一、前言
在 2019 年 1 月份的时候,我们发表过一篇博客 SparkSQL在有赞大数据的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91% 以上,最后也分享一些在 Spark 踩过的坑和经验希望能帮助到大家。
本文主要的内容包括:
- Thrift Server 稳定性建设
- SparkSQL 第二次迁移
- 一些踩坑和经验
二、Thrift Server 稳定性建设
随着完成了 Hive 到 SparkSQL 的第一次迁移,SparkSQL 任务占比一下子达到了 60% 以上,而随之而来的是各种问题(包括用户的任务失败和服务不可用等),服务的稳定性受到了比较大的挑战。
首先讲一下我们使用 SparkSQL 的部署方式,我们是以部署 Thrift Server 服务提供 JDBC 访问方式,即 YARN client 的部署方式。离线计算的调度任务以 beeline 的方式使用 Thrift Server,同时其他平台应用以 JDBC 的连接接入服务,比如提供 Ad-hoc 查询服务应用,数据质量检验服务应用等。
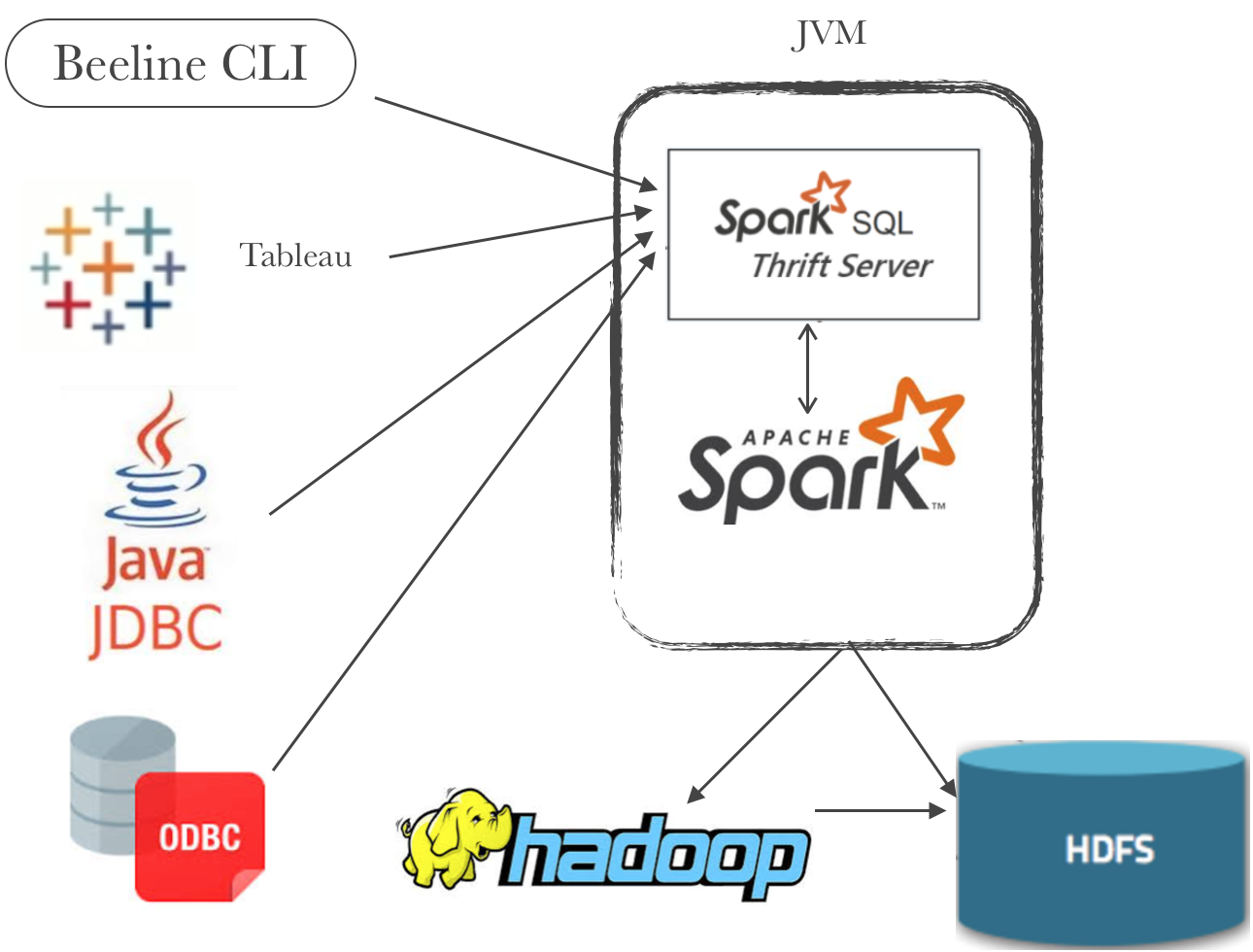
以 Thrift Server 方式的好处是由一个 Driver 来管理用于执行任务的 Executor 池,并发的执行不同的 SQL 任务可以让 Executor 资源的利用率达到最高。而如果选择 $SPARK_HOME/bin/spark-sql 方式来执行 SQL 的方式可以让每一个 SQL 任务独享一个 Driver ,不会受到其他 SQL 任务影响(特别是一些 SQL 可能导致 Driver OOM ),对比 Thrift Server 更加稳定;但是 YARN 资源利用率不高,比如启动 YARN Application 的 Overhead ,向 YARN 申请和释放 Executor 的 Overhead,SQL 任务倾斜导致的 Executor 空闲浪费等。考虑到目前我们大部分 SQL 任务的执行时间很短,基本在 3 分钟之内,单个 Task 执行时间很短,所以选择 Thrift Server 相对合适一些。
基于上面所说的部署方式,我们开展了以下主要的稳定性建设工作:
- AB 测试灰度发布功能
- Spark Metric 指标的采集、分析以及处理
- 基于 SQL 引擎选择服务拦截不合适的 SQL 任务
2.1 AB 灰度测试
在 Hive 迁移到 SparkSQL 这段时间,yz-spark (基于社区的二次开发版本)的迭代和配置变更开始有些频繁。我们希望有一套自定义的 AB 测试的解决方案来降低上线风险,特别对一些大的迭代版本和影响比较大的变更。
