一、 背景
HBase 是一个面向列,schemaless,高吞吐,高可靠可水平扩展的 NoSQL 数据库,用户可以通过 HBase client 提供的 put get 等 api 实现在数据的实时读写。在过去的几年里,HBase 有了长足的发展,它在越来越多的公司里扮演者越来越重要的角色。同样的,在有赞 HBase 承担了在线存储的职责,服务了有赞用户,商品详情,订单详情等核心业务。
HBase 擅长于海量数据的实时读取,但软件世界没有银弹,原生 HBase 没有二级索引,复杂查询场景支持的不好。同时因为 split,磁盘,网络抖动,Java GC 等多方面的因素会影响其 RT 表现,所以通常我们在使用HBase的同时也会使用其他的存储中间件,比如 ES,Reids,Mysql 等等。避免 HBase 成为信息孤岛,我们需要数据导入导出的工具在这些中间件之间做数据迁移,而最常用的莫过于阿里开源的 DataX。Datax从 其他数据源迁移数据到 HBase 实际上是走的 HBase 原生 api 接口,在少量数据的情况下没有问题,但当我们需要从 Hive 里,或者其他异构存储里批量导入几亿,几十亿的数据,那么用 DataX 这里就显得不那么适合,因为走原生接口为了避免影响生产集群的稳定性一定要做好限流,那么海量数据的迁移就很很慢,同时数据的持续写入会因为 flush,compaction 等机制占用较多的系统资源。为了解决批量导入的场景,Bulkload 应运而生。
二、 Bulkload 技术简介
简单来说 Bulkload 就是利用 HBase 的数据信息按照特定格式存储在 HDFS 内这一原理,直接在 HDFS 中生成持久化的 HFile 数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。
Bulkload 的整体流程如下图所示
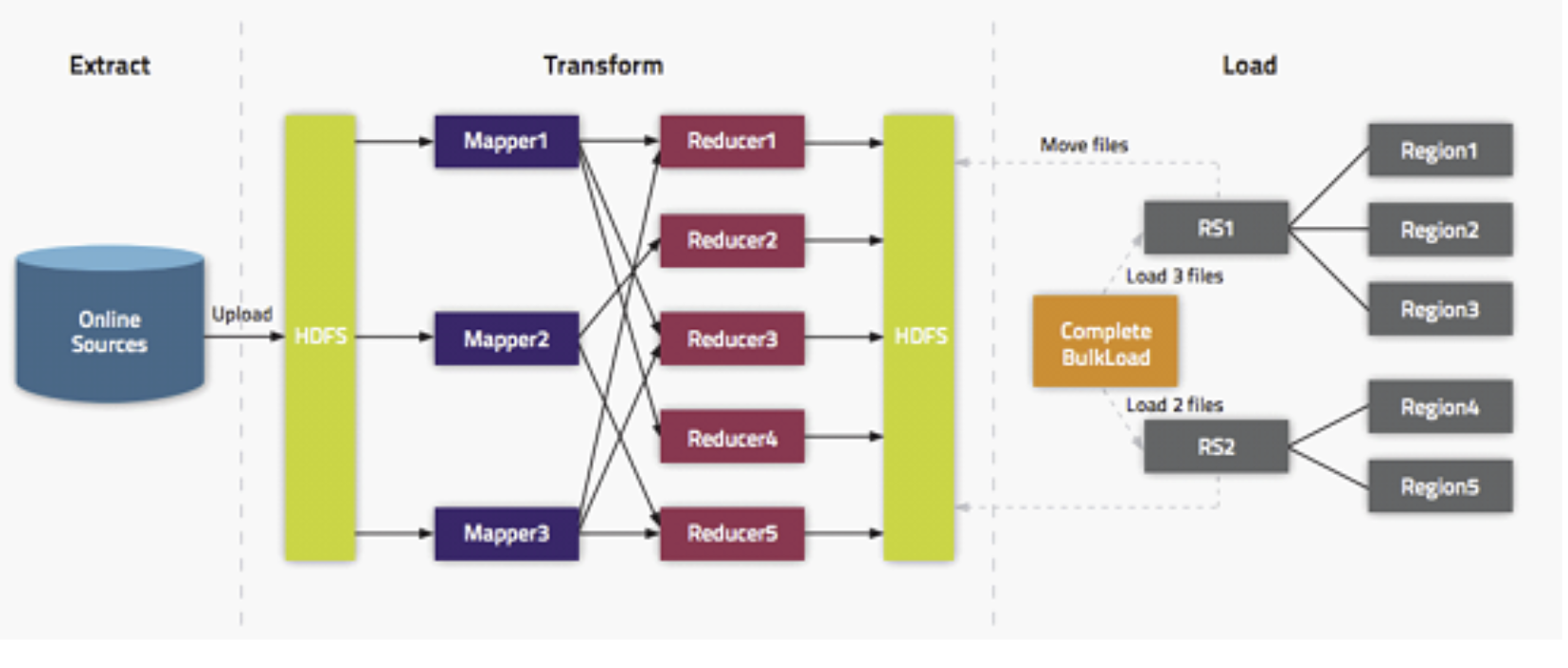
- Extract,异构数据源数据导入到 HDFS 之上。
- Transform,通过用户代码,可以是 MR 或者 Spark 任务将数据转化为 HFile。
- Load,HFile 通过 loadIncrementalHFiles 调用将 HFile 放置到 Region 对应的 HDFS 目录上,该过程可能涉及到文件切分。
三、 实践用法介绍
实现 Bulkload 方式最核心的点在于 Transform 层面的工作,而 Load 层面我们可以用 HBase 提供的 jar 包中的工具,Extract 层面也不是本章介绍的重点。
3.1 MR
可以通过自己写 MapReduce 任务去实现 Transform 层的逻辑,该方法的编写逻辑如下。
- 编写 mapper 类,该类最核心的工作是将 HDFS 上的其他数据格式转换成 HBase 的 Put 对象与对应的 rowkey。
- 编写 MapReduce Job 类,核心点需要通过 HFileOutputFormat 2配置 job。
- 运行 MR 任务。
3.2 Hive SQL
当我们需要从 Hive 数据导出到 HBase,可以通过写 Hive SQL 的方式生成 HFile,有赞在最开始便采用这一个版本,相比与 MR 任务,该方式有以下优点。
- 可以直接从 Hive 导出数据到 HBase,不用关心底层文件存储的格式信息。
- SQL 实现数据清洗与转换,表达能力强。
缺点
- 流程复杂,需要很多前置工作
- 底层依然是 MR 任务,由于前置工作整体执行时间可能会更长
- SQL 产出任务在指定 HFile 产出的分区之后可能会因为在某个分区 Hive 表没有数据而失败
3.3 Spark Bulkload
我们知道 Spark 在处理分布式任务上比 MR 快几个量级,同时不需要写复杂的 Mapper 与 Reducer 函数,只需要专注实现处理逻辑即可,所以我们可以不用再写MR任务来实现 Transform 的逻辑,转而用 Spark,同时还可以借住 Spark SQL 的能力直接实现 Hive 数据通过 SQL 生成 HFile。该方式相比 Hive SQL 方式并不需要做很多前置工作,同时更快更灵活。
