些规范解决了数据仓库的稳定性和可用性问题之后,随之而来需要考虑的是高效性和易用性。
随着有赞零售的发展对数据层面更多的需求越来越迫切。2018年下半年我们开始了对零售业务从0到1的数据仓库建设。数据仓库规范也在这片试验田上有了更多的演进……在“试验田”里的收获,让我们重新审视数仓里可能存在的问题。于是,2019年的我们再次做出了一些改变……
2.3.1 模型的选择——维度模型 VS 宽表
曾经的维度建模经验加上如今的宽表经验,使我相信维度建模依然是目前数据仓库最佳的选择。抛开了历史的包袱,我们在零售域上尝试了清晰的维度建模,并总结出它和宽表的一些优劣势。
| 比较点 | 维度建模 | 宽表 |
|---|---|---|
扩展性 |
维度表变更,事实表可能不影响 |
维度变更可能导致很多宽表都要调整 |
耦合度 |
事实表和维度表解藕,某些粒度上不会因为维度表失败而影响聚合表的产出 |
一个非重要任务失败会导致整个宽表无法产出 |
组织方式 |
任务及工作流易组织 |
因高耦合导致任务之间盘根错节,不利于组织任务和工作流 |
数据一致性 |
企业级数据仓库总线架构的基石 |
底层如果没有维度建模支撑,容易陷入混乱 |
易用性 |
维表需要多几个维表关联 |
宽表一时爽 |
鉴于以上的一些考量,在数仓层我们依然选择采用标准的维度建模的方式——星型模型。而宽表则可以存在于更靠后的数据集市层。
2.3.2 重新审视的DW分层
在 Kimball 早期的理论中还会单独提及并解释落地层 (Staging Area) 的作用,在后期就只提到展现层,而将落地层弱化成为整个 ETL 的一部分。
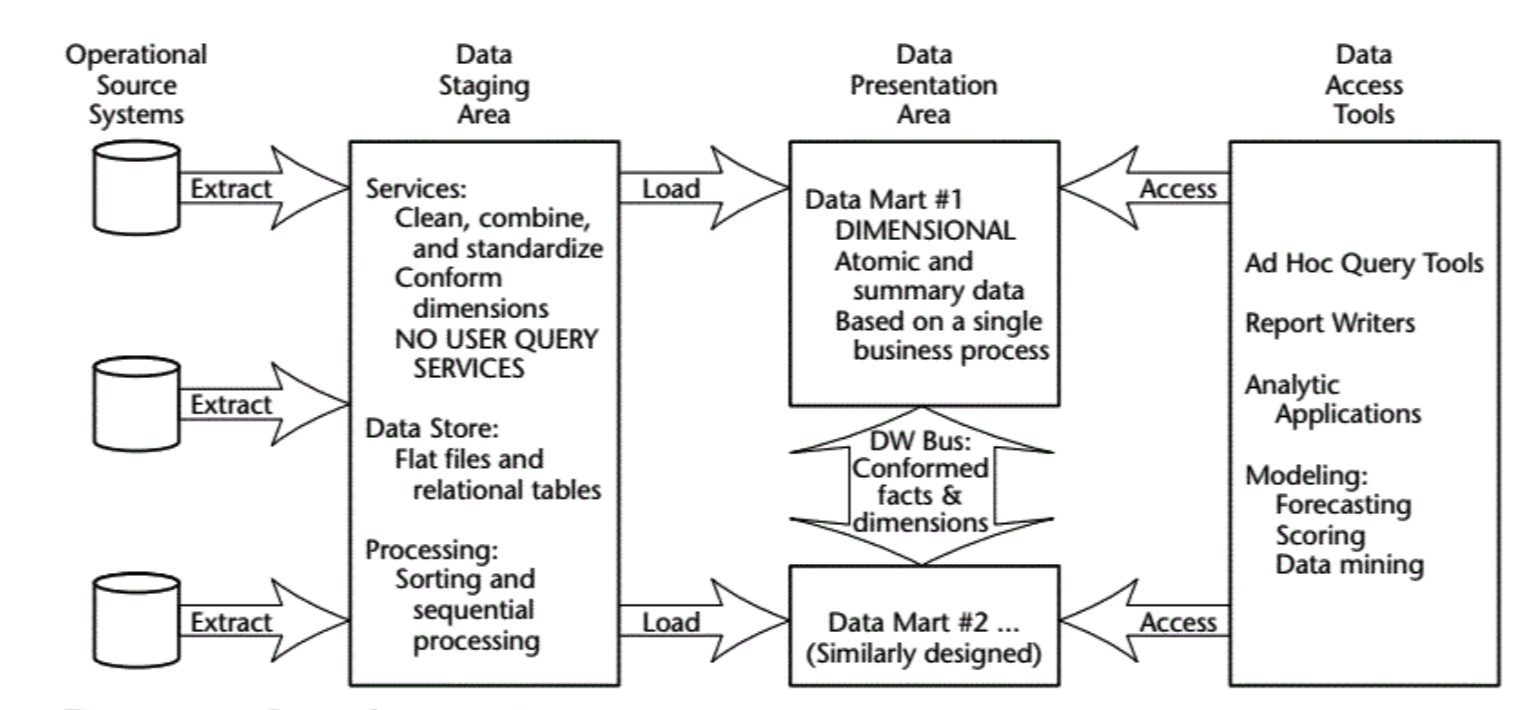
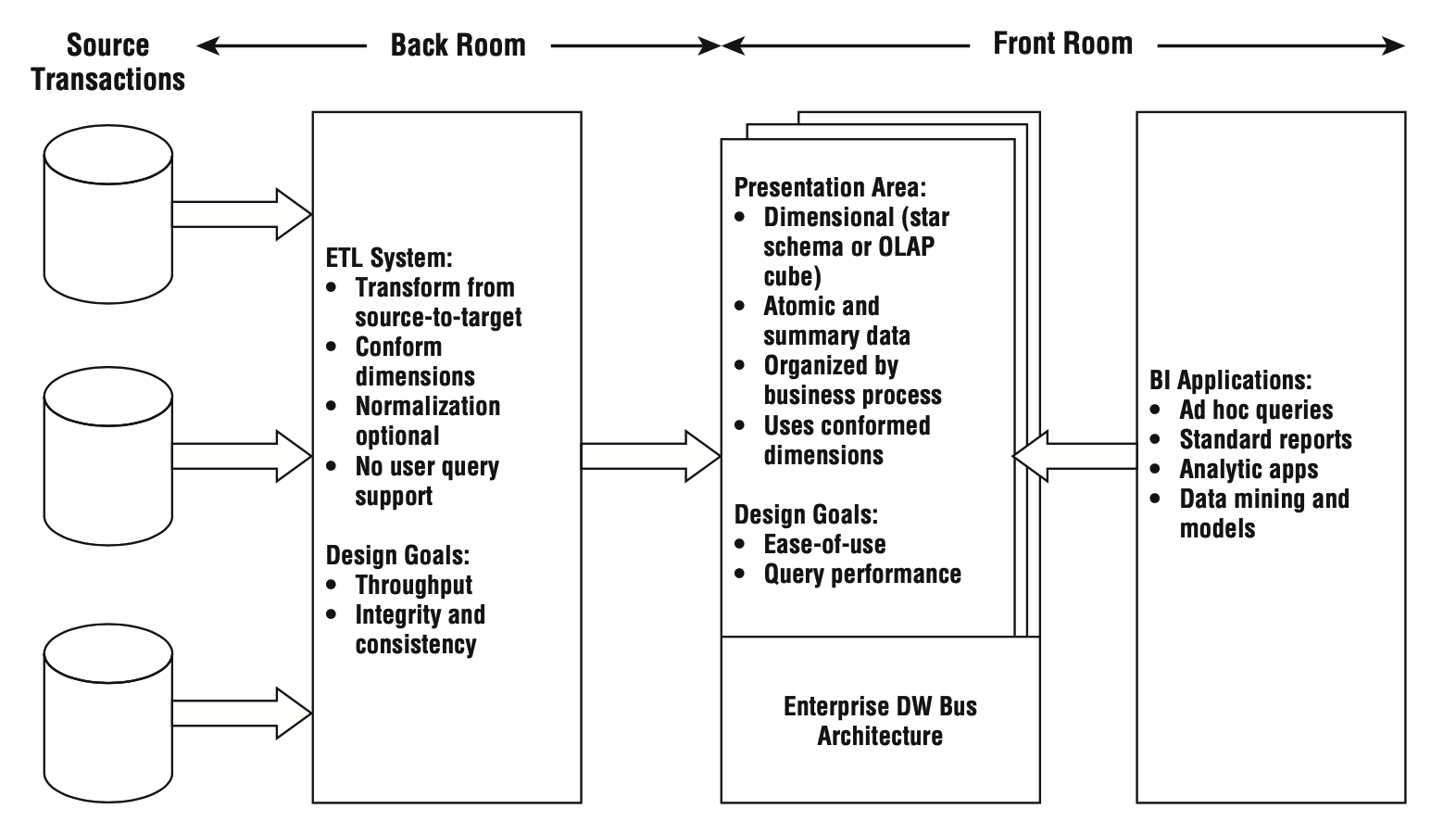
这个转变与我们的理念不谋而合:从业务层面看,数据仓库的核心是展现层和提供优质的服务。ETL 及其规范、分层等所做的一切都是为了一个更清晰易用的展现层。
