
一、需求
有赞大数据技术应用的早期,我们使用 Sqoop 作为数据同步工具,满足了 MySQL 与 Hive 之间数据同步的日常开发需求。
随着公司业务发展,数据同步的场景越来越多,主要是 MySQL、Hive 与文本文件之间的数据同步,Sqoop 已经不能完全满足我们的需求。在2017年初,我们已经无法忍受 Sqoop 给我们带来的折磨,准备改造我们的数据同步工具。当时有这么些很最痛的需求:
- 多次因 MySQL 变更引起的数据同步异常。MySQL 需要支持读写分离与分表分库模式,而且要兼容可能的数据库迁移、节点宕机以及主从切换
- 有不少异常是由表结构变更导致。MySQL 或 Hive 的表结构都可能发生变更,需要兼容多数的表结构不一致情况
- MySQL 读写操作不要影响线上业务,不要触发 MySQL 的运维告警,不想天天被 DBA 喷
- 希望支持更多的数据源,如 HBase、ES、文本文件
作为数据平台管理员,还希望收集到更多运行细节,方便日常维护:
- 统计信息采集,例如运行时间、数据量、消耗资源
- 脏数据校验和上报
- 希望运行日志能接入公司的日志平台,方便监控
二、选型
基于上述的数据同步需求,我们计划基于开源做改造,考察的对象主要是 DataX 和 Sqoop,它们之间的功能对比如下
| 功能 | DataX | Sqoop |
|---|---|---|
运行模式 |
单进程多线程 |
MapReduce |
MySQL读写 |
单机压力大;读写粒度容易控制 |
MapReduce 模式重,写出错处理麻烦 |
Hive读写 |
单机压力大 |
扩展性好 |
文件格式 |
orc支持 |
orc不支持,可添加 |
分布式 |
不支持,可以通过调度系统规避 |
支持 |
流控 |
有流控功能 |
需要定制 |
统计信息 |
已有一些统计,上报需定制 |
没有,分布式的数据收集不方便 |
数据校验 |
在core部分有校验功能 |
没有,分布式的数据收集不方便 |
监控 |
需要定制 |
需要定制 |
社区 |
开源不久,社区不活跃 |
一直活跃,核心部分变动很少 |
DataX 主要的缺点在于单机运行,而这个可以通过调度系统规避,其他方面的功能均优于 Sqoop,最终我们选择了基于 DataX 开发。
三、前期设计
3.1 运行形态
使用 DataX 最重要的是解决分布式部署和运行问题,DataX 本身是单进程的客户端运行模式,需要考虑如何触发运行 DataX。
我们决定复用已有的离线任务调度系统,任务触发由调度系统负责,DataX 只负责数据同步。这样就复用了系统能力,避免重复开发。关于调度系统,可参考文章《大数据开发平台(Data Platform)在有赞的最佳践》
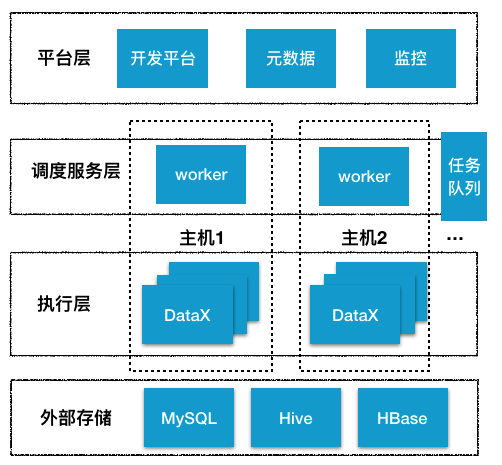
DataX在有赞大数据平台的上下文
在每个数据平台的 worker 服务器,都会部署一个 DataX 客户端,运行时可同时启动多个进程,这些都由调度系统控制。
3.2 执行器设计
为了与已有的数据平台交互,需要做一些定制修改:
- 符合平台规则的状态上报,如启动/运行中/结束,运行时需上报进度,结束需上报成功失败
- 符合平台规则的运行日志实时上报,用于展示
- 统计、校验、流控等子模块的参数可从平台传入,并需要对结果做持久化
- 需要对异常输入做好兼容,例如 MySQL 主从切换、表结构变更
3.3 开发策略
大致的运行流程是:前置配置文件转换、表结构校验 -> (输入 -> DataX 核心+业务无关的校验 -> 输出) -> 后置统计/持久化
尽量保证 DataX 专注于数据同步,尽量不隐含业务逻辑,把有赞特有的业务逻辑放到 DataX 之外,数据同步过程无法满足的需求,才去修改源码。
表结构、表命名规则、地址转换这些运行时前置校验逻辑,以及运行结果的持久化,放在元数据系统(参考《有赞数据仓库元数据系统实践》),而运行状态的监控放在调度系统。
四、源码改造之路
4.1 支持 Hive 读写
DataX 并没有自带 Hive 的 reader 和 writer,而只有 HDFS 的 reader 和writer。我们选择在 DataX 之外封装,把 Hive 读写操作的配置文件,转换为 HDFS 读写的配置文件,另外辅助上 Hive DDL 操作。具体的,我们做了如下改造:
4.1.1 Hive 读操作