优点
- 比 MR 执行的快。
- 可以借助 Spark SQL 完成从 Hive 的数据抽取与过滤。
- Spark 社区更加活跃,问题更容易找到解决方案。
缺点
- 配置相对复杂。
该方式也是本片文章介绍的重点,在网络上笔者也查过很多资料,但大多只是简单的例子,而生产环境适用的 Spark Bulkload 任务往往会遇到更多问题,在下面的章节会重点介绍Spark实现的流程以及我们踩过的坑,对每一个问题都给出我们的解决办法,如果读者恰好有相关的困扰,希望本篇文章会帮助到你。
四、 有赞 Bulkload 方式演进
有赞 Bulkload 主要经过两个比较大版本迭代,从 MR 到 Hive SQL, 再到 Spark 方案。这里我们主要介绍后面两个方案的实现原理与我们在生产实践过程中遇到的问题和对应的解决方案。
4.1 Hive SQL 方案
该方案复杂且在后续版本中废弃,如果读者不感兴趣可以直接跳到 Spark 方案
我们在开始引入的 DataX 可以做Hive等异构数据源导入到 HBase 的方案来解决数据迁移,而随着业务发展越来越多的业务比如算法的很多任务,他们会首先经过迭代计算将数据生成到 Hive 表里,为了可以实时读取这部分数据需要将数据导入到 HBase 线上集群,而这部分数据量级一般都在亿级别,此时再用 DataX 就不那么合适,所以为了解决 Hive -> HBase Bulkload 这个路径,我们研发了Hive SQL 的方案,此方案的执行流程图如下。
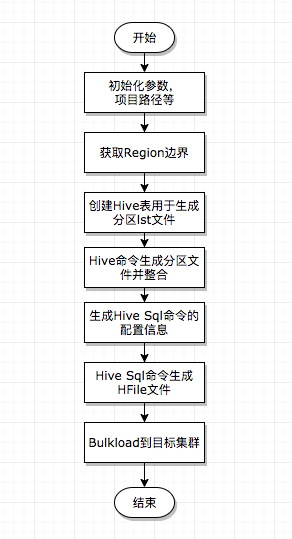
流程解析
- 必要的前置工作,检查hive表的读取权限,传参的表字段是否有差错。
- 获取 HBase 表的 Region 边界点,用于再之后 SQL 生成 HFile 时按照 Region 的区间,可以通过简单的 java 程序去读取表的信息实现。这一步至关重要,如果不按照表的分区生成 HFile,那么再最后的 Load 阶段,我们可以看到有大量的时间耗费在HFile split 的过程。
- 创建 Hive 表用来生成分区数据,注意,这里需要指定表的 location 属性,用于存放接下来要生成的 lst 分区文件。
- 生成分区文件。这一步稍微复杂,我们分流程叙述。
- 我们将第 3 步生成分区表标记为表 A ,将第2步生成的分区数据通过 Hive SQL 插入到一张临时表 A' 里,这两张表都只有一个字段 rowkey,类型为 String。
- 通过 insert overwrite table 命令将 A' 表中的数据插入到 A 中,此时在表 A 的 location 目录下可以生成若干分区文件。
- 把这些分区文件通过 cp -f 命令拷贝到 location 目录下的 xx.lst 文件中,这一步是必要的整合过程。
- 生成 HFile。
- 指定 reduce task 的个数为分区的个数。
- 指定 hive.mapred.partitioner 为 org.apache.hadoop.mapred.lib.TotalOrderPartitioner。
- 指定 total.order.partitioner.natural.order 为 false。
- 指定 mapreduce.totalorderpartitioner.path 为 location下的 xx.lst。
- 指定 hive.hbase.generatehfiles 为 true。
- 可以指定压缩属性为 lzo hfile.compression=lzo 以上的配置可以通过 set 命令在Hive执行命令前生效。
- 生成 HFile 的伪代码是 select [columns] from hive_table where 过滤条件 cluster by rowkey。 必须通过 cluster by 做全局排序,order by 这里不生效。
- 将生成的HFile文件distcp到线上集群并做Bulkload操作,如果提示找不到类的错误需要额外做一步