数仓层内部的划分不是为了分层而分层,它是数据仓库经过了建模和 ETL 之后真正开始对外提供服务的地方,因此数仓层内的划分更应该符合使用者的思维习惯。 DW 内的分层没有最正确的,只有最适合你的。
基于维度建模的总线架构 (Bus Architecture) 理论,承载一致性维度 (conformed dimension) 的维度层是独立于事实并贯穿于数仓层全局的。
除此之外,我们提供了两种类型的事实表:明细表和聚合表。因此在我们的数仓层里,还会有明细层和聚合层。我们为明细层保留的关键字是 DWS (Data Warehouse Service),从这里开始,我们的表要承担起对外提供服务的职责。我们为聚合层保留的关键字是 DWA (Date Warehouse Aggregation)。
在大数据环境下,我们并没有按照 Kimball 的理论,显性地将事实表按照事务 (Transaction)、周期快照 (Periodic Snapshot) 和累积快照 (Accumulating Snapshot) 三种类型来划分。尽管这三种类型普遍存在于我们的数据仓库内,但由于用户并不容易理解三种事实表类型的划分方式,因此按照明细表和聚合表的方式分层,更容易让用户找到需要的表。
最后,在我们生产明细表和聚合表的时候,不可避免地会产生许多中间结果。所有这些中间结果并不承担对外提供服务的职责——它们对数据仓库的使用者是不可见的。我们为此单独设计了一个临时层来存放数仓层加工过程中可能产生的各种结果。临时层是在 Hive 上额外开辟的一个数据仓库开发人员专用的库。它承担了数据生产过程中问题数据的跟踪,也是数据存储清理时优先考虑的一块空间。
2.3.3 命名规范
前期我们也有各种命名规范,但是也同样踩了不少的坑。所以统一在这里把填过坑的规范跟大家分享。
(1)表命名规范
国际通行的命名方式有两种:驼峰命名法 (camelCase) 和蛇形命名法 (snake_case)。我们采用了蛇形命名法——全小写,单词之间用下划线分隔。
在落地层和数仓层中,都要包含主题域的关键字。数据集市层由于本身就按照一个个主题域物理隔离,因此表名中是否包含主题域关键字并不做强制要求。
