作者:小君
部门:数据中台
一、前言
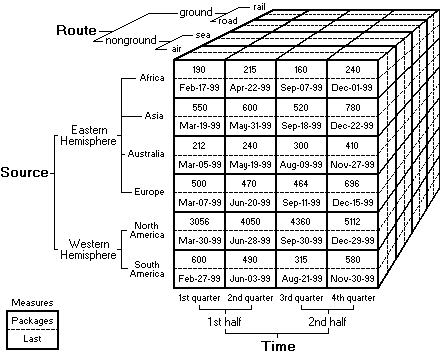
多维分析是数据仓库系统下游常见的基础应用,底层数据是包含多种粒度汇总结果的Cube,用于提供上卷,下钻等操作的数据支持。创建Cube的工具有很多,本文重点介绍在多维汇总场景下,由传统开发模式替换为HiveCube开发模式过程中碰到的问题以及处理经验,主要包括以下方面的内容:
- 背景
- 理论
- 实践
二、背景
在今年上半年,我们接到公司一个项目,项目的大致内容是给有赞商家提供自助取数功能。自助取数功能是给有赞商家提供不同维度下不同主题域指标的预览和下载服务。比如商家可以查看交易域的下单金额,客户域的客户数,流量域的访问数等,商家可以按预置的维度,导出任意聚合粒度的汇总数据,但商家查看指标所选的粒度组合是不确定的,可能是分店粒度,可能是总店粒度,可能是商品粒度,也可能是商品规格粒度,在来源上需要区分下单渠道,在时间上需区分小时粒度、天粒度、周粒度、月粒度,整个维度的排列组合非常多。
为了实现这套多维聚合的自助取数服务,最开始很自然想到采用Kylin,因为Kylin天生就是做多维聚合的事儿。后面这个想法很快被否决,主要因为当时Kylin机器资源紧张,有限的机器资源必须确保线上正在运行应用的稳定。
为了更优雅的基于数仓各主题域的星型模型去产出混合粒度的多维数据立方体,降低代码开发成本和维护成本,我们开始尝试去使用HiveCube,下文主要介绍HiveCube在有赞的使用以及实践。
三、理论
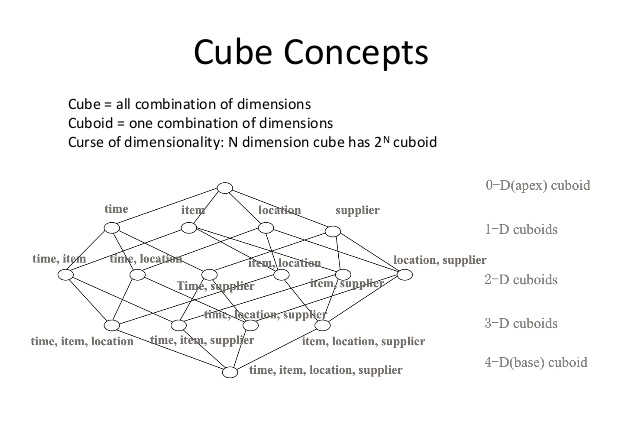
Cube又叫数据立方体,是基于事实和维度而建立起来的多维数据模型,主要为了满足用户从多角度多层次进行数据查询和分析的需要。
HiveCube是Hive提供的一种能快速生成多维聚合数据的方式,有三种实现方法,分别是with cube, with rollup, grouping sets,以上Cube语法也支持在SparkSQL引擎执行。
3.1 with Cube
该语法生成的结果集展示groupBy所列举维度的所有组合方式的聚合。具体使用方式见代码
-- with cube语法 --
select
dim1, dim2, count(*)
from t1
group by dim1, dim2 with cube;
-- 常规语法 --
select dim1, dim2, count(*) from t1 group by dim1, dim2
