一.背景
数据中心为微商城和零售的商家后台分别建立了一套数据模型、 数据服务, 在此基础上分别建立了一套数据分析的产品体系,随着微商城和零售慢慢往连锁版本融合并伴随着新业务接入,目前的开发模式遇到了以下痛点:
- 两套数据服务有很多相同之处,重复烟囱式的开发,造成了人力资源浪费,而且开发效率低,从数据开发到最终交付数据服务,需要经历较长的周期;
- 两套数据模型在指标上存在大量重合,相同的指标的重复开发,增加了开发和维护成本,且存在口径不一致的风险,导致众多线上咨询,损害了商家对数据可靠性的信任。
基于上述痛点,数据应用团队搭建了统一的数据模型和数据服务。本文将介绍在搭建统一数据模型的过程中遇到的问题并给出相应的解决方案。
二.统一数据模型实现
上层的数据分析模型会在某个主题下,对多个主题域的数据指标进行分析,因此上层数据模型需要包含丰富的指标。 本文将以kylin作为在线存储的选型为例,分享统一数据模型建设中逻辑表的建设实践。
一.大宽表解决方案
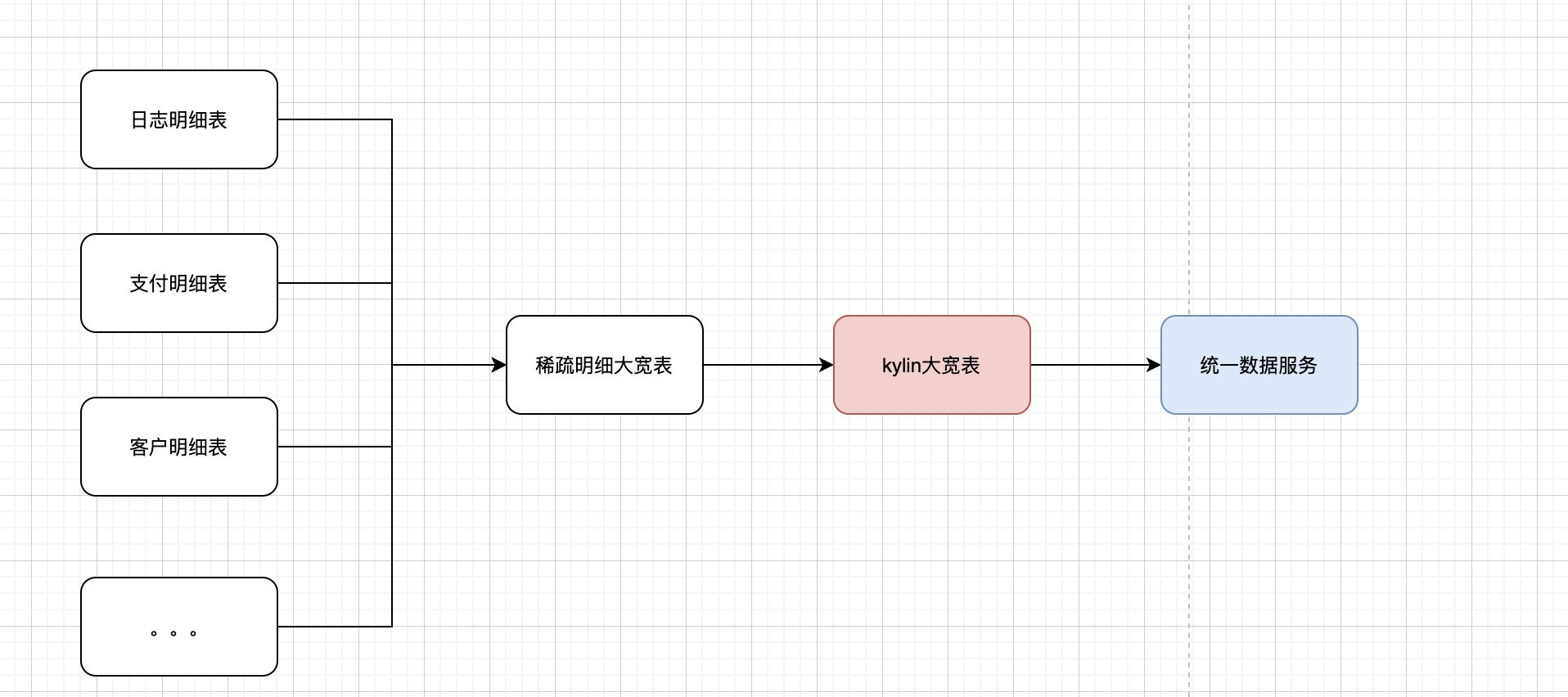 图一 大宽表解决方案
图一 大宽表解决方案
方案一是日常数据开发中比较常规的一种操作方式,将各个业务域的明细表进行汇合,生成一张稀疏的明细大宽表,这里的稀疏指的是每行的记录只写入自己业务域的指标和维度,其他业务域的指标按空处理。
最终大宽表的数据量为各个业务域的数据量相加之和。在hive层经过ETL后,将大宽表导入kylin中,根据业务对cube进行建模。
大宽表方案的优点为方案简单,且分页排序等复杂的查询场景sql也会比较简单。 但缺点也很明显:
