
1. 对比学习的引入
一般做算法任务时,都需要搜集大量标注的数据,假如我们要预测一个商品的产品词(中心词),下面是一个商品标题:
三亚亚龙湾玫瑰谷JESS玫瑰臻白颜透润花瓣 免洗面膜收缩毛孔
这个商品的产品词就是“面膜”,任务就是要把面膜识别出来,看起来是个标准的NER任务,我们也确实使用了CRF和指针网络之类的方法,对于上面这种标题效果还不错,但是由于SaaS商家的经营习惯不同于平台,很少依赖平台搜索流量,所以很多标题很简短甚至不会包含产品词,比如:
迪奥丝绒系列760 专属女团色 蓝调正红 可盐可甜
澳优能立多3段
对于这种问题,NER相关的算法就无解了,模型无法在商品标题中找到合适的产品词,当然也可以认为是标题中没有产品词。但是这种模型很多时候会从标题里预测出来奇奇怪怪的结果,导致产品词太发散,业务方很难基于产品词制定规则。
去年我们接触到了对比学习,被OpenAI的CLIP: Connecting Text and Images惊艳到了,效果之好,方法之简单,令人兴奋。而且微软相似的模型Turing Bletchley: A Universal Image Language Representation model by Microsoft - Microsoft Research甚至还展现了OCR的能力,再加上微博做的文本对匹配的效果,为我们打开了新的思路。如果利用对比学习学到商品标题和产品词的表示,那只需要清理一批产品词计算向量存到向量计算引擎,需要预测的商品标题计算完表示以后做一次向量召回就会得到语义相关的产品词,就算商品标题里不含产品词也可以找出一个合理的产品词,而且产品词词库可控,将会是一个理想的解决方案。
2. 对比学习的原理
对比学习的思想很简单,就是学习对象的表示(向量),相关对象的表示要接近,不相关对象的表示要远离。对比学习也算是自监督学习,跟其他方法的区别可以看下图,对比学习也是有label的,但是跟监督学习不同的是,这个label不是最终任务的label。
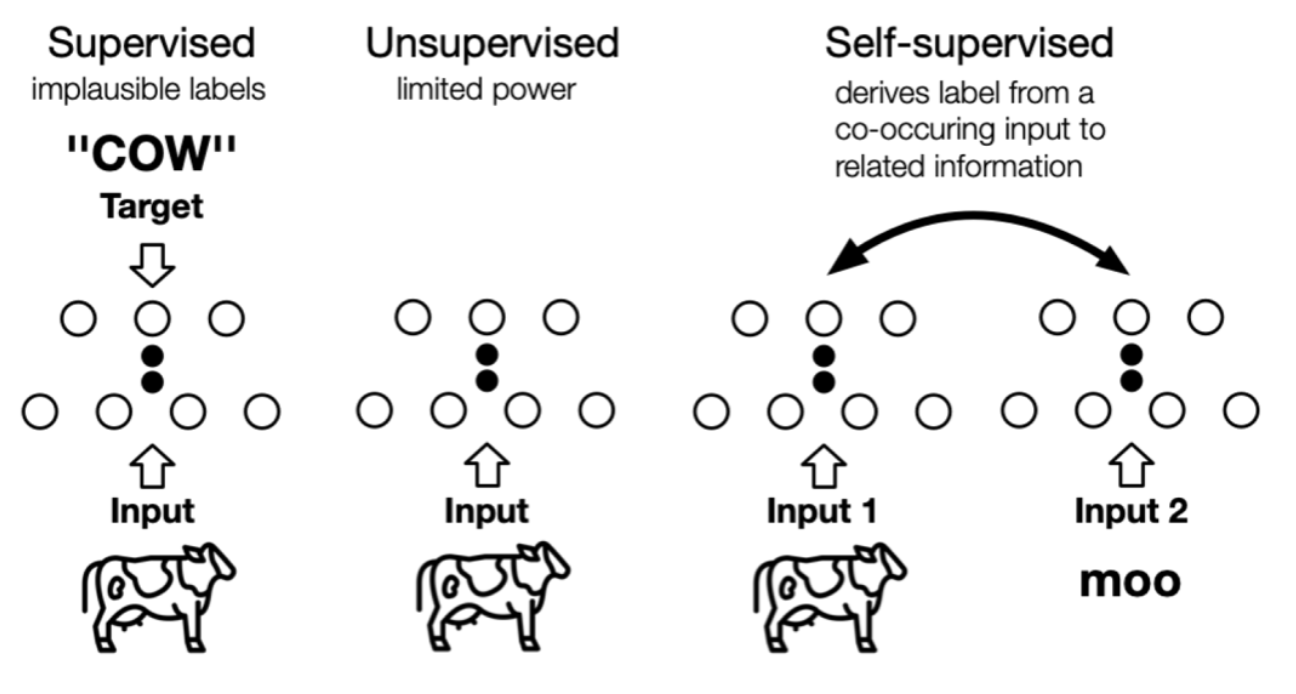