export HADOOP_CLASSPATH=`hbase classpath`。
这里需要强调下,因为 HFile 中数据必须保证有序,所以在 reduce 阶段保证写入的数据按照 rowkey,列族,标识符排好序,否则会报 "Added a key not lexically larger than previous" 的异常。
我们可以看出该实现流程比较复杂,为了能达到按照 Region 分区生成 HFile,达到比较好的 Bulkload 效率,我们做了额外很多工作。但这个版本在后续生产中给我们埋下了一个坑。看下面这个例子,假设我们获取的 Region 分区是 [1,3,5,7],如果 Hive 表里 rowkey 在 [3,5] 这个范围内没有数据,那么第 6 步 生成 HFile 就会报 FileNotFound 的异常,而这样的情况发生概率并不低。为了解决这个问题,我们在获取 Region 边界之后额外引入的一步,用来做 Region 边界的裁剪。简单就说就是先根据边界去并发的扫 Hive 表,如果这个边界内 Hive 表没有数据,那么就合并该边界。以上面的例子来说,如果 [3,5] 边界没有数据,最后生成的边界为 [1,3,7],此时还要考虑 3,7 这个区间内是否有数据,如果没有就合并成 [1,7],以此类推。 虽然可以解决这个异常,同时并发去扫描 Hive 数据来节约时间,但是这一检验的步骤仍然十分缓慢,所以这个方案在后来的迭代中彻底废弃掉。但这个方案并不是一无是处,我们通过 SQL 就可以生成 HFile,这显然是充满诱惑力的,没有特殊要求的可以只导出部分字段,那么在平台上配置下字段即可,有特殊的要求可以通过写 SQL 的 where 语句做过滤,这显然比 MR 更加灵活(前提是做好这些前置工作)。
4.2 Spark Bulkload
为了解决上述方案的痛点,我们决定用 Spark 技术栈重构掉上述方案,那么 Spark Bulkload 的代码执行流程是如何的,我们先给出泳道图。
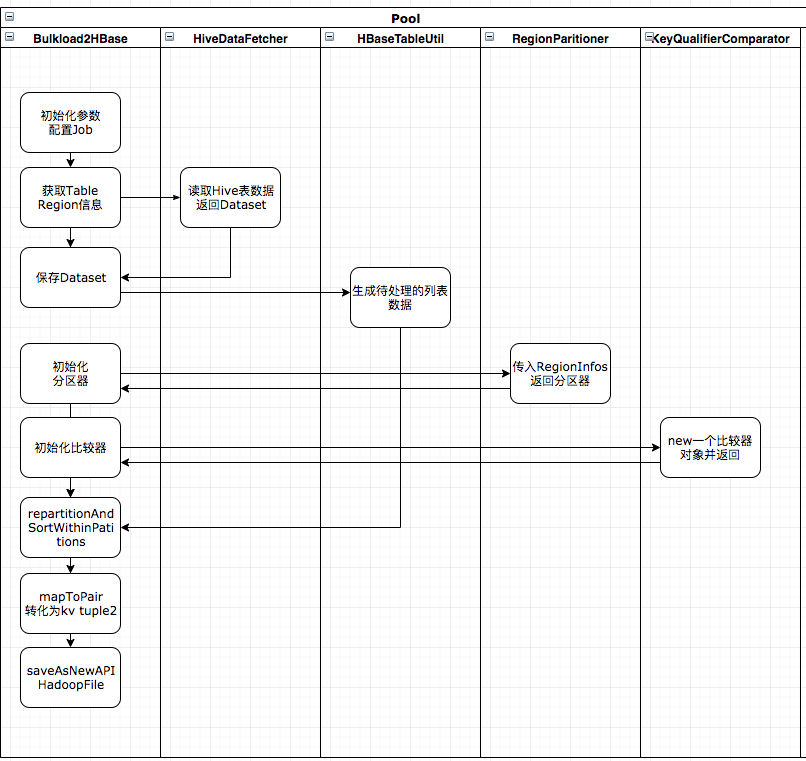 1. 获取 Table 的 Region 信息。
1. 获取 Table 的 Region 信息。
2. 根据配置生成 SQL 并通过 Spark SQL 生成 Dataset。
3. 创建一个 Partitioner 对象,getPartition 根据 rowkey 找到所属的分区的 index,这步比较关键。
4. 创建一个 Comparator,比较 rowkey 以及 cf:quafilier,下文会详细介绍。
5. 从 SQL 中一条条读取数据并根据逻辑过滤,返回一个 List<Tuple2<Tuple2<ImmutableBytesWritable,byte[]>, KeyValue>> 列表。
6. 调用 flatMapToPair 方法处理第 5 步生成的列表。
7. 调用 repartitionAndSortWithinPartitions 方法将传入 3,4 步创建好的 Partitioner 与 Comparator 对象,并调用 mapToPair 方法转为 Tuple2<ImmutableBytesWritable,KeyValue> 对象。
8. 调用 saveAsNewAPIHadoopFile 方法 保存为 HFile 文件。
下面详细介绍每一步之后的编码处理逻辑,我们为何要这样做。
1,2 两步骤略,第 3 步创建一个 Partitioner 的目的是为了第 7 步通过调用 repartitionAndSortWithinPartitions 来根据 table regions 的范围分区,同时一个分区对应 Spark 的一个 executor,简单来说让每一个分区数据有序,同时并发的处理多个分区可以增加处理效率,如果不做分区只做 sortBykey() 也可以实现,但是执行时间会极长。