在新的数仓分层中,我们使用了更清晰的表命名规范。
| 分层数据库 | 表命名规范 |
|---|---|
ODS 落地层 |
主题域_原表名[_可选的后缀] |
明细层 |
dws_主题域[_可选的二级主题域]_相关描述 |
聚合层 |
dwa_主题域_聚合维度 |
通用维度层 |
dim_通用维度相关描述 |
这里的落地层可能有些人叫 stg 有些人叫 ods。具体叫什么并不重要,重要的是命名的规范能够迅速地在所有相关人之间达成共识——这不仅包括了数仓的开发人员,更需要考虑的是数仓的使用人员。最终的目的还是让使用者能够快速准确地找到他们想要的数据。
聚合表时间后缀的含义
我们经常会发现聚合表的后缀会出现 _di 或者 _df,这里的 i 和 f 表示增量和全量,而 d 表示天,但是却又总是说不清楚它究竟是表示天级别的聚合粒度还是每天运行一次的调度周期。
大多数情况下表的聚合粒度和它的调度周期是一致的,然而也确实存在例外的情况:你可能每天运行一个聚合到小时级粒度的数据,以观察每小时的走势。
站在使用者的角度来看,他并不关心表的调度周期,只在乎这个表的聚合粒度。而调度周期则是一个跟工作流强相关的属性。
同样地,除非这张表里只包含了增量部分的数据(此时我们会用 _incr 后缀),否则使用者依然不会关心该表是增量 ETL 还是全量 ETL 的。
所以我们尽量不将表使用无关的 ETL 信息暴露给使用者。在有赞,聚合表的时间后缀只表示该表的聚合粒度,与 ETL 的调度周期或处理方式无关。
(2)字段命名规范
同名同义性是我们对字段命名的首要要求。如果两个字段名字一样,那么它们的含义应该是一样的;反之,如果两个字段名字不一样,那么它们的含义就一定是要有区别的。当这个要求放在单个主题域内的时候,还是容易实现的。当它推广到全域范围内,这个事情就会变得有些困难。
其次,字段名称清晰是另外一个要求。良好的字段命名应当是自解释的,如果看完字段的注释还无法理解甚至曲解字段的含义,那个可以说这个字段的命名和注释是不合格的。
2.3.4 任务命名及工作流组织规范