谷歌的FaceNet以及微软的DSSM等模型,也是这种思想。我们以人脸识别为例,如果使用监督学习的方式,任务就是基于人脸图片预测人的唯一ID。那就需要收集每个人很多张人脸照片(不同角度不同年龄不同光照等),这几乎无法实现。所以可行的方法就是让模型学会表示人脸,同一个人不同照片得到的表示接近,不同的人的照片表示不接近。FaceNet正是基于这种思想,使用Triplet Loss,拉近Anchor(用户A的照片1)与Positive(用户A的照片2)的距离,推远Anchor(用户A的照片1)与Negative(用户B的照片1)的距离,从而学会生成有区分度的人脸表示。这里每个样本中的负样本数量为1,即:(Q, P, N),这里用Q表示Anchor,P表示正样本,N表示负样本。DSSM中负样本的数量为4,即:(Q, P, N_1,N_2,N_3,N_4)。
从SimCLR到CLIP,再到最近大火的DALL·E 2,对比学习的潜力被大量开发,文本与文本的对比,图像与图像的对比,文本与图像的对比,效果都非常好,而且最重要的是,工业界落地容易,只要提前计算好向量表示就可以实时推理。
2.1 损失函数
我们来看看对比学习是怎么训练的,负样本的数量对模型效果的影响还是很大的,SimCLR文章给出了batch_size(可以理解为负样本数量)与模型效果的关系:
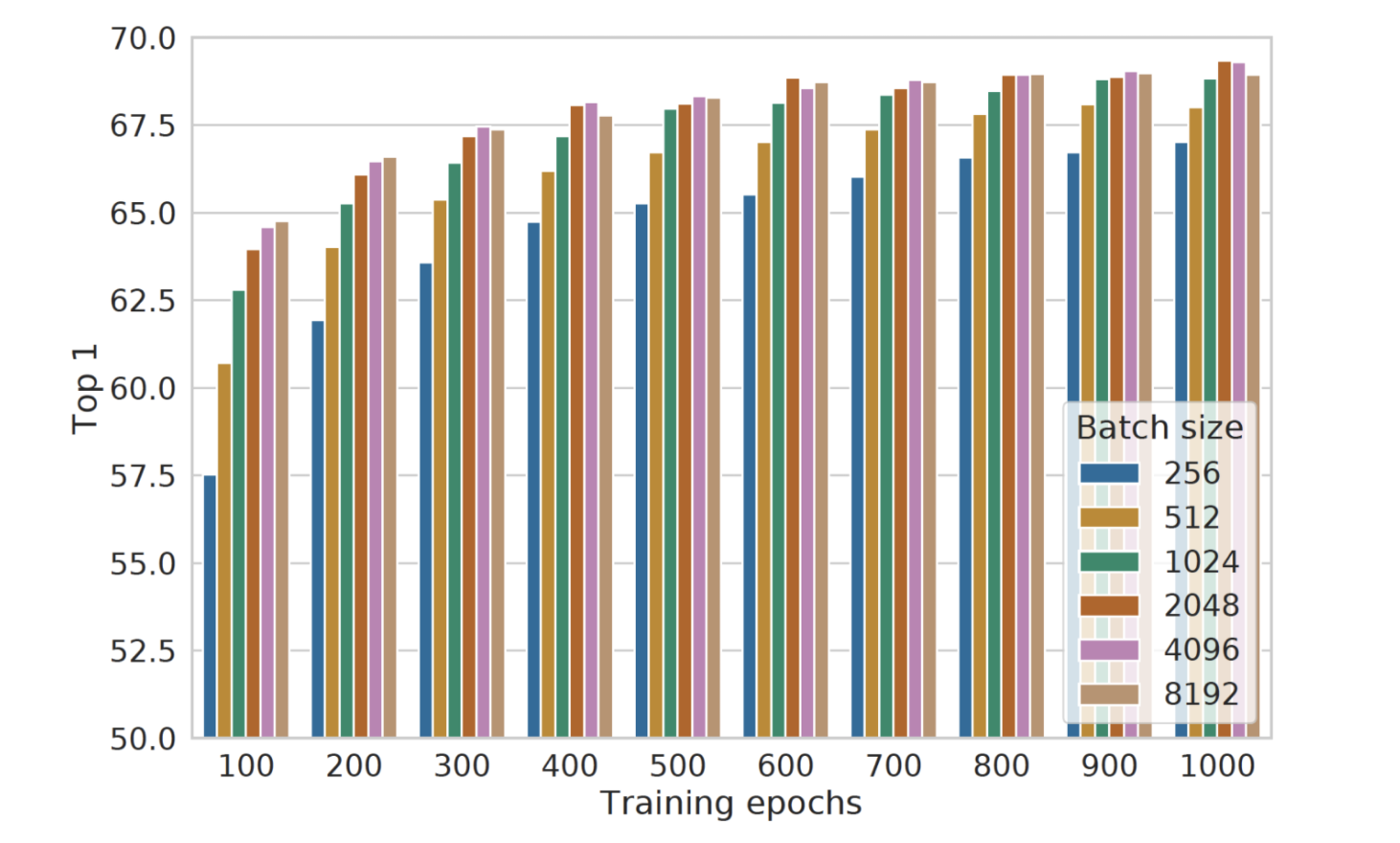
上面我们提过FaceNet一个负样本,DSSM4个负样本,而CLIP的负样本数量达到了32767, 这么多的负样本就是用来计算损失的,损失函数为infoNCE,形式如下:
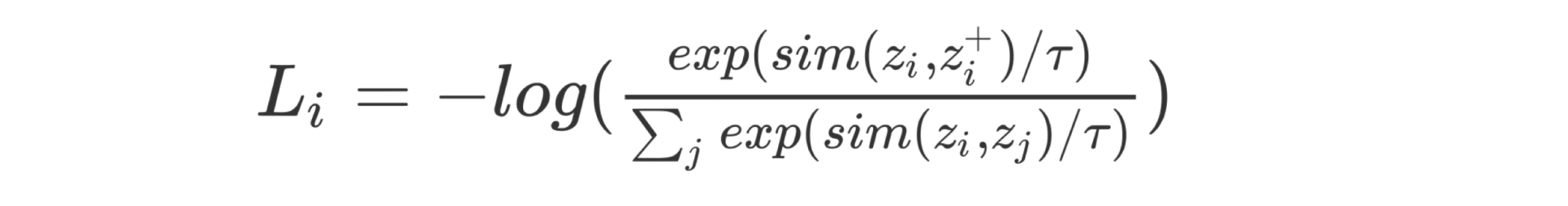
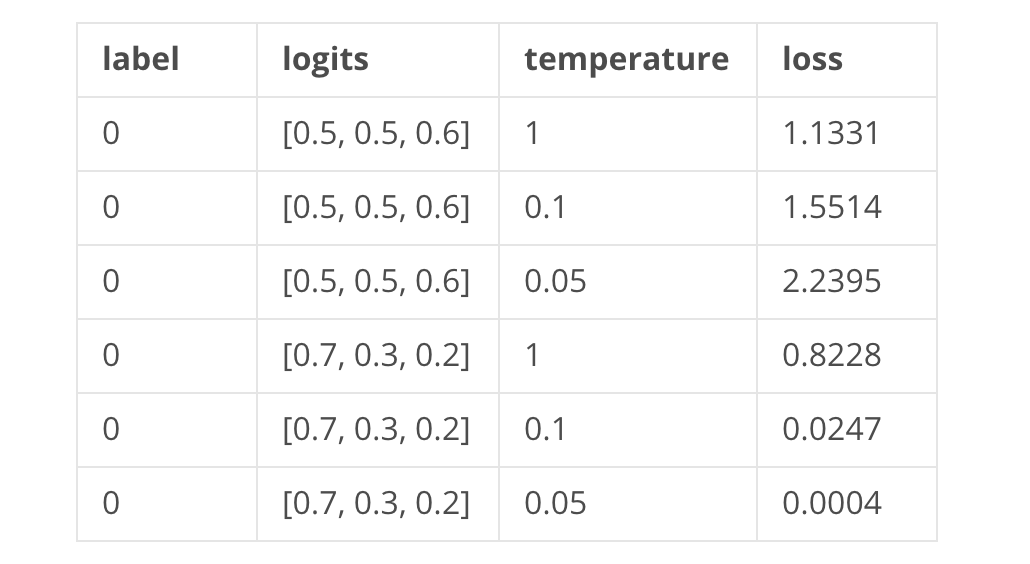
sim(x, y)代表两个表示的相似度,可以是余弦相似度(一般模型最后一层会是L2归一化,所以余弦相似度 sim(x, y) 的结果在-1到1之间)。τ为温度超参,如果τ为1,sim(x, y)看做logits,那就是个标准的交叉熵。一般交叉熵我们用于分类任务,这么说的话对比学习也算一种分类任务。