union all
select dim1, null, count(*) from t1 group by dim1, null
union all
select null, dim2, count(*) from t1 group by null, dim2
union all
select null, null, count(*) from t1;
一个具有N维的数据模型,做完Cube操作,能产生2N种聚合方式。
3.2 with Rollup
与with cube不同的是,该语法对groupBy子句中维度列的顺序敏感,它只返回第一个分组条件指定的列的统计行,改变groupBy列的顺序会改变聚合结果。具体使用方式见代码
-- with rollup语法 --
select
dim1, dim2, count(*)
from t1
group by dim1, dim2 with rollup;
-- 常规语法 --
select dim1, dim2, count(*) from t1 group by dim1, dim2
union all
select dim1, null, count(*) from t1 group by dim1, null
union all
select null, null, count(*) from t1;
一个具有N维的数据模型,做完Rollup操作,能产生N+1种聚合方式。
3.3 Grouping sets
该语法最为灵活,可以自由配置需要聚合的列,通过维护聚合列组合的配置来完成,强烈推荐使用该方法。比如只需要(dim1), (dim1, dim2) 这两种粒度的汇总,直接配置即可,不需要的聚合粒度无需配置,具体使用方式见代码
select
dim1, dim2, count(*)
from t1
group by dim1, dim2 grouping sets ( (dim1), (dim1, dim2) )
所以,不管是从性能的角度,还是从使用的灵活度角度,grouping sets都是最优方案, groupings sets也能等价去替代上面2种语法的实现,具体见代码
GROUP BY a, b, c WITH CUBE
is equivalent to
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( ))