这套 AB 测试灰度发布不能简单的只是基于任务流量,我们希望先灰度一些非核心低优先级的 SQL 任务并且在白天时间段(低峰)来验证。有赞大数据离线调度任务是基于 Apache Airflow 为基础构建,因此实现方式是通过扩展 Airflow 增加了一些路由配置来支持 SparkSQL 任务可以按优先级、时间段、流量比例等配置的AB测试功能。
这套 AB 灰度测试方案在整个迁移过程还是发挥出比较大的作用。比如我们将 yz-spark 从社区版本 2.2.1 rebase 到 2.3.3 版本,又或者为节省内存资源给算法任务而将Executor 内存配置从 3G 调整到 2G 等比较重大的变更,都降低了一些坑产生的影响。
2.2 Spark Metric 采集
Spark 在 Job 运行过程中会记录很多 Metric 信息包括 Job 、Stage 、Task 和Executor 等几个方面。Spark 提供了 REST API 来查询 Metrics 数据,需要开启 Spark UI 的配置,不过需要注意是 Spark Driver在内存里保存最近运行 Job 信息,所以历史数据无法查询。另外 Spark 支持开启 EventLog 将相关的 Spark Event(携带了相关 Metrics 数据)进行持久化(比如配置 HDFS )。REST API 和 EventLog 功能的详细说明可以查看官方资料 (https://spark.apache.org/docs/latest/monitoring.html )。
结合了 REST API 和 EventLog 功能,我们搭建一个 spark-monitor 应用。这个应用主要职责是近实时的读取 EventLog 产生的 Spark 事件,通过事件回放并结合 REST API 最终形成我们需要的 Job 数据,并写到 Hbase 表保存。基于采集到的数据主要有以下几个方面的用途:
实时预警和干预。通过实时收集的 Job 数据,我们可以分析出哪些正在运行的 Job 是异常的,比如耗时非常久,产生很多 Task 等等场景,然后针对异常场景的 Action 可以是 Alarm 或者 Kill Job 等。
离线分析。每天从 Hbase 离线的同步到hive表做一些离线分析,比如统计存在 Failed Task 的任务、Peak Execution Memory 使用比较高的任务,或者数据倾斜的任务等。找出已发生问题或者潜在问题的任务,去优化 SQL 任务或者分析原因并反哺去调校 Thrift Server 配置。
历史 Job 数据保存,用于排查历史任务的日志查找和分析( Spark UI 因为内存限制无法保留历史任务的记录)。
2.3 基于引擎选择的 SQL 拦截