以下图为例,这组样本可以表示为:(Q, P, N_1, N_2),即有两个负样本,模型会计算出sim(Q, P),sim(Q, N_1), sim(Q, N_2),为了最大化sim(Q, P)这一“类别”的概率,我们可以认为该样本的one-hot label是[1, 0, 0]。如果我们按照(Q, P, N_1, N_2)的方式准备所有训练数据,那每个样本的label就都是[1, 0, 0],而且损失函数是交叉熵,形式上已经是分类任务了,不同的是,这个“类别”没有实际意义。从另外一个角度想,分类任务可以看到所有的负样本(所有的类别),而对比学习只能看到有限的负样本,所以负样本越多学习难度会越大,训练出来的模型更稳健。
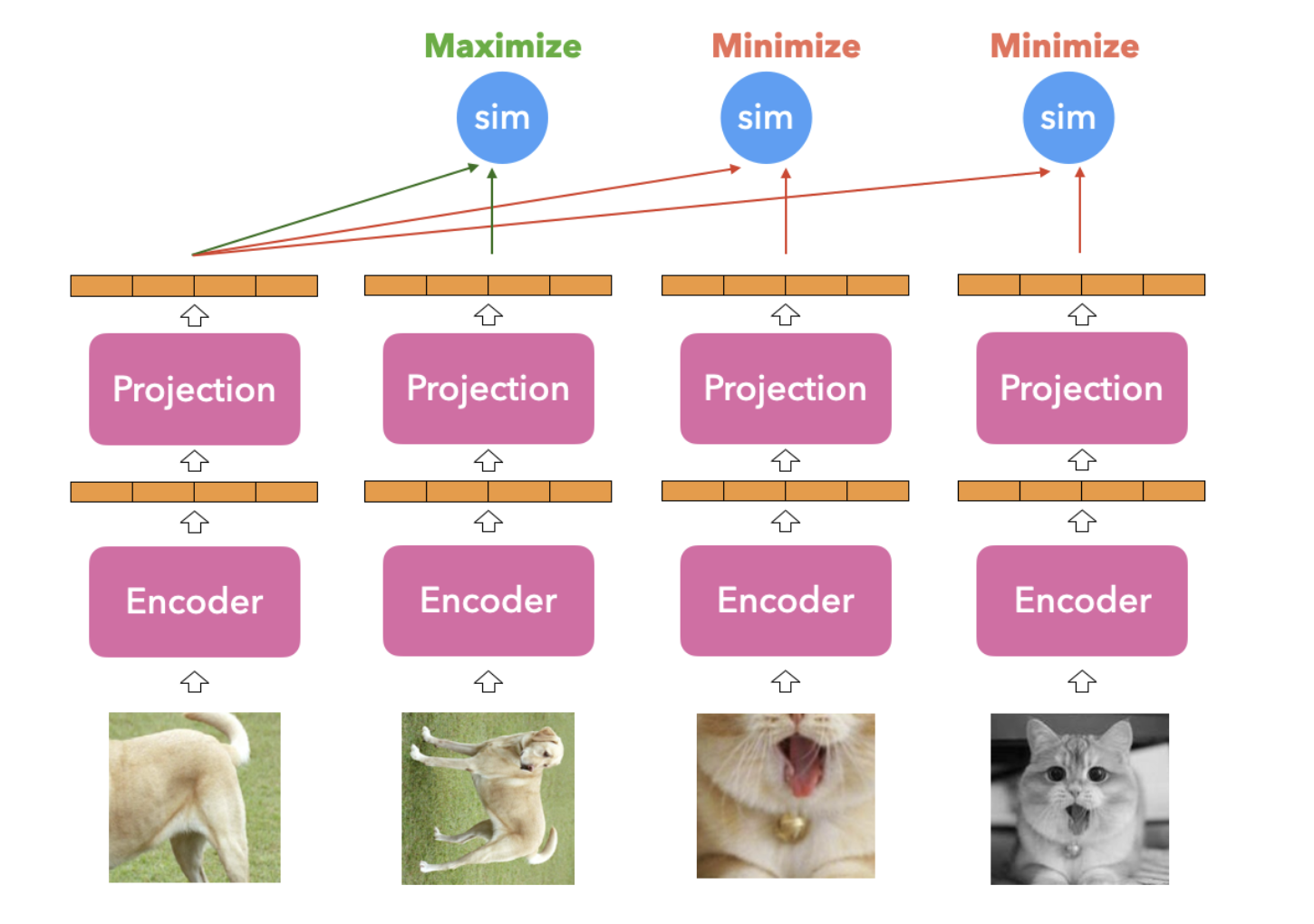
2.2 Batch内负采样
如果像上图一样,每条训练数据中都提前准备好若干个负样本(可以全局负采样),假设两个负样本,即(Q, P, N_1, N_2),当按batch训练时,需要分别计算batch_Q, batch_P, batch_N1, batch_N2的向量表示,然后再计算对比损失,计算量非常大,而且负样本数量越多训练越慢。所以一种经典的方法就是batch内负采样,训练数据只需要是(Q, P),实际计算时,一个batch内的其他Q对应的P就可以作为当前Q的N,前向计算只需要计算batch_Q和batch_P,只需要提高batch_size就可以增加负样本数量。
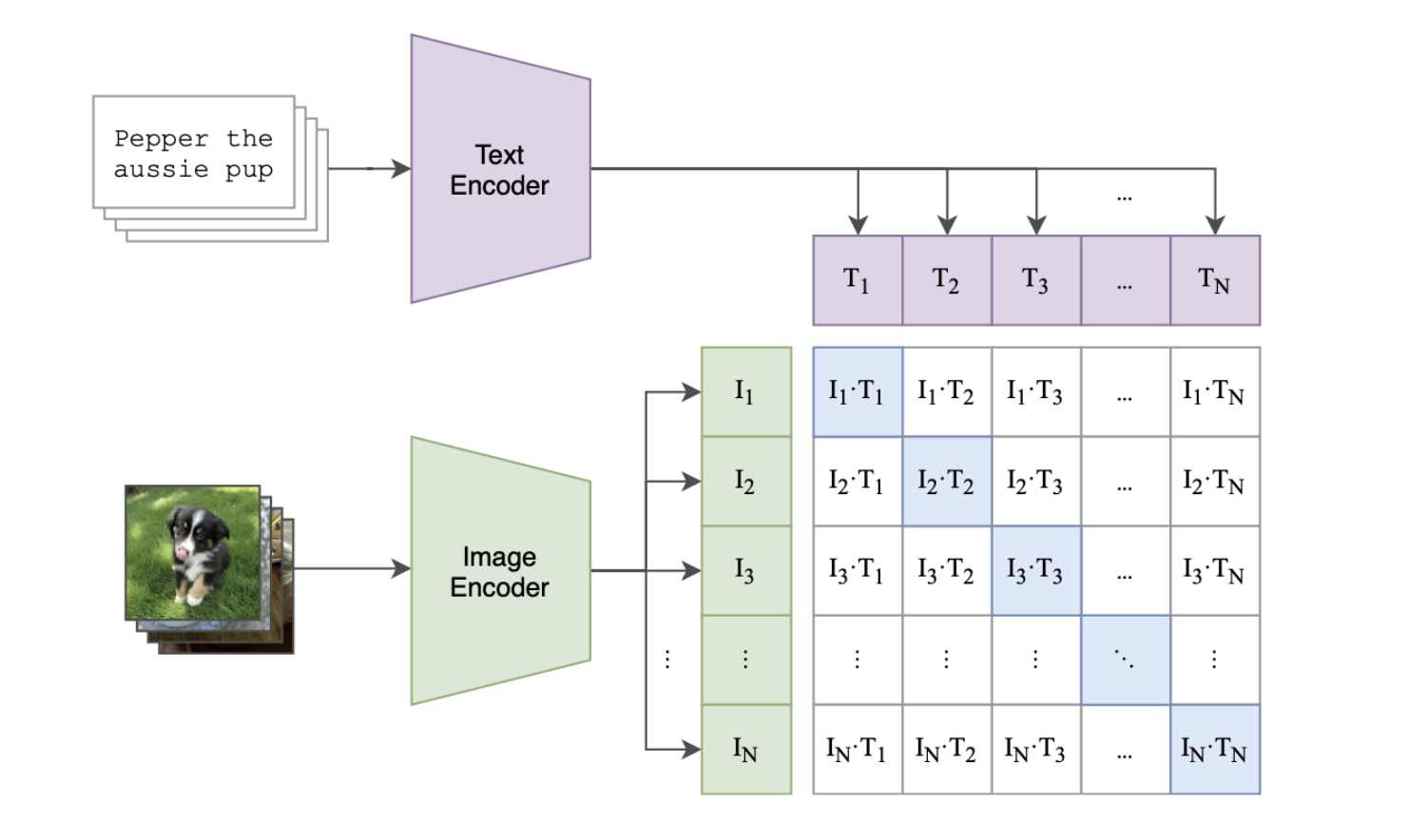
用CLIP的图来解释batch内负采样的计算过程,如下图所示,batch文本经过Text Encoder得到batch_size * dim的矩阵,记做ET,也就是图里T_1, T_2, ...,T_N的向量表示。