- 刷数据问题,其中任意一个业务域的数据出现问题,需要数据修复,需要重新构建上述的大宽表,并且kylin上需要对整个大宽表的指标进行计算,整个数据恢复时长较长。
- 稀疏性导致的数据倾斜,比如日志域的数据量是几十亿,那么自然会出现几十亿个支付相关的空字段,这些大量的空字段导致kylin构建字典时的数据倾斜。
- 数据产出并发度低,大宽表构建任务依赖最晚产出的明细表,某个域产出延迟,导致多个业务域受到影响
指标复用能力较弱,有新的业务需要和其他业务域进行组合时需要重新构建cube,容易产生数据指标口径不一致、指标重复计算等问题。 - 底层模型可扩展性差,表结构一旦确定后续增加指标或维度时,开发、构建数据等成本都很高
这些缺点让大宽表处于用时一时爽,但维护起来问题重重的困境。
二.分域解决方案
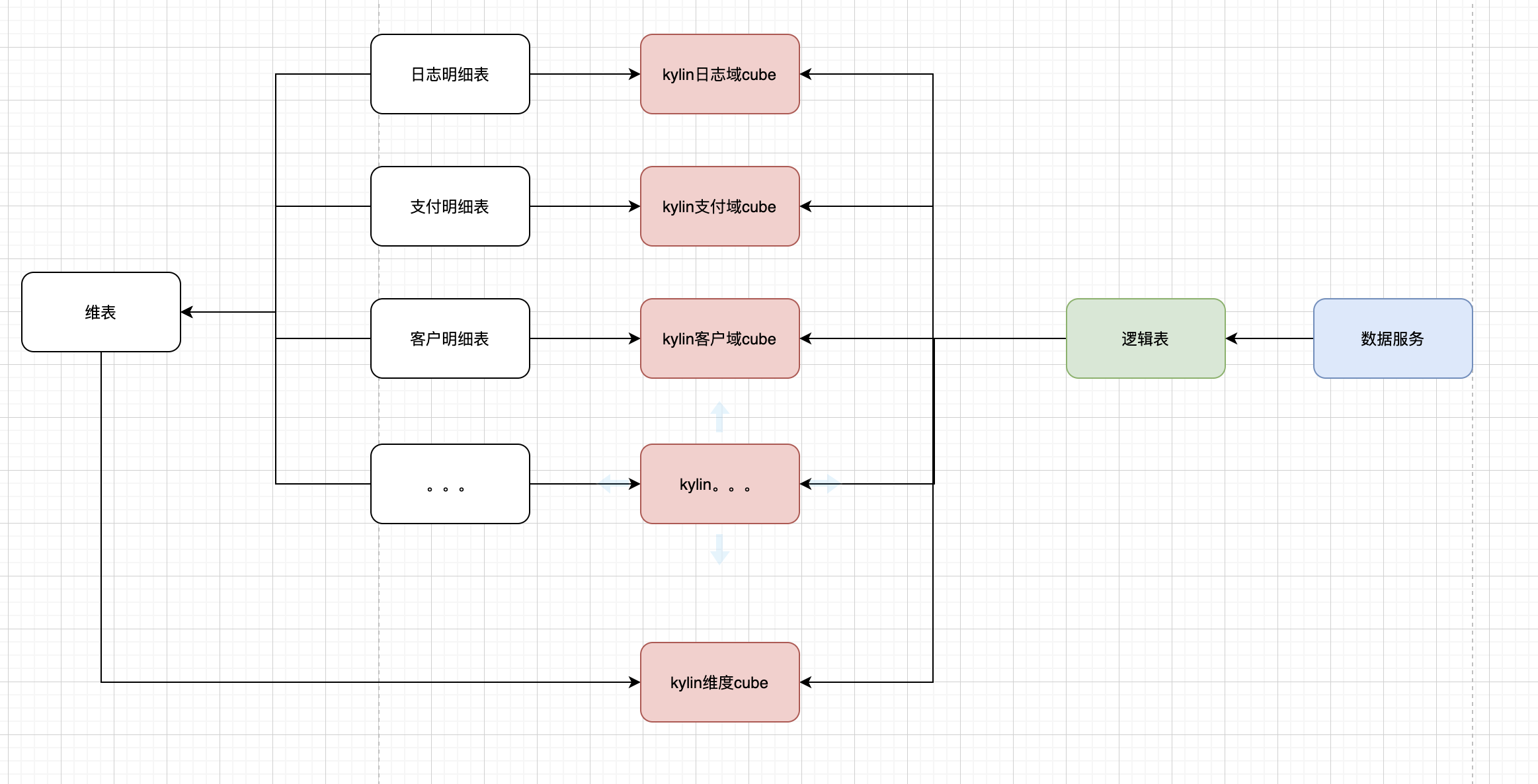
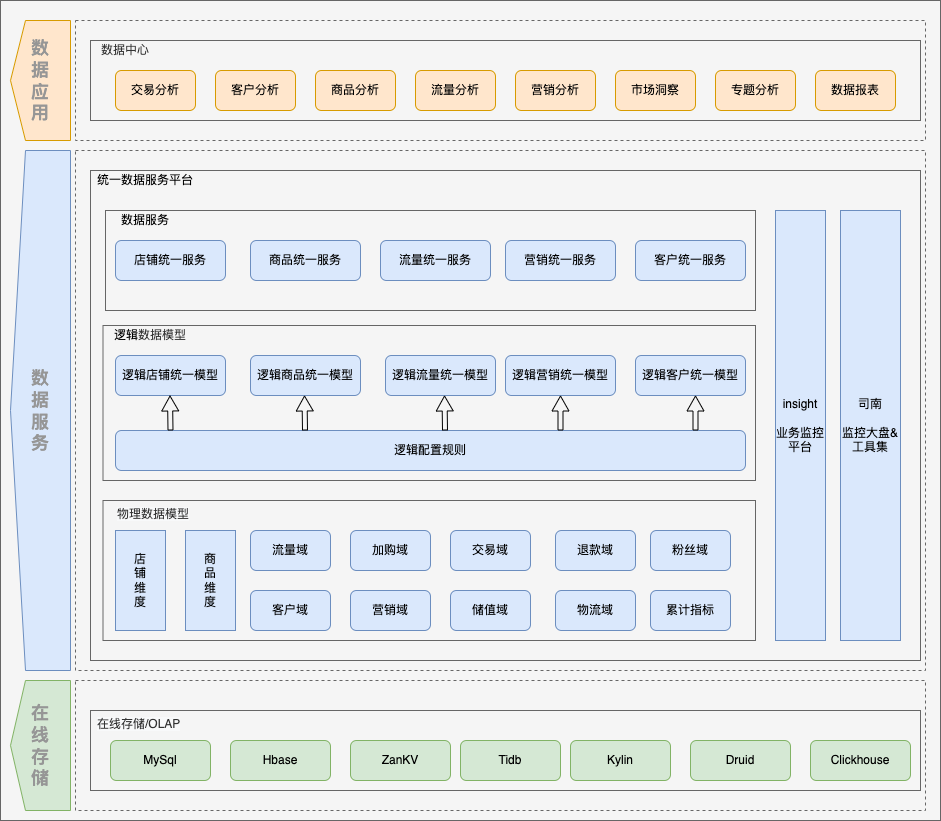 图二 基于逻辑表数据服务架构
图二 基于逻辑表数据服务架构
为了解决底层指标的统一和解决大宽表刷数资源问题,我们在各个主题下为各个域设计了相应的物理表,各自根据业务特性进行cube设计, 这样做的好处在于:
- 各个域的模型更稳定更聚焦,简洁清晰,容易维护和扩展指标。
- 各个域耦合度低,不存在大宽表依赖最晚产出的明细表的问题,各个域可以并发构建。
- 分域后各Cube构建时间短,恢复数据效率高。
但这些分域的物理表在对上层应用提供服务时并不友好,我们在统一数据服务中根据配置将各个物理表映射到一张逻辑表中,通过逻辑视图对外提供服务,让其既保持宽表的便捷性,又能提供高效的查询性能。
三、逻辑表实现