GROUP BY a, b, c, WITH ROLLUP
is equivalent to
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ))
3.4 Grouping__id Function
Cube语法能迅速生产各种粒度的汇总结果,但不同粒度的汇总数据放在一个Cube,如何便捷拿到指定粒度的汇总数据是一个必须解决的问题。对此问题官方提供了原生的实现方法,通过grouping__id函数,在生成Cube的时候给每种聚合粒度打标,后续从Cube拿指定聚合粒度的汇总数据,只需通过grouping__id生成的标过滤即可。
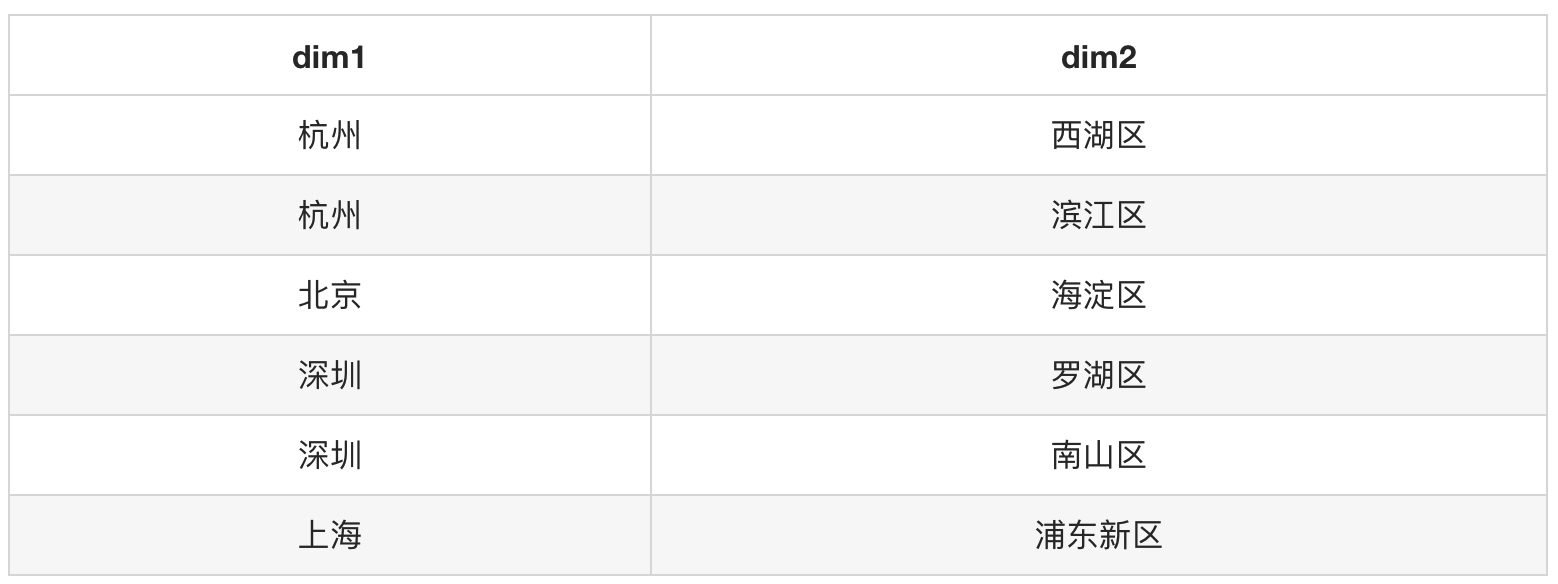
以下模拟了一份二维数据集,基于这份数据集,我们需要做 (dim1, dim2), (dim1), (dim2), ( ) 这四种粒度的汇总,分别计算出对应聚合粒度的记录数。
data:
code:
select
dim1, dim2, count(*), grouping__id
from t1
group by dim1, dim2 grouping sets ( (dim1, dim2), (dim1), (dim2), () );
result:
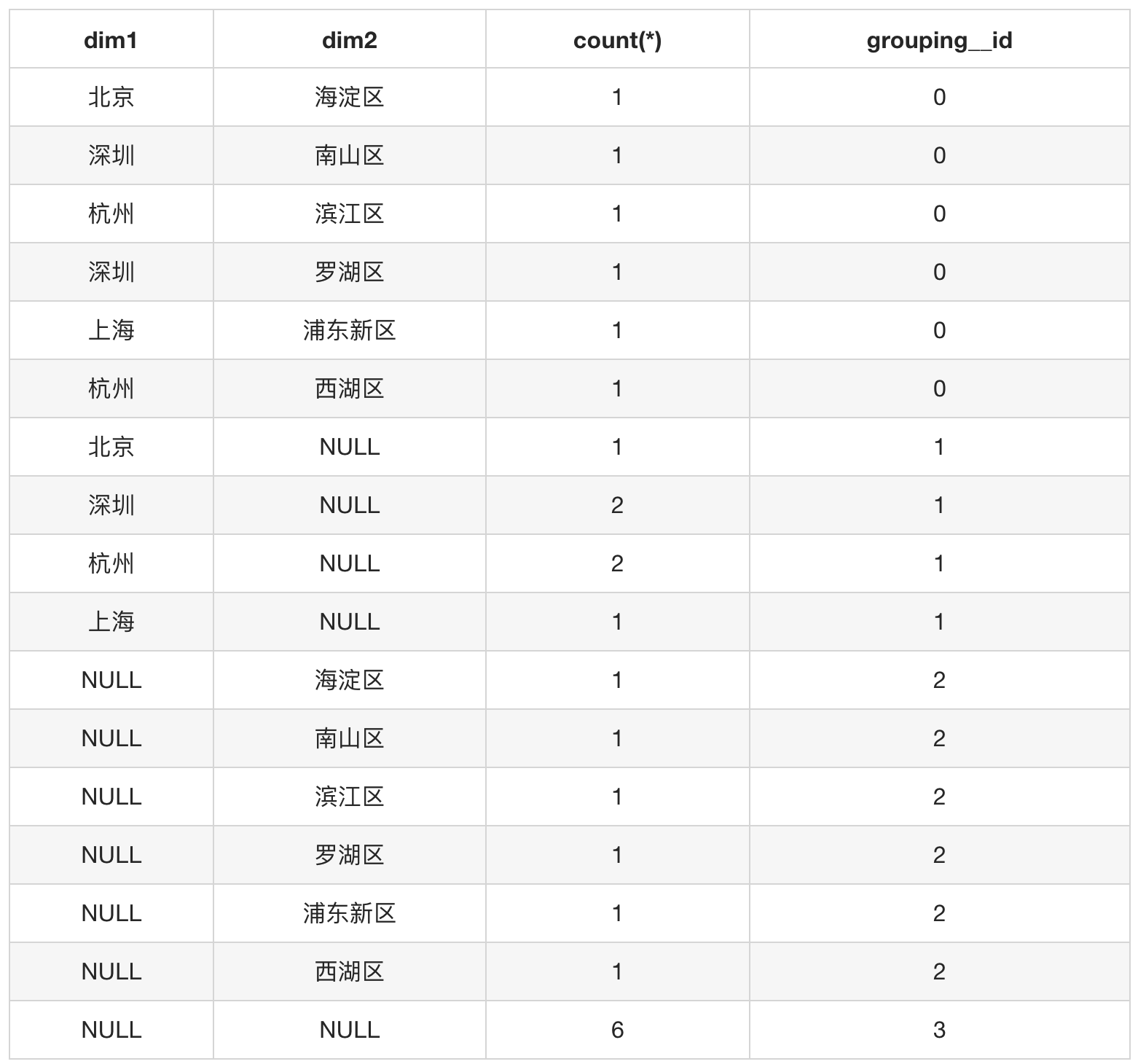
从结果可以看出 (dim1, dim2), (dim1), (dim2), ( ) 四种粒度的汇总分别被标记上 0, 1, 2, 3 四种grouping__id值,如果需要获取(dim1, dim2)这种粒度的汇总数据,可直接从Cube里面限定 WHERE group_id = 0 即可。
3.5 Grouping__id 算法
This function returns a bitvector corresponding to whether each column is present or not. For each column, a value of "1" is produced for a row in the result set if that column has been aggregated in that row, otherwise the value is "0". This can be used to differentiate when there are nulls in the data.