batch图像经过Image Encoder得到batch_size * dim的矩阵,记做EI,进行矩阵乘法 ET * transpose(EI)后就得到batch_size * batch_size的相似度方阵,对角位置就是相关的文本和图像的相似度,即 sim(Q, P),其他位置就是不相关的文本和图像的相似度 sim(Q, N),所以这个batch的稀疏label就是(0,1,2,...,batch_size-1)。有了logits和label就可以使用infoNCE计算损失函数。
3. 模型设计
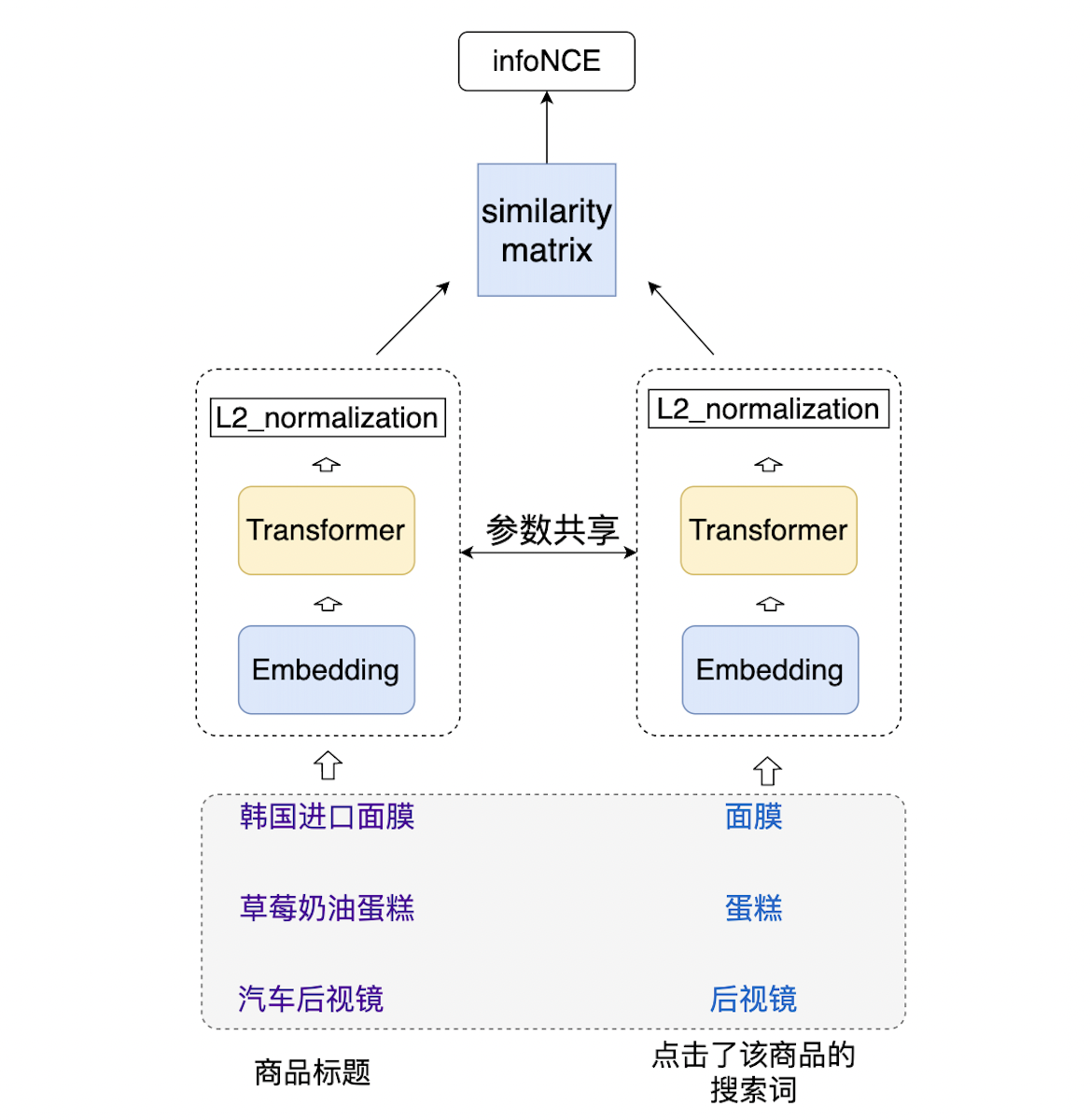
在我们决定尝试用对比学习(语义匹配)的方式做商品的产品词预测时,就想到了用搜索点击数据训练模型。搜索日志数据量非常大且容易获取,搜索点击是一种弱监督的数据,包含用户对query和商品相关性的认可,虽然包含很多噪声,但是数据量大的情况下模型有能力学会忽略这些噪音,反而有可能增加模型的稳健性。所以我们的训练数据(Q,P)就是(query,goods_info),goods_info可以只是简单的使用商品标题,也可以加入其他信息如店铺名,商品类型,商品描述等等。
模型设计为经典的双塔结构,由于商品搜索点击的query和goods_info分布上很接近,所以双塔的结构和参数完全共享,也就是一个塔用两次。
当goods_info 包含商品标题外的其他信息时,使用segment_id区分。这里我们输入的序列长度是100,embedding维度为512,6层Transformer encoder layer,总参数量17M,只使用6层transformer是基于线上服务性能考虑,独占单卡,100并发,可以达到60ms的RT和1500的QPS,且现有两层transformer的模型表现也不错,6层目前来说是比较经济的选择。
4. 训练技巧
4.1 温度超参
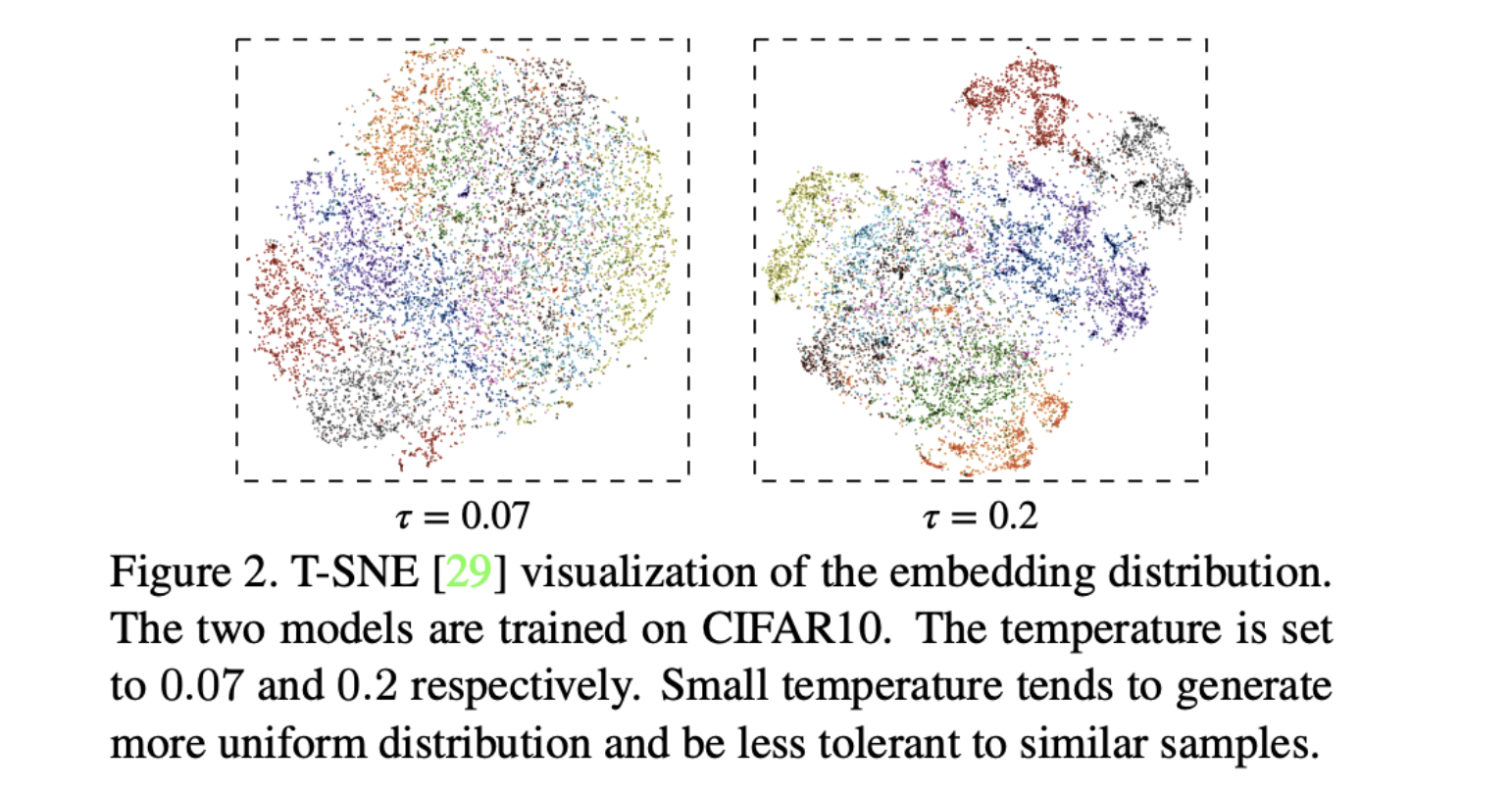
infoNCE相对于crossEntropy多出来的温度超参τ,按照Understanding the Behaviour of Contrastive Loss中的解释,具有控制表示分布的能力,小的温度超参学习出来的分布更加均匀,大的温度超参学习出来的分布类间更加远离,如下图:
CLIP中将温度超参设置为可学习的参数,我们也曾尝试过,但是模型学习到最后,为了loss继续降低,会“偷懒”将温度参数设置的很小,之前训练得到过0.0037这么小的温度参数,当模型有分辨能力后,过小的温度超参会阻碍模型表示能力的进一步提高,如下图所示,所以最终训练时,我们还是使用了常数0.1作为温度超参的值。
4.2 分布式训练
由于对比学习对负样本的依赖,理论上负样本越多模型的表示能力越稳健,使用batch内负采样的技术需要增加batch_size以增加负样本数量,而batch_size的大小受限于显卡的显存。那既然一张卡的显存有限,使用多个机器的多张卡一起训练呢?不仅可以增加batch_size,还能提高训练速度,于是我们设计了多机多卡的训练方案,如下图所示:
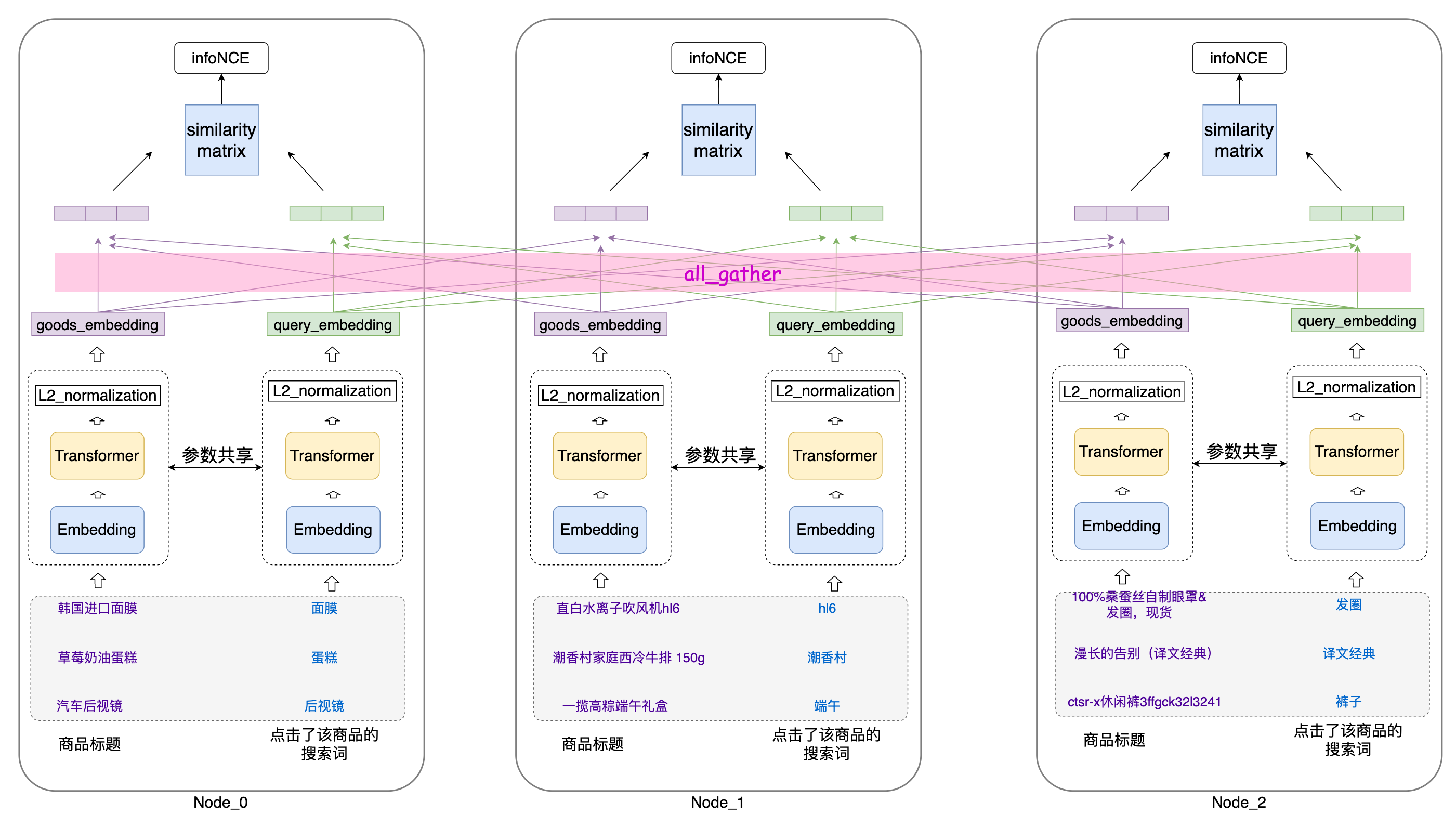
这里以三个节点为例,每个节点为一台单卡的机器,当模型前向计算出goods_embedding和query_embedding时,对于单机就可以直接计算相似度矩阵了,但是为了获得更大的相似度矩阵,我们使用all_gather操作,将其他节点的goods_embedding和query_embedding收集过来,拼成更大的embedding矩阵再计算相似度,原来单机的相似度矩阵维度为(batch_size, batch_size),这里分布式的相似度矩阵会增加为(batch_size * num_node,batch_size * num_node),如果单机最大batch_size是500,三台分布式训练batch_size(all_gather后)就可以达到1500。只要增加节点就可以增加负样本数量,分布式训练看起来挺适合对比学习。
实际训练时我们使用5台机器做分布式训练,将训练数据切分为5份,每台机器读取一份,训练框架使用Pytorch Lightning。
4.3 一些节省显存的技巧