一.数据库视图
最简单直白的实现方式是通过join的能力将各个域的数据在计算时合并到一起,生成一个视图,所有的查询都转换成基于该视图的查询。
但产生的问题是join性能较差,在实际测试过程中某些场景多个域的join相比于宽表模式查询时延会高几十秒。对于在线场景,这样的性能的损耗是完全不能接受的。
此外对于跨数据源的场景,数据库视图也是行不通的,对于后续数据接入的扩展性限制较强。
二.服务层处理逻辑视图
对于数据库视图的实现方式,虽然简单,但是有各种限制。于是我们决定在服务层自行实现逻辑视图,通过规则配置,将物理表字段映射到逻辑表的字段上,查询时正常查询逻辑表,底层引擎自动根据规则进行sql重写,尽可能的将查询下推到数据库中,之后在服务层实现二次计算,比如结果集归并、复合指标计算、排序等。这个过程根据业务场景可以有更多的优化空间和扩展性。
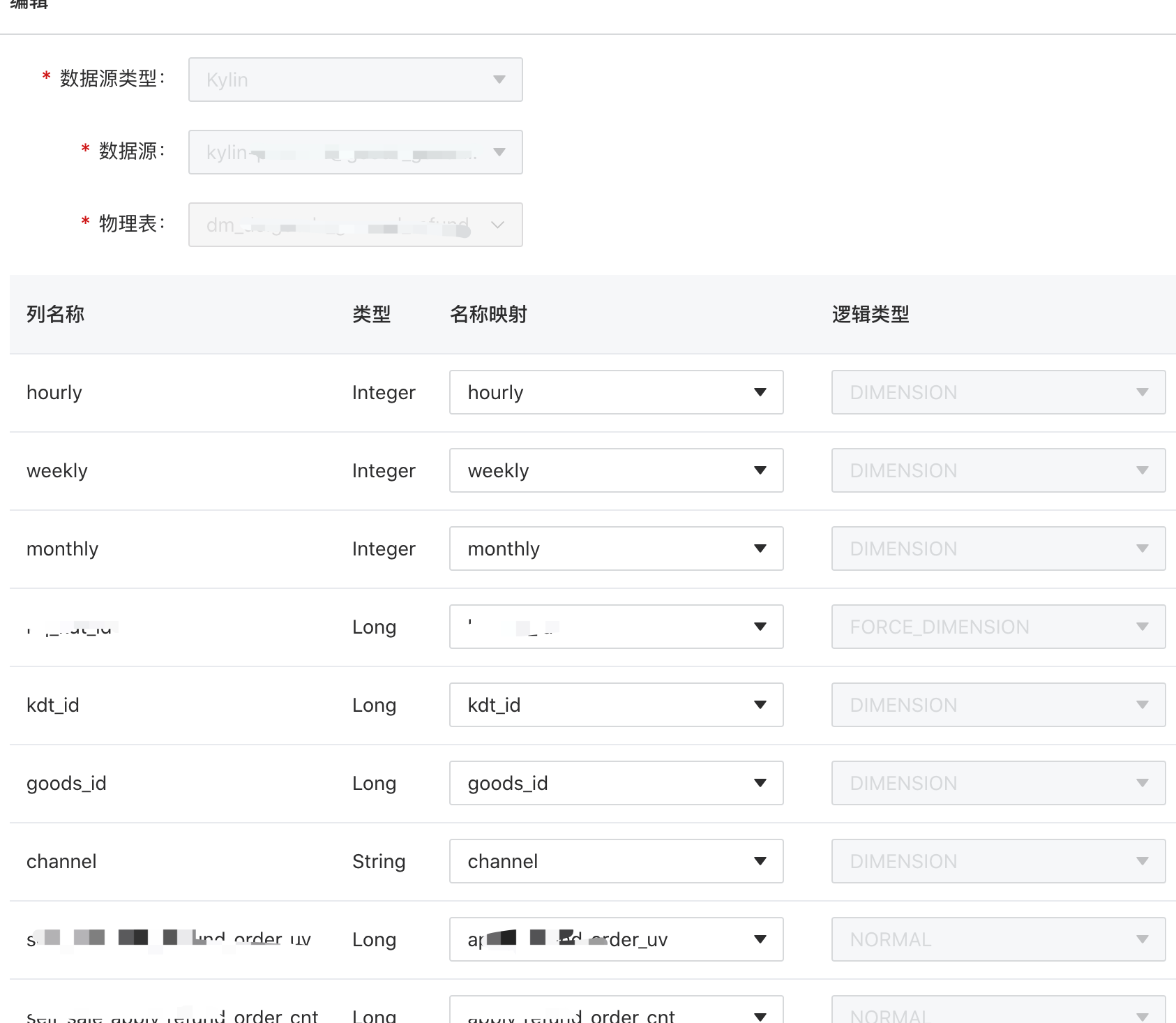 图三 统一数据服务中逻辑表配置
图三 统一数据服务中逻辑表配置
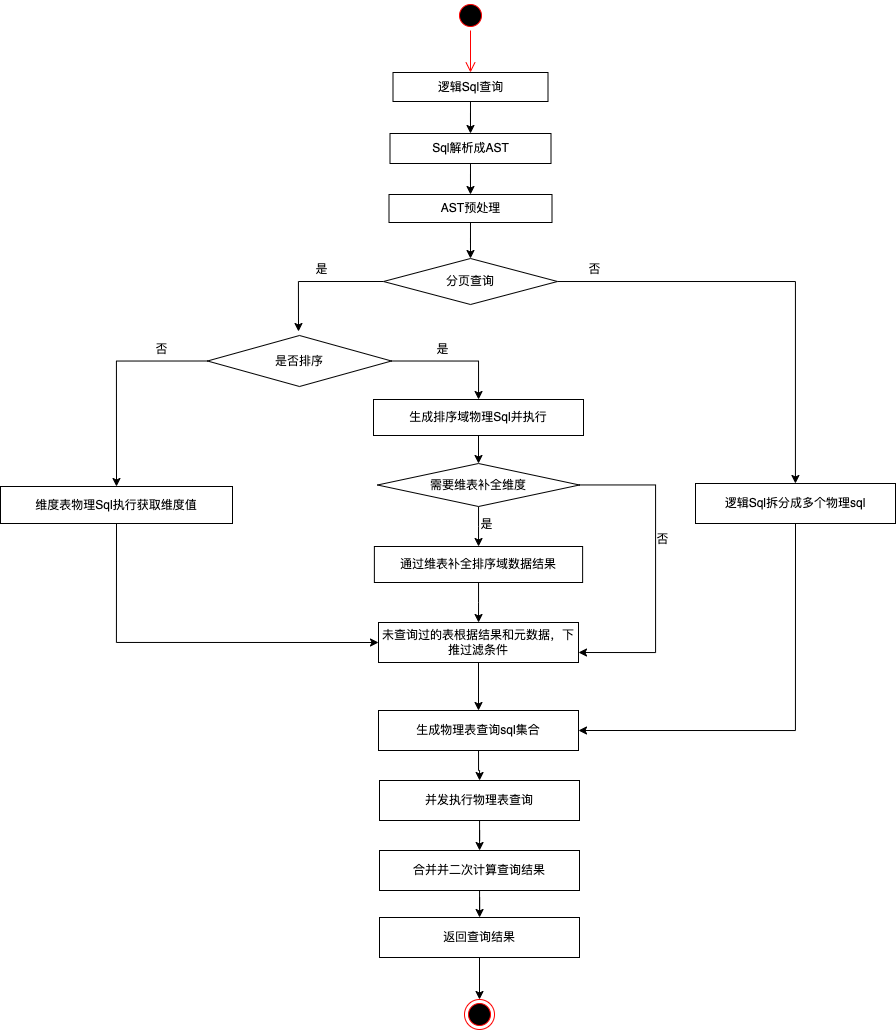
逻辑表处理流程大致分以下几步
1.首先我们解析逻辑sql,将其解析成抽象语法树,然后对其进行预处理。比如对于复合指标,我们会校验字段内容是否都属于同一个物理表,如果存在跨数据源的复合指标,会将复合指标进行拆分成多个查询字段。
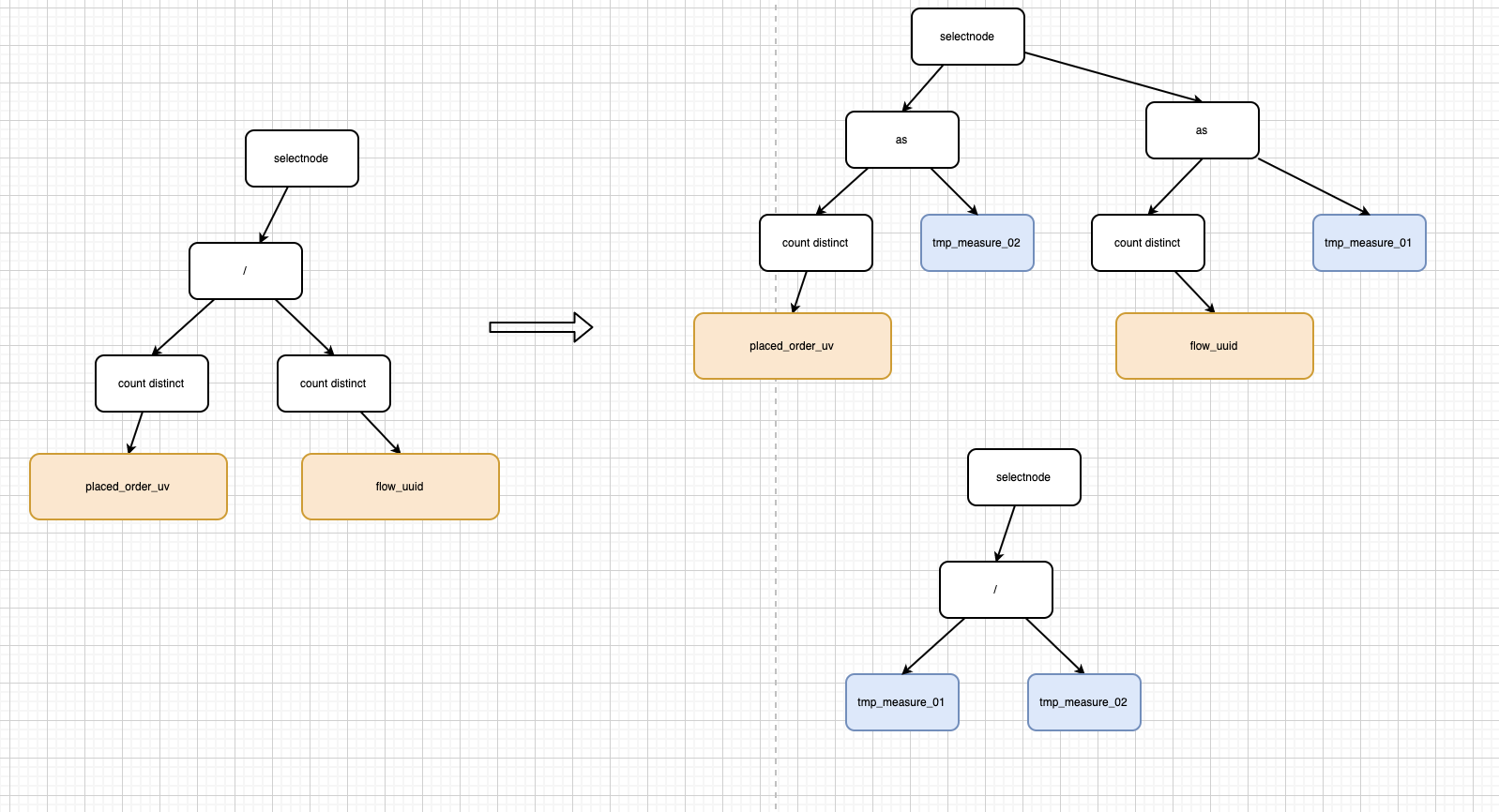
图四 复合指标预处理
2.对于大数据量的分页排序的场景,如果简单地在服务端进行数据聚合后再进行分页,会退变成数据库视图的模式,服务端的计算和内存压力将会特别大。