grouping__id的值是根据groupBy的列是否使用和列的顺序来决定。靠近groupBy的列为高位,远离groupBy的列为低位;列被使用则为'0',列没有被使用则为'1'。按照此规则,对每种粒度的组合生成一组二进制数,然后将二进制数转成十进制数。(dim1, dim2), (dim1), (dim2), ( ) 对应的二进制数和十进制数见表格
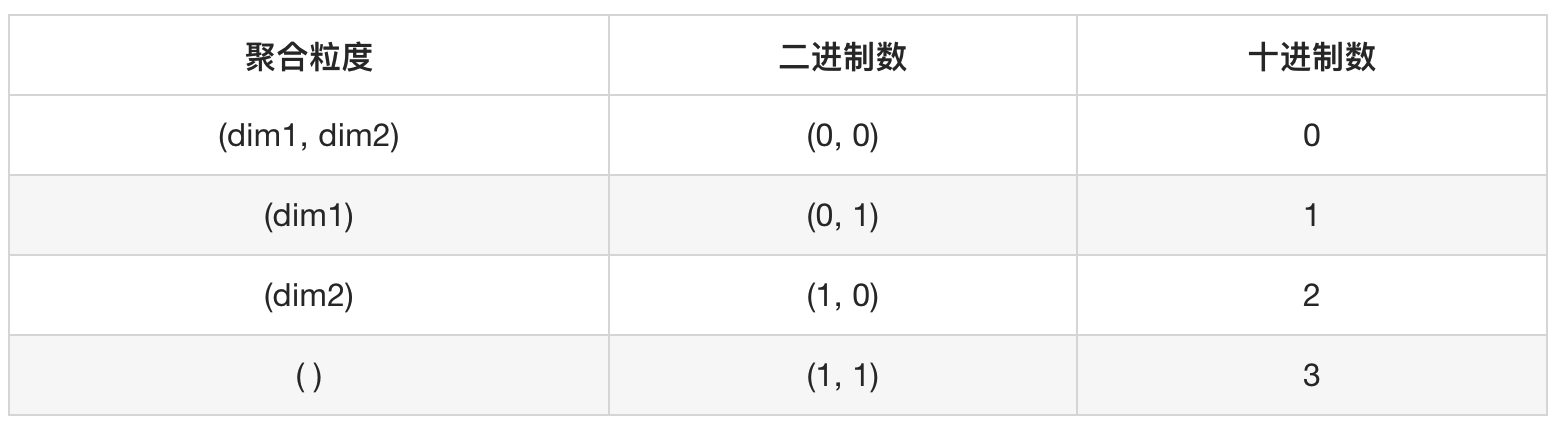
hive1.0以后,grouping__id的生成算法与spark一致。在hive1.0以前,生成算法与spark不一致。在生产环境,任务的运行存在降级处理,例如spark引擎执行失败,会尝试降级到mapreduce引擎执行,如果grouping__id的生成算法不一致,对下游从Cube拿汇总结果的任务会产生严重的影响,故在实际生产环境,直接使用该方法的场景较少。
四、实践
该部分内容重点介绍HiveCube在生产环境使用过程中碰到的问题以及处理经验
4.1 代码实现grouping__id
因为grouping__id的实现算法在Hive与Spark可能存在差异,相同的代码在不同平台执行会产生不同的group_id标。为了避免这种风险,可以借助gruoping__id的实现思想,用代码给不同粒度的聚合组合打标,打标的实现也非常简单,见以下代码。我们可以根据列的值是否为NULL来判断该聚合组合方式是否使用到该列。如果该列的值IS NOT NULL则赋值该列字段名,如果IS NULL则赋值NULL,最终将各列处理的结果用特殊字符拼装成一个字符串,后续通过该字符串来识别具体是哪种粒度的汇总
concat_ws
(
':'
, case when dim1 is not null then 'dim1' else null end
, case when dim2 is not null then 'dim2' else null end
) as group_id
处理效果:
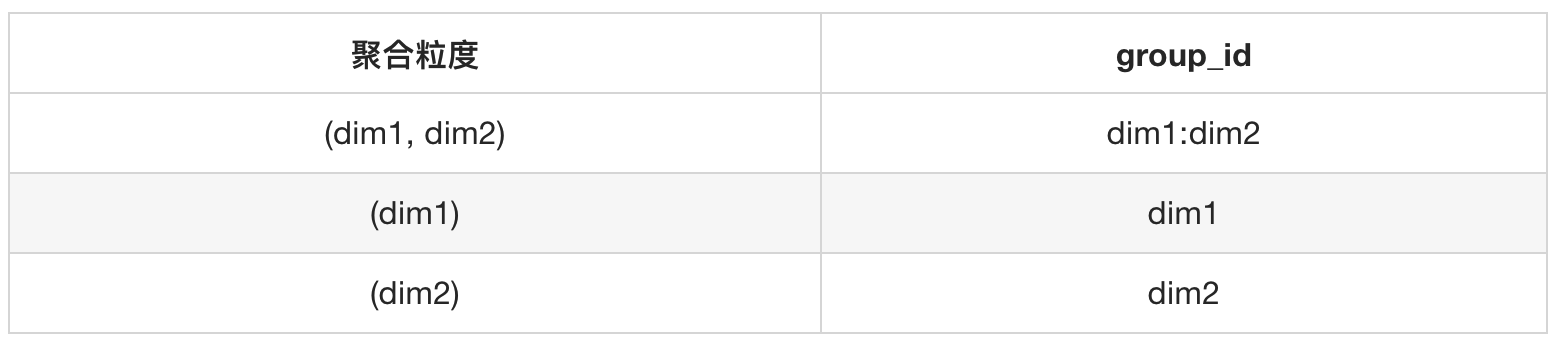