分布式训练靠多台机器增加batch_size,单节点的batch_size可以靠优化模型训练时的显存占用提高。根据ZeRO里的说明,模型在GPU上训练时,显存中会存在模型的参数、各层的激活值、优化器的状态、梯度等,要减少显存占用就要想办法优化这些数据的显存开销。
4.3.1 ZeRO
ZeRO就是基于分布式提出的节省单节点显存的方案,一般分布式每个节点都存储着完整的模型数据(模型参数、优化器的状态、模型的梯度、前向计算的激活值等),如果将优化器的状态参数拆分,保存在每个节点上,每个节点只维护部分参数,那单个节点的显存占用会显著下降,同样的,梯度,参数都分布式保存,显存占用会极大的得到优化。
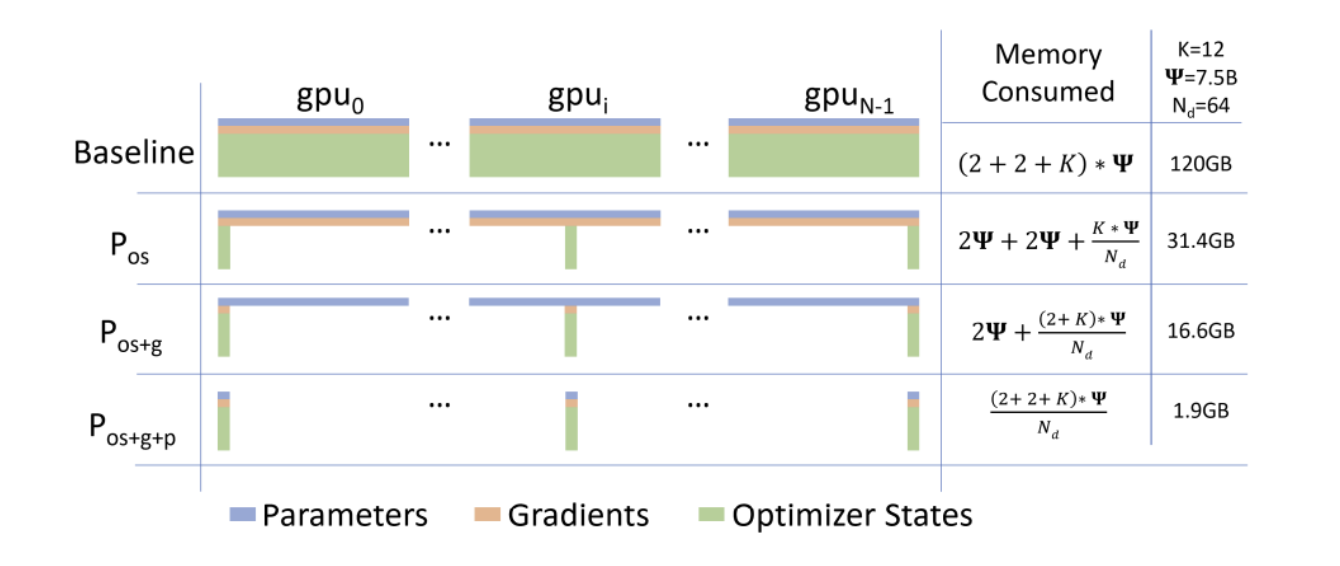
我们使用Pytorch Lightning中的ddp_sharded,即将优化器的状态参数和模型的梯度分布式保存在每个节点上,详细说明参见官方文档。
4.3.2 Activation Checkpointing
Activation Checkpointing也叫Gradient Checkpointing或者重计算技术。模型训练前向计算时,每层的计算结果(激活值)都会保存,方便反向传播时更新梯度,当batch_size增加时,其占用的显存将非常大,而Activation Checkpointing的思想就是部分层的计算结果不保存,当反向传播到这层时,重新前向计算这一层的激活值,再进行梯度更新,会增加一些训练时间,但是可以节省很多显存,如图,反向传播要等重计算完成:
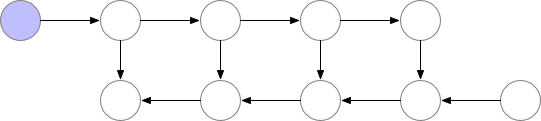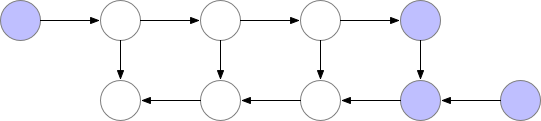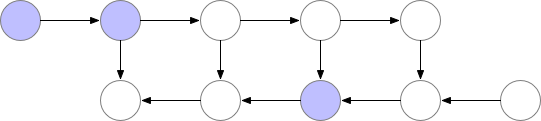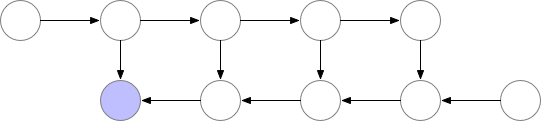
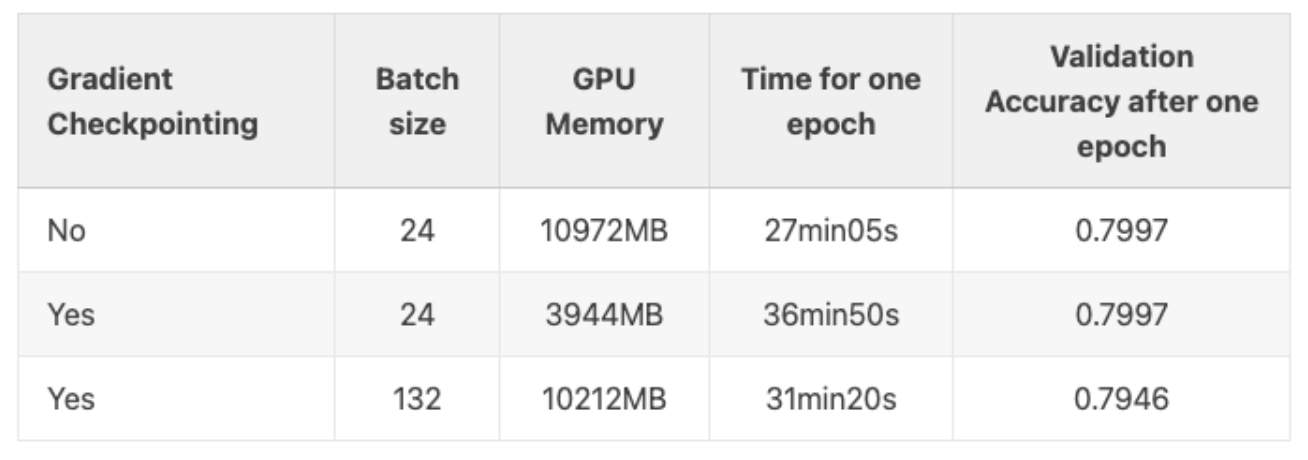
根据网上的测试,使用Activation Checkpointing可以减少约60%的显存占用,同时增加约25%的训练时间,这对显存紧张的我们来说无疑是很划得来的。而且很重要的一点是,对模型训练的精度没有影响:
陈天奇大佬2016年提出了这个方法,那个时候BERT还没出呢,详细见大佬论文Training Deep Nets with Sublinear Memory Cost 。
我们的模型开发由Tensorflow迁移到Pytorch,也有Pytorch官方自带这个功能torch.utils.checkpoint.checkpoint的原因,不过需要尽量避免重算dropout层。具体实现时,我们继承TransformerEncoderLayer类,将MultiheadAttention层改为允许重计算的层。
4.3.3 Mixed Precision
混合精度训练(Mixed Precision Training)是指模型训练时,模型权重和激活值以FP16存在,在有Tensor Core的GPU上可以加速,FP16也可以节省显存。虽然在前向和反向传播时使用FP16,但在更新权重的时候还会使用FP32。
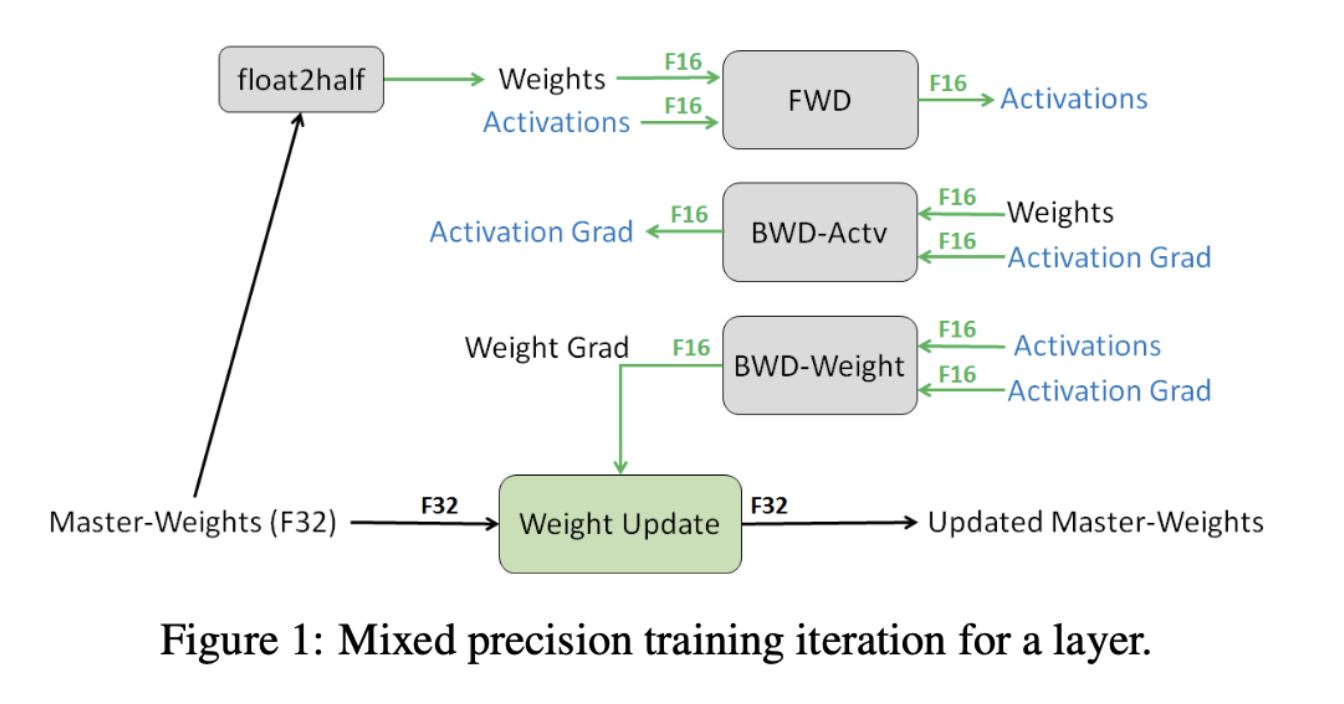
实际测试中,大约可以节省30%的显存,节约50%的训练时间。
4.3.4 训练配置
使用上面提到的这些优化显存占用的方法,单卡显存占用可以节约55%,16G显存的GPU可以放下700的batch_size,5个节点,最终计算对比损失时的batch_size可以达到3500。(但是要注意batch_size也不是越大越好,当你的训练数据多样性不足而batch_size较大时,会引入较多False Negative,即其他Q的P与当前Q也是语义上相近的,但是计算loss时却是当作负样本处理的,有点类似于做分类时有类别重复)
我们总共收集184M的搜索点击加购日志,5台GPU机器分布式训练,计算loss的相似度矩阵大小是3500*3500,温度超参为0.1。
5. 效果
我们提前整理了一个产品词词库,用来做向量匹配,来看一下效果:
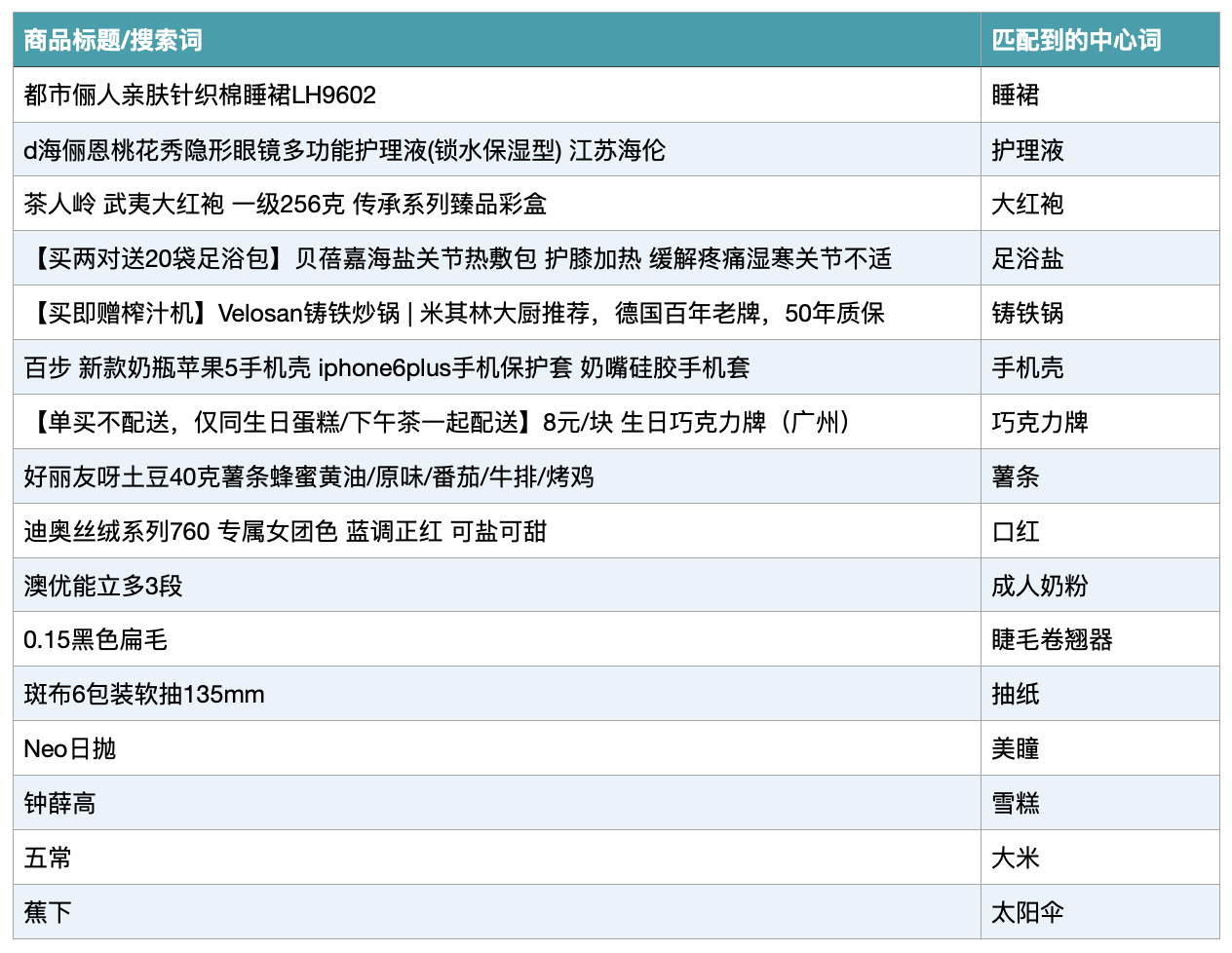