我们开发了一套 SQL 引擎选择服务,他的主要职责是给 Ad-hoc 服务增加了 SQL 智能选择的能力。有赞的大数据离线计算提供了 Presto/SparkSQL/Hive 三种引擎选择,大数据经验比较弱的用户在执行 Ad-hoc 的 SQL 时往往不知道该怎么选择。而 SQL 引擎选择通过 SQL 解析,语法检查,规则匹配,各个引擎的资源负载情况等等因素最终给用户选择合适的引擎来执行计算。
SparkSQL 正是通过添加一些自定义规则来拦截对 Spark 引擎不合适的 SQL 任务,从而提高 Spark 服务的稳定性。比如 Not in Subquery, Cross Join 等 SQL 场景。
三、SparkSQL 第二次迁移
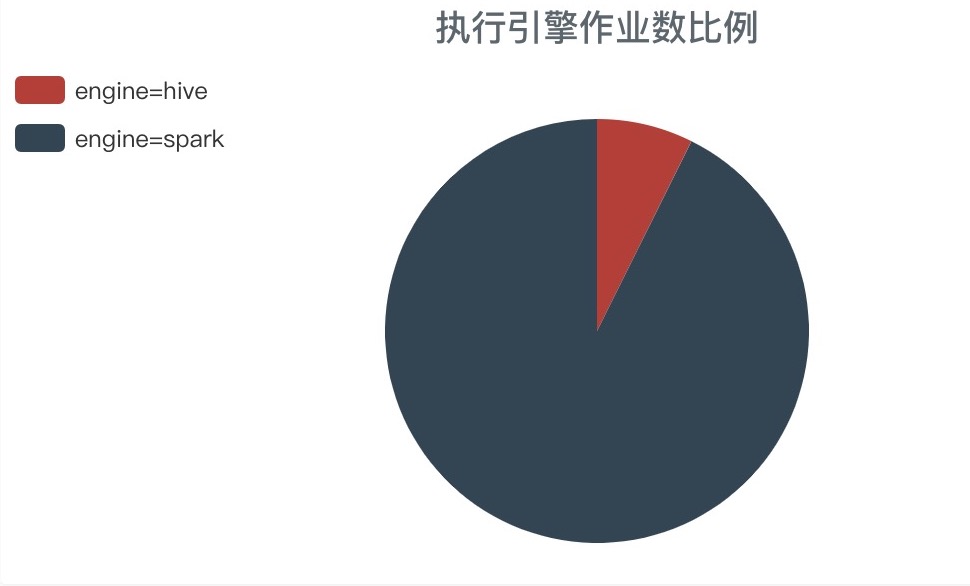
第一次做的迁移主要完成了 P4 和 P5 低优先级的任务。在生产上经过一段时间的充分验证后,并且在 Spark Thrift Server 的稳定性得到极大的提升之后,然后就开始了第二次大规模的 Hive 到 Spark 的迁移,完成了 P1 ~ P3的所有适合任务。截止目前执行引擎选择的作业数中 SparkSQL 占比已经提升到 91% 以上。
而之所以把核心任务也迁移到SparkSQL,这样的做的好处有两个:
- 节约离线集群资源成本。通过
tpcds的性能测试,同等资源情况下 SparkSQL 是 Hive 的2 ~ 10倍(不同的 query 性能表现不一样)。在生产验证下来大部分确实有差不多2倍的性能。 - 计算资源更合理的分配。由于 Spark 自身实现任务调度和资源分配,可以通过它已有的功能针对不同优先级的任务配置不同的资源配额。比如原先使用 Hive 时每一个 SQL 任务的 map 或者 reduce 并发数默认都是一样的,而使用 SparkSQL 时可以让
资源的比例按优先级倾斜(即 scheduler pool 的功能)。
四、踩坑和经验
在使用 Spark 过程中,我们不可避免的踩过一些坑,也积累了一些经验。从这些经验积累选择了一部分想分享一下,希望对正在使用 Spark 的同学有所帮助。
4.1 spark.sql.autoBroadcastJoinThreshold
这个配置在大家使用 SparkSQL 的时候会比较熟悉,在 join 的场景判断相关的表是否可以使用 BroadcastJoin ,默认阀值是 10 MB。目前阀值判断的比较逻辑会参考几个因素:文件的大小和字段选择的裁剪。比如某张 Hive 表的数据大小为 13 MB , 表 schema 为 struct<id:long,name:string>,而假设当前 SQL 只使用到 name 字段,那根据字段选择情况并对文件大小进行裁剪估算所需总字节的公式为: 20 / (8 + 20) * 13 约等于 9.3 MB(各个字段类型有不同的估算字节,比如long 是 8 个字节 ,string 是 20 个字节等),从而满足 BroadcastJoin 的条件。