如果需要获取(dim1, dim2)这种粒度的汇总数据,可直接从Cube里面限定 WHERE group_id = 'dim1:dim2' 即可。这种处理方式避免了跨平台grouping__id算法不一致造成的风险,并且生成算法简洁易懂,下游使用也方便快捷。
a、在使用Cube基于各主题域明细中间层做多维运算之前,务必,务必,务必确保每个维度都做了空处理操作,否则会导致通过上面代码实现的group_id无法区分是数据NULL还是非聚合列产生的NULL,从而导致 无法准确拿到指定聚合粒度的汇总数据。
b、增减维度需要注意维护生成group_id的代码!当新增维度,不能随便位置添加,需要在尾部追加,不能影响已生成的group_id;当减维度,注意要下线使用相关汇总数据的表。
4.2 汇总表接入Cube
如果我们把Cube比作制造汇总数据的工厂,那么各粒度汇总的结果表就是工厂生产的具体产品。假设现在有以下粒度的汇总
grouping sets
(
(shop_id, goods_id, placed_order_date)
, (shop_id, goods_id, log_src_channel, placed_order_date)
)
现在需要分别拿到 「店铺+商品+日粒度」和「店铺+商品+来源渠道+日粒度」的汇总数据,按照上面代码实现的group_id,现在获取汇总数据的方式见代码
-- 店铺+商品+日粒度
from
tmp_cube
where
group_id = 'shop_id:goods_id:placed_order_date'
-- 店铺+商品+来源渠道+日粒度
from
tmp_cube
where
group_id = 'shop_id:goods_id:log_src_channel:placed_order_date'
4.3 Cube数据量的压缩
在生产环境Cube一般采用按天跑的形式,使用日分区表的方式进行存储,原则上Cube一次性可以产出小时粒度,天粒度,周粒度,月粒度等不同时间粒度的汇总,对于构建Cube底层使用的明细中间层的时间限制需要优先满足长时间跨度的指标。例如在计算月粒度指标的时候,在日粒度汇总层面会产出近30天的日粒度汇总,但现实情况下游一般只会使用最新一天的日粒度汇总数据,即昨日的汇总数据,但按以上方式的处理就会每天产生29个不会被使用到的日粒度汇总,在聚合维度比较多的时候,数据量膨胀会非常厉害,对于这种情况,可以适当对时间维度做去明细化处理,时间可以处理成是否当日,是否当周,是否当月,是否近30天等标志。