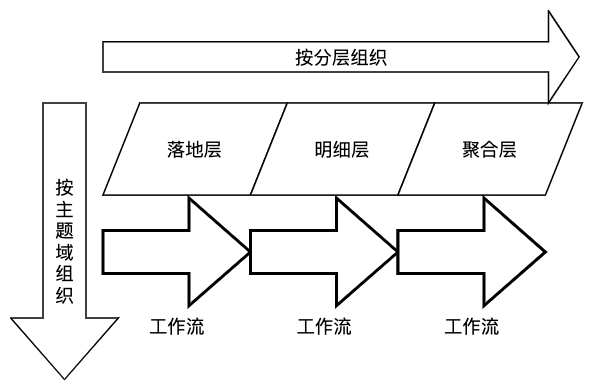
任务是组成工作流的最小单位,也是完成一次 ETL 的最小开发单位,同时也是调度任务进行失败重试的最小单元。我们要求一个任务只写一张目标表,同时任务的命名中必须包含该目标表的表名。
工作流是一次调度应用的最小单元,它将一组具有相关性的共同调度频率的任务组织在一起。
在没有工作流组织规范之前,我们的工作流组织因人而异显得五花八门。杂乱的工作流同样不利于数据仓库的管理和维护。于是我们将同一主题、同一分层且同一调度周期的任务组织成一个工作流。
2.3.5 计算引擎的进化
除了规范性方面,我们在 Hive 任务的执行引擎上也不断地从最初的 MapReduce 往 SparkSQL 切换。这期间也包括处理一些 HiveSQL 和 SparkSQL 的语法和行为不一致等各类问题。最终我们完成了90%以上的 Hive 任务以 SparkSQL 的方式运行。更多 SparkSQL 实战的详情可以参考 SparkSQL 在有赞的实践和 SparkSQL 在有赞大数据的实践(二)。
三、有赞数仓还在进化
标准化是数据仓库规范期望做到的目标。标准化规范很大一部分挑战来源于设计上整体通用性的考虑和使用上复杂场景特殊性之间的矛盾。
3.1 消除重复计算
消除重复计算是数据仓库标准化的一个目标——极致的标准化的确能消除重复计算。而重复计算不仅造成计算资源的浪费和效率的降低,同时也造成数据多个出口,降低易用性,使人在获取数据时感到困惑。
然而不幸的是,包括我们在内的各大公司的数据仓库都不可避免地存在重复计算的情况:不同业务线之间,存在各自计算同口径数据的情况;不同开发人员之间,存在各自维护同口径数据的情况。
于是我们开始考虑该如何消除这种重复计算的情况,从而提高集群资源的使用效率。
当一个用户问你要表的时候,其实要的是表里的某个字段。事实上所有对取数的需求归根结底都是对特定表字段里数据的需求。
因此我们设计了一个系统,用来登记开发出来的表字段,将所有口径一致的字段关联到一个指标上。这就是我们称之为指标库的最早原型和设想。
3.2 稳定性问题依然时刻被挑战