但是这里有几种情况需要额外考虑:1、表存储格式带来的差异,比如 使用 ZLIB 压缩的 ORC 格式跟 TEXT 格式就在数据存储上的文件大小可能会差很多,即使两张表都是 ORC 格式,压缩率的差异也是存在; 2、字段字节估算本身就有一定的误差,比如 string 字段认为是 20 个字节,对于一些极端情况的 string 大字段,那估算误差就会比较大; 3、读取 Hive 表的 "raw" 数据到内存然后展开成 Java 对象,内存的消耗也有一定放大系数。所以 10M 的阀值,最终实际上需要的内存可能达到 1G,这个我们也是在生产环境上碰到过。
4.2 spark.blacklist.enabled
Spark 针对 Task 失败有重试机制,但是当一个 Task 在某一台 host上的 一个 Spark Executor 实例执行失败,下一次重试调度因为考虑 Data Locality 还是会大概率的选择那个 host 上的 Executor。如果失败是因为机器坏盘引起的,那重试还是会失败,重试次数达到最大后那最终整个 Job 失败。而开启 blacklist 功能可以解决此类问题,将发生失败的 Executor 实例或者 host 添加到黑名单,那么重试可以选择其他实例或者 host ,从而提高任务的容错能力。
4.3 spark.scheduler.pool
当我们的调度离线计算 SQL 任务,大部分都使用 SparkSQL 带来的问题是有些低优先级的任务可能会消耗很多 Executor 资源,从而让高优先级的任务一直得不到充分的资源去完成任务。我们希望资源调度的策略是让优先级高的任务优先得到资源,所以使用 Fair Scheduler 策略,并配置不同资源权重的 Pool 给不同优先级的任务。
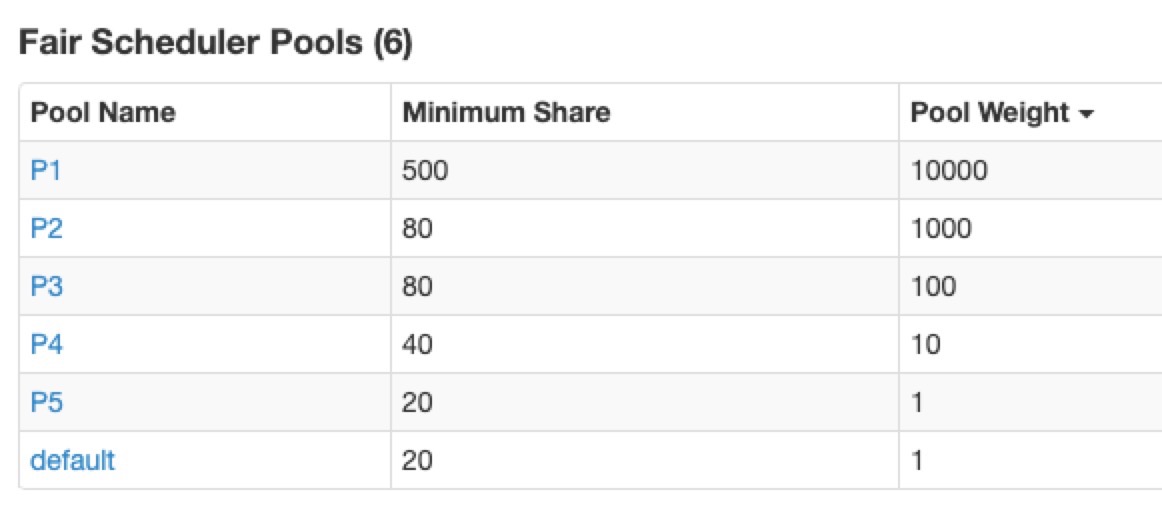
注:Spark 2.4 以下版本的这个功能存在 SPARK-26992 的问题,在不指定 pool 的情况下可能不会使用默认 pool 。
4.4 spark.sql.adaptive.enabled
adaptive 功能支持 shuffle 下游 stage 可以根据上游 stage 产生的 shuffle 数据量自动调节下游 stage 的 task 数,这个功能我们主要是为了解决 Hive 表数据表很多小文件的问题(Map Only 的 SQL 场景不起作用)。adaptive 功能在 Spark 1.6 版本就已经支持,但是我们目前 yz-spark 版本合入是Intel 实现的增强版本(该版本还实现了另两个功能:动态调整执行计划和动态处理数据倾斜),目前官方版本还没有合入(https://github.com/Intel-bigdata/spark-adaptive)