这样再计算日粒度汇总的时候,如果是昨日我们把它放在1这个维度值里面;如果不是昨日,也就是其他29天,我们把它放在0这个维度值里面,这样29条记录就被压缩为1条记录,对于一个具体的聚合组合方式数据量能压缩到只有2条,我们只取关注的有效汇总数据即可。具体处理方式见代码
select
, shop_id as shop_id
, goods_id as goods_id
, buyer_id as buyer_id
, log_src_channel as log_src_channel
, substr(placed_order_time, 1, 10) as placed_order_date
, substr(placed_order_time, 12, 2) as placed_order_hour
, case when datediff( '${DP_1_DAYS_AGO_Y_m_d}', substr(placed_order_time,1,10) ) <= 0
and datediff( '${DP_0_DAYS_AGO_Y_m_d}', substr(placed_order_time,1,10) ) > 0
then 1
else 0
end as is_placed_1day -- 是否当日
, case when datediff( '${DP_30_DAYS_AGO_Y_m_d}', substr(placed_order_time,1,10) ) <= 0
and datediff( '${DP_0_DAYS_AGO_Y_m_d}', substr(placed_order_time,1,10) ) > 0
then 1
else 0
end as is_placed_30day -- 是否近30天
, case when datediff( '${DP_1_WEEKS_AGO_MONDAY_Y_m_d}', substr(placed_order_time,1,10) ) <= 0