第 4 步创建一个比较器的原因是同样是为了在调用 repartitionAndSortWithinPartitions 方法中指定比较策略,默认按照 key 排序。而这里笔者找了很多博客对排序这一步都语焉不详,在笔者最开始编码的时候,曾经尝试从 SQL 读出数据生成 List<Tuple2<ImmutableBytesWritable, KeyValue>> 列表,列表里保证 KeyValue 是按照列族,标识符排序好,但是在调用 repartitionAndSortWithinPartitions 方法之后,排序由于 shuffle 的原因重新变为乱序,最后的结果是笔者总会看到 rowkey 确实排序好了,但是依旧因为列族与标识符没排序好而抛出的 "Added a key not lexically larger than previous" IOException。这块笔者请教的负责维护 Spark 的同事,证实了当前调用场景下 shuffle 会影响排序的事实。
为了解决这个问题,我们实现的比较器不仅可以比较 rowkey,同时在 rowkey 相等的时候比较列族与标识符,保证 rowkey,列族,标识符三者按照此顺序关系一定有序。这也就是为什么第 5 步返回的是List<Tuple2<Tuple2<ImmutableBytesWritable,byte[]> , KeyValue>> 这样一个列表,返回这样的列表我们才可以按照上述所说进行排序,排序代码见第五节。
第 7,8 步是将排好序的数据写到 HDFS 生成 HFile 文件,具体的代码详见第五节示例代码。
4.3 Spark Bulkload常见错误解析
- 调用 saveAsNewAPIHadoopFile 方法抛出 "Added a key not lexically larger than previous" 的异常是因为排序问题导致,上文已经做了详细介绍。
- ImmutableBytesWritable 无法序列化的异常。通过如下 java 代码设置即可(读者可以用 scala 实现)
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); sparkConf.registerKryoClasses(new Class[] {org.apache.hadoop.hbase.io.ImmutableBytesWritable.class}); - 比较器无法序列化的异常。 让比较器实现 Serializable 接口即可。
- driver 中初始化的对象 于在 RDD 的 action 或者 transformation 中无法获取的异常,需要做 broadcast。
- 笔者还遇到因为 Spark 使用的 HBase 版本 jar 包冲突的问题,可以通过 Spark 命令中指定上传特定版本 jar 包覆盖的版本解决,具体命令在第五节给出。
- 可以通过动态设置 executor 个数来优化整体任务执行效率。
五、 核心示例代码
执行命令如下。
$SPARK_HOME/bin/spark-submit --master yarn --conf spark.executor.extraClassPath=hbase-hadoop-compat-1.2.6.jar:hbase-server-1.2.6.jar:hbase-common-1.2.6.jar:hbase-client-1.2.6.jar --conf spark.driver.extraClassPath=hbase-hadoop-compat-1.2.6.jar:hbase-server-1.2.6.jar:hbase-client-1.2.6.jar:hbase-common-1.2.6.jar --conf spark.dynamicAllocation.maxExecutors=100 --conf spark.dynamicAllocation.minExecutors=5 --conf spark.dynamicAllocation.enabled=true --files /opt/hive/conf/hive-site.xml,/opt/hbase/conf/hbase-site.xml,$hive_schema_file,$hbase_schema_file,/opt/hbase_bulkload/config.properties --executor-memory 8G --driver-memory 8G --name spark-hbase-bulkload-$hbase_table --class com.youzan.bigdata.BulkLoad2HBase --queue realtime.data_platform --jars $HBASE_HOME/lib/hbase-hadoop-compat-1.2.6.jar,/opt/hbase/lib/hbase-server-1.2.6.jar,/opt/hbase/lib/hbase-client-1.2.6.jar,/opt/hbase/lib/hbase-common-1.2.6.jar --deploy-mode cluster /opt/hbase_bulkload/spark-bulkload-hbase-1.0.0-SNAPSHOT-jar-with-dependencies.jar $hive_table $hbase_table $hbase_cluster $hive_schema_file $hbase_schema_file $bulkload_files_path
入参以及上传的文件可以忽略,读者根据自己的逻辑设计入参。--conf spark.dynamicAllocation.enabled=true 可以根据当前 Region 分区自动调节执行的 executor 个数。 上传的 jar 包为了解决版本冲突,通过 spark.executor.extraClassPath 与 spark.driver.extraClassPath 来配置。
Partitioner 代码如下 注意对key对象的处理,它是一个Tuple2<<ImmutableBytesWritable,byte[]>, KeyValue>>类型的对象。
public class RegionPartitioner extends Partitioner {
private List<HBaseTableInfo.RegionInfo> regionInfos = new LinkedList<>();
public RegionPartitioner(List<HBaseTableInfo.RegionInfo> regionInfos){
this.regionInfos = regionInfos;
}
@Override public int numPartitions() {
return this.regionInfos.size();
}
@Override public int getPartition(Object key) {
if(key instanceof ImmutableBytesWritable){
for(int i=0;i<regionInfos.size();i++){
if(regionInfos.get(i).containsRowkey(((ImmutableBytesWritable) key).get())){
return i;
}
}
}else if(key instanceof Tuple2){
if((ImmutableBytesWritable)((Tuple2) key)._1() instanceof ImmutableBytesWritable){
ImmutableBytesWritable rowkey = (ImmutableBytesWritable)((Tuple2) key)._1();
for(int i=0;i<regionInfos.size();i++){
if(regionInfos.get(i).containsRowkey(rowkey.get())){
return i;
}
}
}
}
return 0;
}
public static RegionPartitioner getRegionPartitioner(List<HBaseTableInfo.RegionInfo> regionInfos){