- 根据表名,拼接出 HDFS 路径。有赞的数据仓库规范里有一条,禁止使用外部表,这使得 HDFS 路径拼接变得容易。若是外部表,就需要从元数据系统获取相应的路径
- Hive 的表结构获取,需要依赖元数据系统。还需对 Hive 表结构做校验,后面会详细说明
4.1.2 Hive 写操作
- 写 Hive 的配置里不会指定 Hive 的文件格式、分隔符,需要读取元数据,获取这些信息填入 HDFS 的写配置文件
- 支持新建不存在的 Hive 表或分区,能构建出符合数据仓库规范的建表语句
4.2 MySQL -> Hive兼容性
按 DataX 的设计理念,reader 和 writer 相互不用关心,但实际使用经常需要关联考虑才能避免运行出错。MySQL 加减字段,或者字段类型变更,都会导致 MySQL 和 Hive 的表结构不一致,需要避免这种不一致的运行出错。
4.2.1 MySQL -> Hive 非分区表
非分区表都是全量导入,以 mysqlreader 配置为准。如果 MySQL 配置字段与 Hive 实际结构不一致,则把 Hive 表 drop 掉后重建。表重建可能带来下游 Hive SQL 出错的风险,这个靠 SQL 的定时检查规避。
Hive 表重建时,需要做 MySQL 字段转换为 Hive 类型,比如 MySQL 的 varchar 转为 Hive 的 string。这里有坑,Hive 没有无符号类型,注意 MySQL 的 int unsigned 的取值范围,需要向上转型,转为 Hive 的 bigint;同理,MySQL 的 bigint unsigned 也需要向上转型,我们根据实际业务情况大胆转为 bigint。而 Hive 的 string 是万能类型,如果不知道怎么转,用 string 是比较保险的。
4.2.2 MySQL -> Hive 分区表
Hive 分区表不能随意变更表结构,变更可能会导致旧分区数据读取异常。所以写Hive 分区表时,以 Hive 表结构为准,表结构不一致则直接报错。我们采取了如下的策略
| MySQL字段 | Hive实际字段 | 处理方法 |
|---|---|---|
a,b |
a,b |
正常 |
a,b,c |
a,b |
忽略MySQL的多余字段,以Hive为准 |
b,a |
a,b |
顺序不对,调整 |
a |
a,b |
MySQL少一个,报错 |
a,c |
a,b |
不匹配, 报错 |
未指定字段 |
a,b |
以Hive为准 |
4.3 适配 MySQL 集群
有赞并没有独立运行的 MySQL 实例,都是由 RDS 中间件管理着 MySQL 集群,有读写分离和分表分库两种模式。读写 MySQL 有两种选择,通过 RDS 中间件读写,以及直接读写 MySQL 实例。
| 方案 | 优先 | 缺点 |
|---|---|---|
连实例 |
性能好;不影响线上业务 |
当备库维护或切换地址时,需要修改配置;开发者不知道备库地址 |
连 RDS |
与普通应用一致;屏蔽了后端维护 |
对 RDS 造成额外压力,有影响线上业务的风险;需要完全符合公司 SQL 规范 |
对于写 MySQL,写入的数据量一般不大,DataX 选择连 RDS,这样就不用额外考虑主从复制。 对于读 MySQL,考虑到有大量的全表同步任务,特别是凌晨离线任务高峰流量特别大,避免大流量对 RDS 中间件的冲击,DataX 选择直连到 MySQL 实例去读取数据。为了规避 MySQL 维护带来的地址变更风险,我们又做了几件事情:
- 元数据维护了标准的 RDS 中间件地址
- 主库、从库、RDS 中间件三者地址可以关联和任意转换
- 每次 DataX 任务启动时,获取最新的主库和从库地址
- 定期的 MySQL 连通性校验
- 与 DBA 建立协作关系,变更提前通知
读取 MySQL 时,对于读写分离,每次获取其中一个从库地址并连接;对于分表分库,我们有1024分片,就要转换出1024个从库地址,拼接出 DataX 的配置文件。
4.4 MySQL 运维规范的兼容
4.4.1 避免慢 SQL
前提是有赞的 MySQL 建表规范,规定了建表必须有整型自增id主键。另一条运维规范,SQL 运行超过2s会被强行 kill 掉。
以读取 MySQL 全表为例,我们把一条全表去取的 SQL,拆分为很多条小 SQL,而每条小 SQL 只走主键 id 的聚簇索引,代码如下
select ... from table_name where id>? by id asc limit ?