由于当前场景基本都是对于单域指标的排序,对于单域的指标的分页排序,可将分页排序下推至排序的域。
此时可认为对当前分页排序出来的结果进行补充其他域的数据,也就是将出现在group by字段中的值放到其他域的过滤性条件中,充分利用索引,避免全表扫描。
在分页排序的场景下,因为各个域的数据是不同的,在分页排序场景下总数的计算难以从一个域中获得,将会出现按照不同域的指标进行排序时数据总数是不同的,并且分页的结果也是缺失的,无法通过其他域的数据进行补全。
针对维度缺失问题,我们通过动态生成数据维表,查询时进行补全维度。
在数据生产过程中除了各个事实表的建设,额外将多个域的维度数据合并成一个维表,动态生成只包含维度信息的维表,在查询时对缺失的维度进行补充。
 图五 分域数据维度补全实现
图五 分域数据维度补全实现
这样做的优点在于:
- 各个域的cube构建没有相互依赖
- 不存在写入大量无用数据的问题
- 数据查询性能损耗较小,只有在必要时才需要进行维度补全,维度补全过程不再需要所有域的数据进行join再去重。
与此同时该方案存在的缺点是:
- 逻辑表需要额外依赖维度表,查询的复杂度会提升
- 某个域的数据出现问题时,不仅需要重跑当前域的数据,还需要重跑维表。
3.其他未处理过的物理表会根据指标的逻辑字段和物理字段的映射关系进行各自表上的查询字段改写。因为各个域的指标之间是相互独立的,不会出现一个逻辑指标存在多个域之中,这样就能保证即使是去重指标,我们也可以轻松地下推到数据库中执行。同理我们将过滤条件,聚合条件根据逻辑字段和物理字段的映射关系进行重写,如果遇到某个过滤维度只存在部分物理表中,那么不存在该维度映射的物理表将会裁剪该维度过滤条件。通过上述方式我们将生成物理执行sql集,之后并发地去执行这些sql。