因为整个数据仓库依赖业务数据、底层 Hadoop 稳定性、调度监控平台、数据质量校验、埋点日志采集、自身数据量级、数据倾斜、SQL 优化等等,任何一个点出问题,都会导致数据仓库的数据产出受影响。因此稳定性依然是我们数据仓库捍卫的重点。
3.3 数据价值有待挖掘
3.3.1 数仓的价值
长久以来,要说清楚数仓的投入和产出都是非常困难的事情,尤其是产出价值的衡量。但是关于数仓自身的量化指标又是一个无法回避的话题。数据仓库的价值体现必然会落在相应的数据层面,而数据背后在决策支持层面的价值衡量则更为困难。因此,现阶段我们计划通过血缘关系尝试仅从数据层面先作出考量,从最终数据的使用出发,倒推出数据仓库可量化的价值。
3.3.2 BI
BI 产品无疑是近十多年来对数据价值最有力的贡献者,也是数据仓库不可回避的一个话题。对于 BI 的能力,我们只承诺提供全局的汇总数据和局部的明细数据。换句话说,在大数据环境下我们不提供全局的明细数据——因为没有人会真正逐行去看数以万计乃至数以亿计的明细数据。
有赞当前自研的 BI 产品还需要更丰富的可视化组件、结合指标库的模型映射支持拖拽模式、更多高级函数及数据挖掘算法模型的支持等。
四、我们的征程
由于篇幅的限制,有大量的细节问题在此未能尽述。这其中包括但不限于实时数仓、数据治理、数仓工作的量化、SQL 规范、调度监控、元数据监控、各种疑难杂症(踩坑填坑)、各类通用或特殊模型的探索设计等等。后续我们会考虑通过更多其他方式来介绍我们内部的细节。
有赞具有比平台型公司更复杂的账号体系、具有比纯线上公司更复杂的线下零售场景,更具有全球化的趋势,这一切都注定我们的数仓模型要支持的场景足够复杂且富于挑战。同时,有赞也在建立我们自己的数据中台。请记住2020年我们的目标是星辰大海!!!
小尾巴广告
有赞数据中台团队长期招人,期待你的加入~
数据业务架构师 数据平台架构师 大数据开发工程师 ...
如果你也是聪明、皮实、有要性的小伙伴 如果你对电商、SaaS有更多想法 欢迎投递简历:yeruidian@youzan.com 加入我们,一起enjoy