4.4.2 避免过快读写影响其他业务
执行完一条 SQL 后会强制 sleep 一下,让系统不能太忙。无论是 insert 的 batchSize,还是 select 每次分页大小,我们都是动态生成的,根据上一条运行的时间,运行太快就多 sleep,运行太慢就少 sleep,同时调整下一个批次的数量。
这里还有改进的空间,可以根据系统级的监控指标动态调整速率,比如磁盘使用率、CPU 使用率、binlog 延迟等。实际运行中,删数据很容易引起 binlog 延迟,仅从 delete 语句运行时间无法判断是否删的太快,具体原因尚未去深究。
4.5 更多的插件
除了最常用的 MySQL、Hive,以及逻辑比较简单的文本,我们还对 HBase 的读写根据业务情况做了简单改造。 我们还全新开发了 eswriter,以及有赞 kvds 的 kvwriter,这些都是由相关存储的开发者负责开发和维护插件。
4.6 与大数据体系交互
4.6.1 上报运行统计数据
DataX 自带了运行结果的统计数据,我们希望把这些统计数据上报到元数据系统,作为 ETL 的过程元数据存储下来。
基于我们的开发策略,不要把有赞元数据系统的 api 嵌入 DataX 源码,而是在 DataX 之外获取 stdout,截取出打印的统计信息再上报。
4.6.2 与数据平台的交互
数据平台提供了 DataX 任务的编辑页面,保存后会留下 DataX 运行配置文件以及调度周期在平台上。调度系统会根据调度周期和配置文件,定时启动 DataX 任务,每个 DataX 任务以独立进程的方式运行,进程退出后任务结束。运行中,会把 DataX 的日志实时传输并展示到页面上。
4.7 考虑更多异常
DataX 代码中多数场景暴力的使用catch Exception,缺乏对各异常场景的兼容或重试,一个大任务执行过程中出现网络、IO等异常容易引起任务失败。最常见的异常就是 SQLException,需要对异常做分类处理,比如 SQL 异常考虑重试,批量处理异常改走单条依次处理,网络异常考虑数据库连接重建。
HDFS 对异常容忍度较高,DataX 较少捕获异常。
4.8 测试场景改造
4.8.1 持续集成
为了发现低级问题,例如表迁移了但任务还在、普通表改成了分区表,我们每天晚上20点以后,会把当天运行的所有重要 DataX 任务“重放”一遍。
这不是原样重放,而是在配置文件里加入了一个测试的标识,DataX 启动后,reader 部分只会读取一行数据,而 writer 会把目标地址指向一个测试的空间。这个测试能保证 DataX基本功能没问题,以及整个运行环境没有问题。
4.8.2 全链路压测场景
有赞全链路压测系统通过 Hive 来生成数据,通过 DataX 把生成好的数据导入影子库。影子库是一种建在生产 MySQL 里的 database,对普通应用不可见,加上 SQL 的特殊 hint 才可以访问。
生产环境的全链路压测是个高危操作,一旦配置文件有误可能会破坏真实的生产数据。DataX 的 MySQL 读写参数里,加上了全链路压测的标记时,只能读写特定的 MySQL 和 Hive 库,并配置数据平台做好醒目的提醒。
五、线上运行情况
DataX 是在2017年二季度正式上线,到2017年Q3完成了上述的大部分特性开发,后续仅做了少量修补。到2019年Q1,已经稳定运行了超过20个月时间,目前每天运行超过6000个 DataX 任务,传输了超过100亿行数据,是数据平台里比较稳定的一个组件。
期间出现过一些小问题,有一个印象深刻。原生的 hdfsreader 读取超大 orc 文件有 bug,orc 的读 api 会把大文件分片成多份,默认大于256MB会分片,而 datax 仅读取了第一个分片,修改为读取所有分片解决问题。因为256MB足够大,这个问题很少出现很隐蔽。除此之外没有发现大的 bug,平时遇到的问题,多数是运行环境或用户理解的问题,或是可以克服的小问题。
六、下一步计划
对于 DataX 其实并没有再多的开发计划。在需求列表里积累了十几条改进需求,而这些需求即便1年不去改进,也不会影响线上运行,诸如脏数据可读性改进、支持 HDFS HA。这些不重要不紧急的需求,暂时不会再投入去做。
DataX 主要解决批量同步问题,无法满足多数增量同步和实时同步的需求。对于增量同步我们也有了成熟方案,会有另一篇文章介绍我们自研的增量同步产品。