and datediff( '${DP_0_WEEKS_AGO_MONDAY_Y_m_d}', substr(placed_order_time,1,10) ) > 0
then 1
else 0
end as is_placed_weekly -- 是否当周
, case when datediff( '${DP_FIRST_DAY_PRE_MONTH_Y_m_d}', substr(placed_order_time,1,10) ) <= 0
and datediff( '${DP_FIRST_DAY_THIS_MONTH_Y_m_d}',substr(placed_order_time,1,10) ) > 0
then 1
else 0
end as is_placed_monthly -- 是否当月
, sum( sku_real_pay ) as amt
, count( distinct buyer_id ) as uv
from
tmp_table
where
to_date(placed_order_time) >= '${DP_FIRST_DAY_PRE_MONTH_Y_m_d}'
and
to_date(placed_order_time) < '${DP_0_DAYS_AGO_Y_m_d}'
group by
......
grouping sets (
(shop_id, goods_id, is_placed_1day, placed_order_hour)
, (shop_id, goods_id, is_placed_1day)
, (shop_id, goods_id, is_placed_weekly)
, (shop_id, goods_id, is_placed_monthly)
)
对于使用这种方式处理的Cube,下游汇总表在接入的时候需要额外多加一个时间标志判断条件,比如要拿「店铺+商品+日粒度」的汇总数据 和 「店铺+商品+周粒度」的汇总数据,按照上面代码实现的group_id,现在获取汇总数据的方式见代码
-- 店铺+商品+日粒度
from
tmp_cube
where
group_id = 'shop_id:goods_id:is_placed_1day'