Collections.sort(regionInfos);
return new RegionPartitioner(regionInfos);
}
}
Comparator 代码如下。先比较 rowkey ,再比较列族+标识符。
public class KeyQualifierComparator implements Comparator<Tuple2<ImmutableBytesWritable,byte[]>>,Serializable {
@Override public int compare(Tuple2<ImmutableBytesWritable, byte[]> o1, Tuple2<ImmutableBytesWritable, byte[]> o2) {
if(o1._1().compareTo(o2._1()) == 0){
return Bytes.compareTo(o1._2(),o2._2());
}else{
return o1._1().compareTo(o2._1());
}
}
}
driver 端配置如下。
Job job = Job.getInstance();
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(KeyValue.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
//适配 hbase-1.3.0 的逻辑,这里需要zk传入job的configuration里,否则 HFileOutputFormat2.configureIncrementalLoad 会无法获取zk连接
job.getConfiguration().set(HConstants.ZOOKEEPER_QUORUM, zkQuorum);
Connection connection = ConnectionFactory.createConnection(hbaseConf);
RegionLocator regionLocator = connection.getRegionLocator(TableName.valueOf(hbaseTable));
Table table = connection.getTable(TableName.valueOf(hbaseTable));
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator);
将 SQL 返回的 Dataset 转为 List<Tuple2<Tuple2<ImmutableBytesWritable,byte[]>, KeyValue>> 对象的逻辑
public static List<Tuple2<Tuple2<ImmutableBytesWritable,byte[]>, KeyValue>> generateHBaseRowWithQualifier(Row sqlRow, List<String> columns) {
List<Tuple2<Tuple2<ImmutableBytesWritable,byte[]>, KeyValue>> result = new LinkedList<>();
//这里读者需要处理rowkey的位置,本源码这里略过很多处理逻辑,这不是重点
byte[] rowkey = Bytes.toBytes((String) sqlRow.get(0));
StructField[] fields = sqlRow.schema().fields();
Set<KeyValue> map = new TreeSet<KeyValue>(KeyValue.COMPARATOR);
for (int i = 1; i < sqlRow.size(); i++) {
//Rowkey必须是String类型
//hbase columns 格式为 cf:qualifier;type 这部分也是业务代码处理逻辑,读者需要自己根据业务逻辑实现