4.服务端获取到各个域的数据后根据预处理的sql,对结果集进行数据归并、复合指标二次计算、排序等操作。
整体流程如下:
接下来,我们举个简单的例子来帮助解释上面的流程。对于商品主题下的分析有两个主题域
交易域:
CREATE TABLE `dm.TRADE`(
`shop_id` bigint COMMENT '店铺id',
`goods_id` bigint COMMENT '商品id',
`sku_id` bigint COMMENT '规格id',
`channel` string COMMENT '渠道标识',
`online` bigint COMMENT '线上线下标识',
`placed_order_uv` string COMMENT '商品下单人数',
`placed_order_cnt` string COMMENT '商品下单订单数 ',
`placed_order_amt` bigint COMMENT '商品下单金额 ',
`placed_sku_cnt` bigint COMMENT '商品下单商品件数')
COMMENT '商品交易模型'
日志域:
CREATE TABLE `dm.FLOW`(
`shop_id` bigint COMMENT '店铺id',
`goods_id` bigint COMMENT '商品id',
`channel` string COMMENT '渠道标识',
`uuid` bigint COMMENT '商品详情页访客id',
`pv` bigint COMMENT '商品详情页访问PV',
`keep_duration` bigint COMMENT '商品详情页停留时长')
COMMENT '商品流量模型'
加购域
CREATE TABLE `dm.ADDCART`(
`shop_id` bigint COMMENT '店铺id',
`goods_id` bigint COMMENT '商品id',
`sku_id` bigint COMMENT '规格id',
`channel` string COMMENT '渠道标识',
`add_cart_sku_cnt` bigint COMMENT '加购商品件数',
`add_cart_uv` string COMMENT '加购人数')
COMMENT '商品加购模型'
这三个域通过字段映射可配置生成一张逻辑表
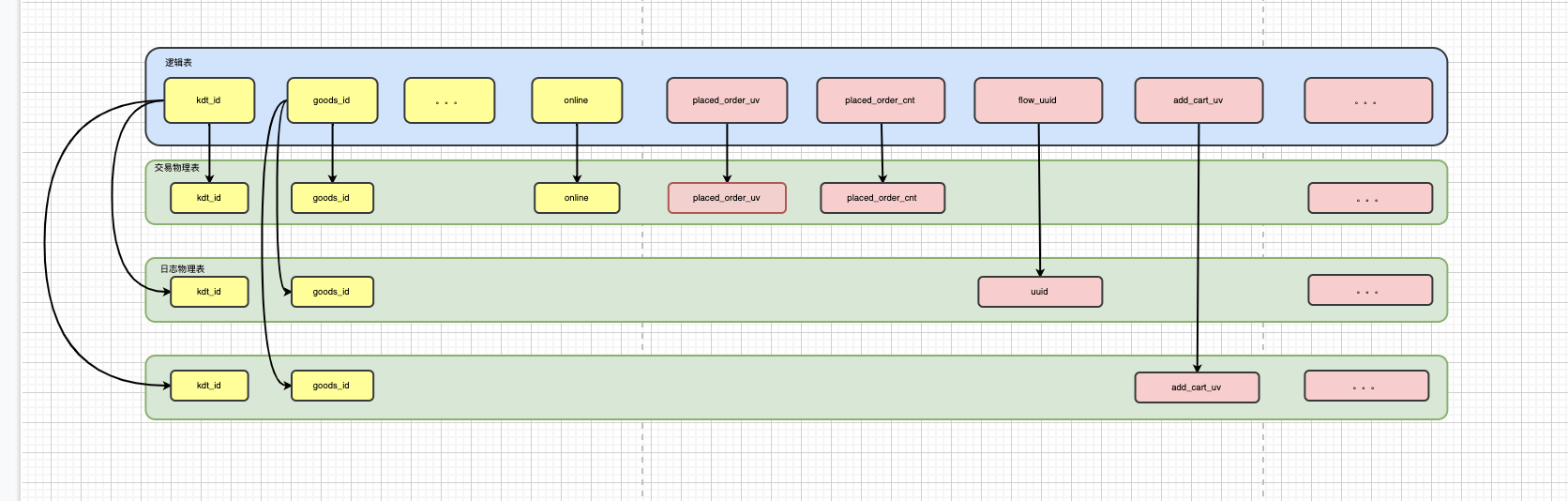
图五 物理表和逻辑表映射
对于查询
select shop_id,goods_id,
count(distinct placed_order_uv) as order_uv,
count(distinct placed_order_uv)/count(distinct flow_uuid) as paid_rate,
sum(pv)/count(distinct flow_uuid) as uv_rate,
count(distinct add_cart_uv) as add_cart_uv
from logic_goods where shop_id=123 group by shop_id,goods_id order by order_uv limit 5 offset 10