只要商品标题里出现了产品词,预测起来是比较容易的,标题中出现多个产品词时,模型也有能力找出最合适的那个(不过也有badcase,比如“足浴盐”),当标题中没有产品词时,也可以通过向量匹配的方式找一个合理的产品词,这是之前的NER方案完全不能处理的。而且可以通过卡阈值的方式找出词库中语义相近的产品词。
用来匹配文案效果也不错:
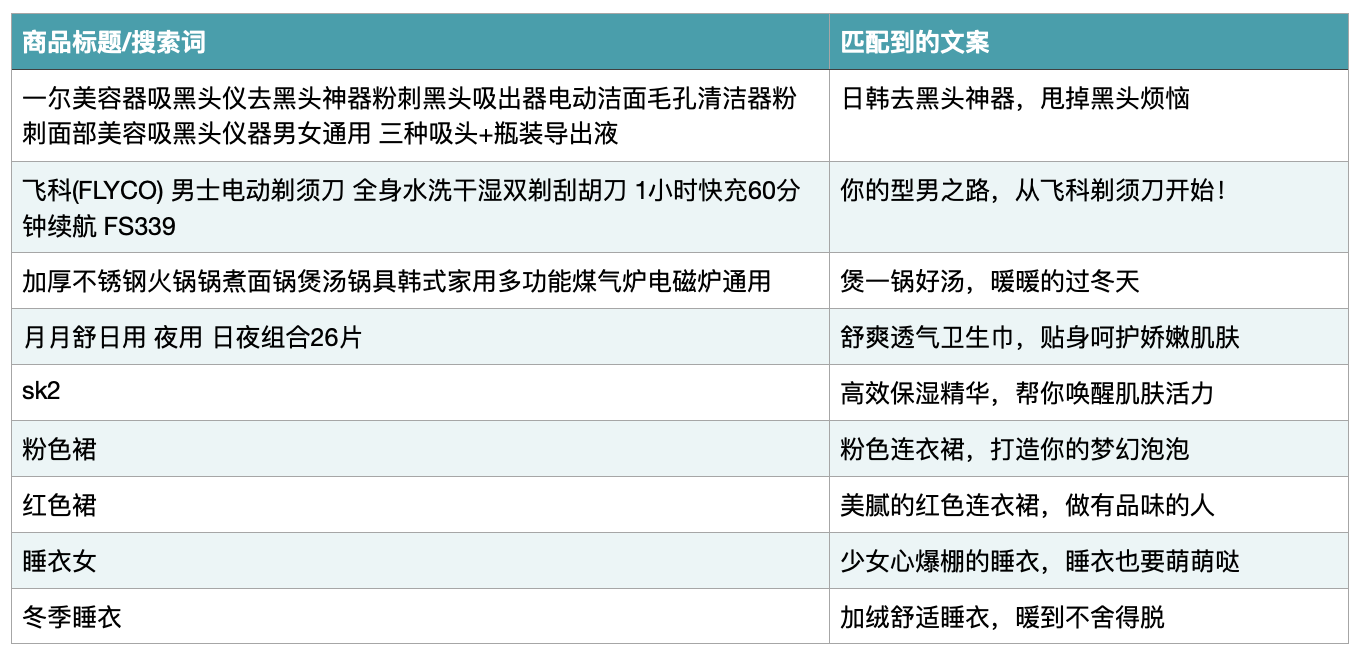
而且测试还发现,属性信息也被编码进了表示中,可以区分品牌、颜色、男女、季节等。
再来一个更有挑战的任务:匹配类目。由于类目文本的形式是:一级类目名>二级类目名>三级类目名>... 这种形式与搜索词和商品标题偏差较大,正好可以测试一下模型的泛化能力:
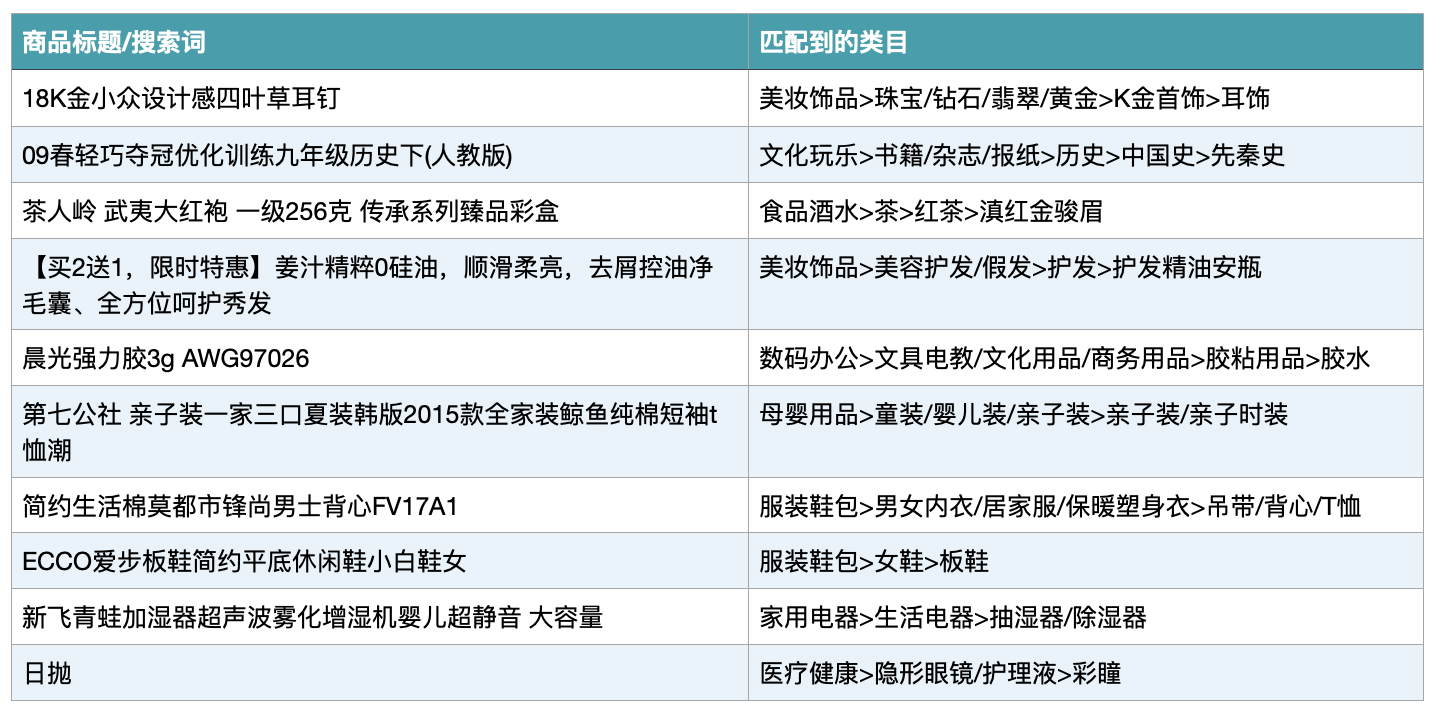
可以看出就算类目文本和训练数据分布不一致,模型也有能力做出预测,叶子类目预测的效果也超出预期,这是Zero-shot的效果,非常令人兴奋。想想之前如果要做文本分类,我们需要标注大量数据,加上类目体系庞大,要取得好的效果需要花费大量资源,有了对比学习,就不用从0分学起了,上来就是60分,只需要少量的标注数据,就可以达到令人满意的效果。人工智能终于可以不用那么人工了,大数据的优势也体现出来了。
商品文本编码可以使用商品搜索日志训练,类似的,图像的编码器可以通过商品标题与商品图片的相关性学习出来。至此,我们就拥有了商品文本和图像各自的编码器,可以做文本和文本的匹配,文本和图像的匹配,图像和图像的匹配。
图文匹配的CLIP模型已经开源,可以在这里找到https://huggingface.co/youzanai/clip-product-title-chinese
6. 应用
基于对比学习预训练加微调和向量召回的方案,目前已经在有赞的商品产品词预测、商品类目预测、相似商品推荐、搜索召回、搜索排序、智能文案、商品风控等场景上线使用,稳健性都要好于之前纯有监督的方案。
可以说,有了对比学习这个强力工具,以前做不了的都可以做了,思路都打开了。对比学习,真的大有可为。