String family = columns.get(i - 1).split(";")[0].split(":")[0];
String qualifier = columns.get(i - 1).split(";")[0].split(":")[1];
String type = columns.get(i - 1).split(";")[1];
DataType dt = fields[i].dataType();
//convertValueToByteArray 方法将hive中的数据按照用户指定的数据类型做转化,这里就不再给出了。
KeyValue value =
new KeyValue(rowkey, Bytes.toBytes(family), Bytes.toBytes(qualifier), convertValueToByteArray(dt, sqlRow.get(i),type));
map.add(value);
}
for(KeyValue kv:map){
result.add(new Tuple2(new Tuple2<>(new ImmutableBytesWritable(rowkey),kv.getQualifier()), kv));
}
return result;
}
核心流程如下。
List<HBaseTableInfo.RegionInfo> regionInfos = admin.getTableRegions(TableName.valueOf(hbaseTable)).stream()
.map(HRegionInfo ->{
return new HBaseTableInfo.RegionInfo(hbaseTable,HRegionInfo.getStartKey(),HRegionInfo.getEndKey());
}).collect(Collectors.toList());
RegionPartitioner regionPartitioner = RegionPartitioner.getRegionPartitioner(regionInfos);
KeyQualifierComparator comparator = new KeyQualifierComparator();
rows.javaRDD().flatMapToPair(row -> HBaseTableUtil.generateHBaseRowWithQualifier(row,bcHbaseColumns.value()).iterator())
.repartitionAndSortWithinPartitions(regionPartitioner,comparator)
.mapToPair(combinekey -> {
return new Tuple2(combinekey._1()._1(),combinekey._2());
}).saveAsNewAPIHadoopFile(bulkloadFilePath,ImmutableBytesWritable.class,
KeyValue.class, HFileOutputFormat2.class, job.getConfiguration());
六、总结
经过最开始复杂的 Hive SQL 方式到后来的 Spark Bulkload 方式,离线数据批量导入到 HBase 的方案在有赞的实践就介绍到这里了。将来我们会针对性的对 Spark Bulkload 方案做进一步的优化,比如支持指定时间戳,增加更丰富的可配置的过滤器等等。同时希望 Spark Bulkload 方案能切实帮助读者解决生产上遇到的数据迁移问题,避免踩类似的坑。
最后打个小广告,有赞数据中台团队,主要负责有赞的数据基础组件,数据开发平台,数据资产治理平台等多个数据产品,提供一站式数据解决方案,欢迎感兴趣加入的小伙伴联系 zhaoyuan@youzan.com
参考
HBase 写优化之 BulkLoad 实现数据快速入库
使用 Bulk Load 快速向 HBase 中导入数据