会转换成如下查询:
先执行order by域数据
物理查询sql1:
select shop_id,goods_id,count(distinct placed_order_uv) as order_uv,count(distinct placed_order_uv) as tmp_measure_01,
from dm.TRADE
where shop_id=123
group by shop_id,goods_id order by order_uv limit 5 offset 10
查询结果为
| shop_id | goods_id | order_uv | tmp_measure_01 |
|---|---|---|---|
123 |
1 |
1 |
1 |
123 |
2 |
2 |
2 |
123 |
3 |
3 |
3 |
123 |
4 |
4 |
4 |
123 |
5 |
5 |
5 |
接下来处理其他域的数据
物理查询sql2:
select shop_id,goods_id ,count(distinct flow_uuid) as tmp_measure_02,sum(pv)/count(distinct flow_uuid) as uv_rate from dm.FLOW
where kdt_id=123 and goods_id in(1,2,3,4,5)
group by shop_id,goods_id
物理查询sql3:
select shop_id,goods_id ,count(distinct add_cart_uv) as tmp_measure_02 from dm.ADDCART
where kdt_id=123 and goods_id in(1,2,3,4,5)
group by shop_id,goods_id
之后我们通过预处理的sql对结果集进行归并。
select kdt_id,goods_id ,sum(order_uv),sum(tmp_measure_01)/sum(tmp_measure_02) as paid_rate ,sum(uv_rate) as uv_rate from logic_goods group by kdt_id,goods_id
四.效果
我们以店铺主题下的某个分析模型为例,对比一下大宽表模式和逻辑表模式的性能。
表一:构建性能
| 模式 | 构建前置依赖时长 | 构建时长 | 构建完成时间 |
|---|---|---|---|
大宽表 |
2小时 |
40分钟 |
每天5:30 |
逻辑表 |
无 |
平均构建时长20分钟 |
所有域构建最晚时间为4:30,大部分在3点之前可产出 |
表二:查询性能
| 模式 | TP95 | 大于1S慢查次数占比 |
|---|---|---|
大宽表 |
550ms |
5% |
逻辑表 |
350ms |
整体低于0.2% |
五.未来的展望
现逻辑表目前更多解决的是同维跨域的问题,后续可支持更多的场景如智能查询加速等。此外当前二次计算的算子都是在服务端通过自定义算子实现,对于calcite的使用更多的是在sql解析与改写,后续可完整地使用calcite的计算能力,丰富逻辑表的查询能力。