4.5 SPARK-24809
这是一个 correctness 的 bug, 在 broadcast join 的情况下可能会发生数据结果不正确的情况。当用于 broadcast 的 LongToUnsafeRowMap 对象如果被多次的序列化反序列化就会触发,导致野指针的产生,从而可能产生不正确的结果。当时这个问题导致我们一张核心仓库表产生错误数据。由于这个 bug 几周才偶现一次,复现的困难导致花费了一个月时间才定位原因。这次教训也让我们意识到需要经常的去关注社区版本的迭代,及早发现特别是那些比较严重的 bug fix,避免生产上的故障。
4.6 SPARK-26604
这是 Spark External Shuffle 的一个内存泄漏 bug ,所以在开启该功能的情况才会触发。它在某些场景下会导致 NodeManager 的 ExternalShuffleService 开始内存泄漏,这个内存泄漏比较大的危害是导致一个 HashMap 对象变的越来越大,最终导致 shuffle fetch 请求越来越慢(每次 fetch 请求需要对这个 HashMap 的 values 进行 sum 统计,这个逻辑变慢),从而最终导致了我们生产环境的离线任务耗时时间在某天突然多了 30% 以上。
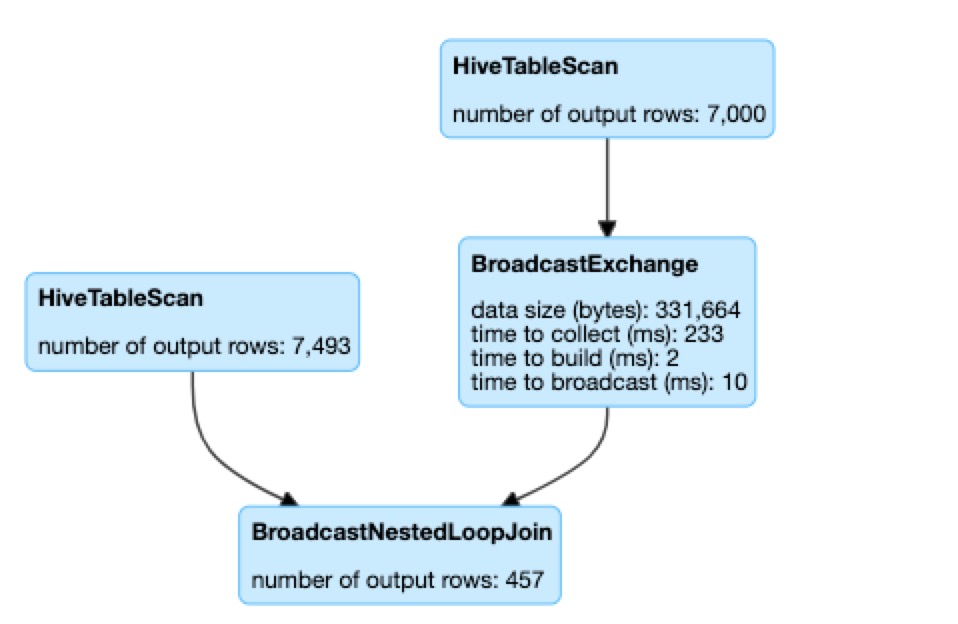
4.7 低效且危险的 Not in Subquery
举个例子, select * from t1 where f1 not in (select f1 from t2),对于 “ not in subquery ”的场景最终都会选择 BroadcastNestedLoopJoinExec 物理执行计划,而 BroadcastNestedLoopJoinExec 是一个非常低效的物理执行计划,内部实现将 subquery broadcast 成一个 list,然后 t1 每一条记录通过 loop 遍历 list 去匹配是否存在。由于它的低效可能会长时间占用 executor 资源,同时 subquery 结果数据量比较大的情况下,broadcast 可能带来 driver 的 OOM 风险。
四、结语
至今,有赞大数据离线计算从 Hive 切换到 SparkSQL 达到了一个阶段性的里程碑。虽然 SparkSQL 对比 Hive 的稳定性有所不如,特别是内存管理上一些不完善导致各种内存所引发的问题,但是性能上非常明显的优势也值得作为一种新的选择,我们也一直努力着希望将 SparkSQL 调校成具有 Hive 一样的稳定性。