and
is_placed_1day = 1
-- 店铺+商品+周粒度
from
tmp_cube
where
group_id = 'shop_id:goods_id:is_placed_weekly'
and
is_placed_weekly = 1
4.4 Cube场景下的刷数
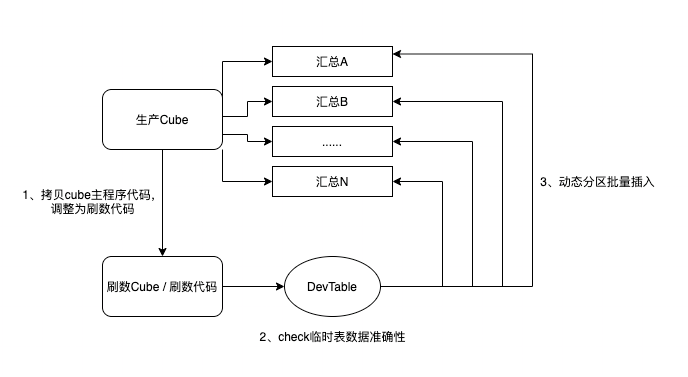
在生产环境,重刷数据是不可避免的常规操作,现实情况有很多场景需要刷近1年,近2年,近3年,甚至近4年的数据。对于Cube这种重型工具,一般是按日调度,调度一次能产出多种时间粒度的汇总结果,如果在刷数场景下,批量实例化很多批次去执行,是不合理的操作,也是不可能完成的任务。那Cube场景下的刷数怎么来完成?回答这个问题前,首先要明确Cube是一个快速生产汇总数据的工具,而不是一个方便刷数的工具。基于这个原则,我们可以拷贝线上Cube主程序代码,稍加改造,制作出刷数代码,将历史数据一次性跑出到临时表,在临时表验证数据的准确性后,动态分区批量插入到下游各粒度聚合的汇总表。Cube不需要保留很久的历史数据,它只是生产汇总数据的机器。
4.5 HiveCube相关参数
grouping sets默认处理的聚合组合个数是30个。可以通过调整hive.new.job.grouping.set.cardinality参数的值来调整处理的上限。假如需要调整到100个,可以使用以下配置
set hive.new.job.grouping.set.cardinality = 100;
4.6 HiveCube执行性能
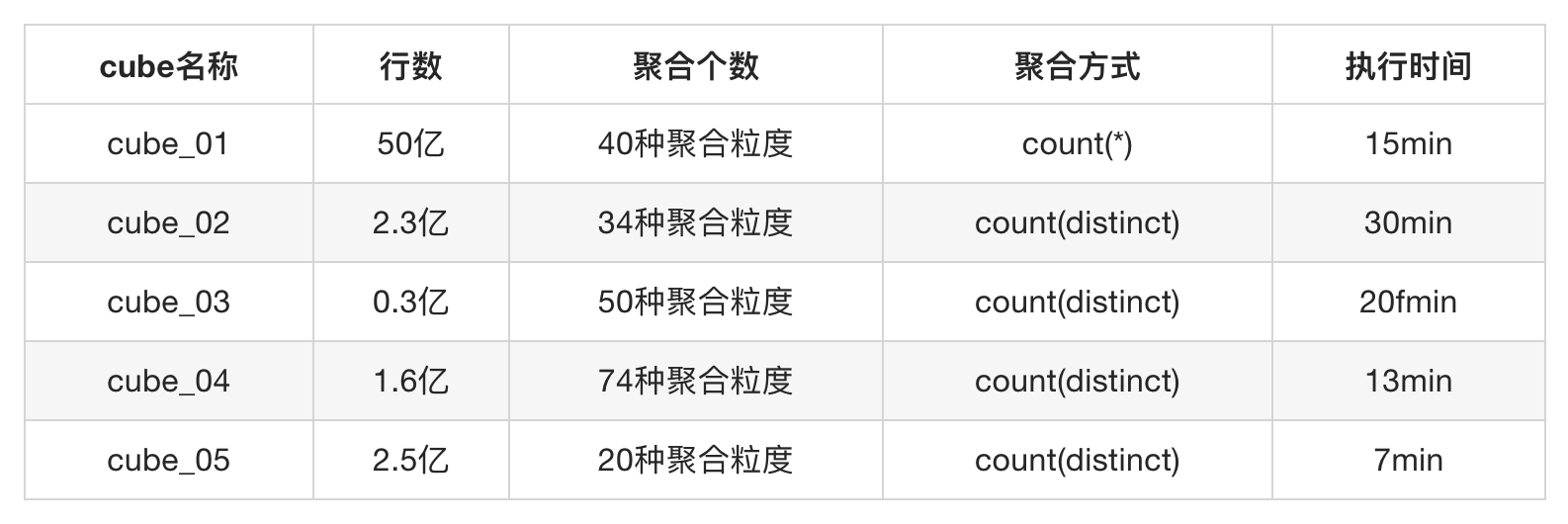
以下是HiveCube在几组实验数据和算子下的测试性能表现
4.7 HiveCube VS 传统方法
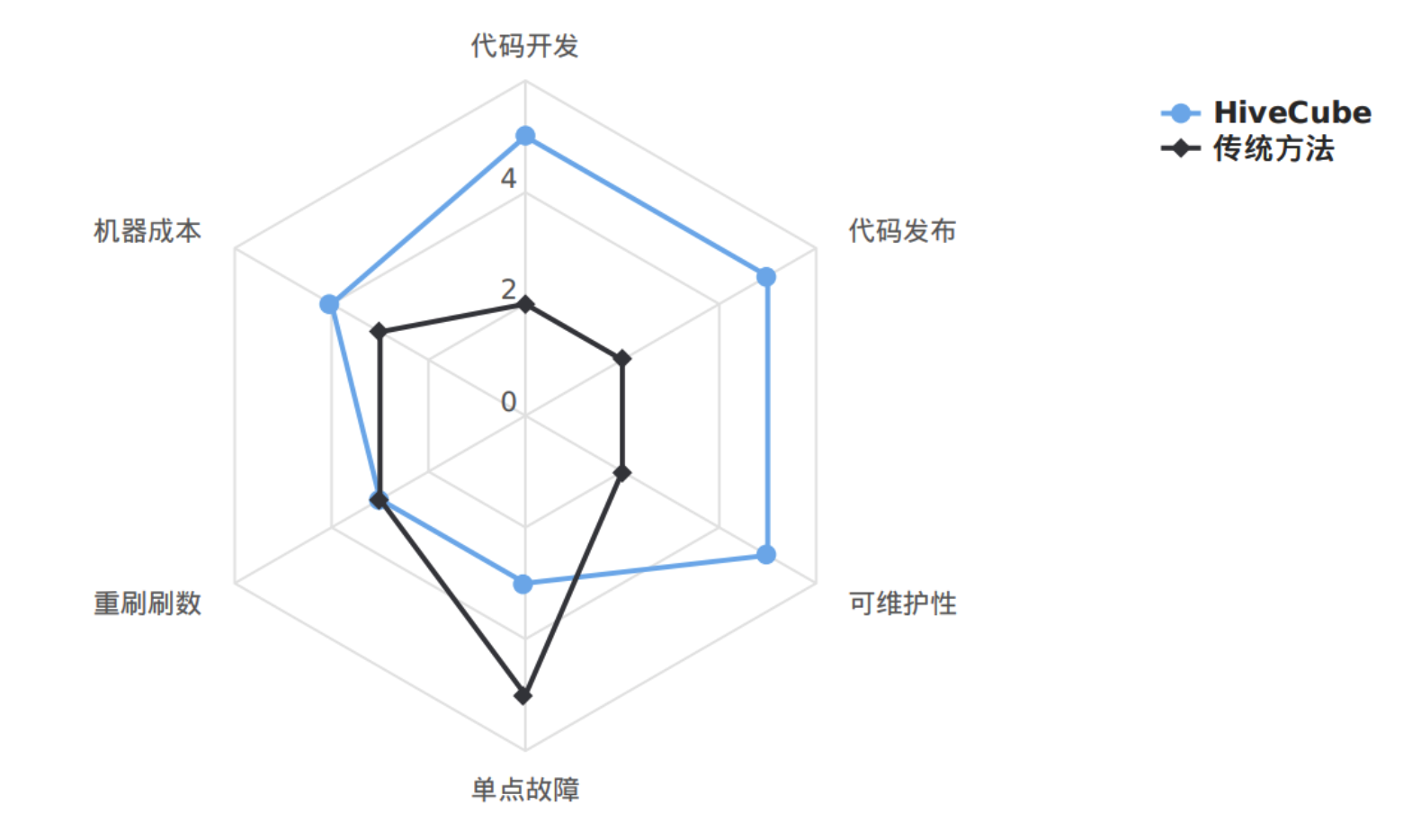
没有最完美方案,只有最合适的方案。下面从6个维度去比较HiveCube与传统方法的优势与劣势。
代码开发:代码开发的效率
代码发布:代码发布的便捷性
可维护性:迭代逻辑的成本
单点故障:失败任务的影响面
重刷刷数:补历史的成本
机器成本:性能开销
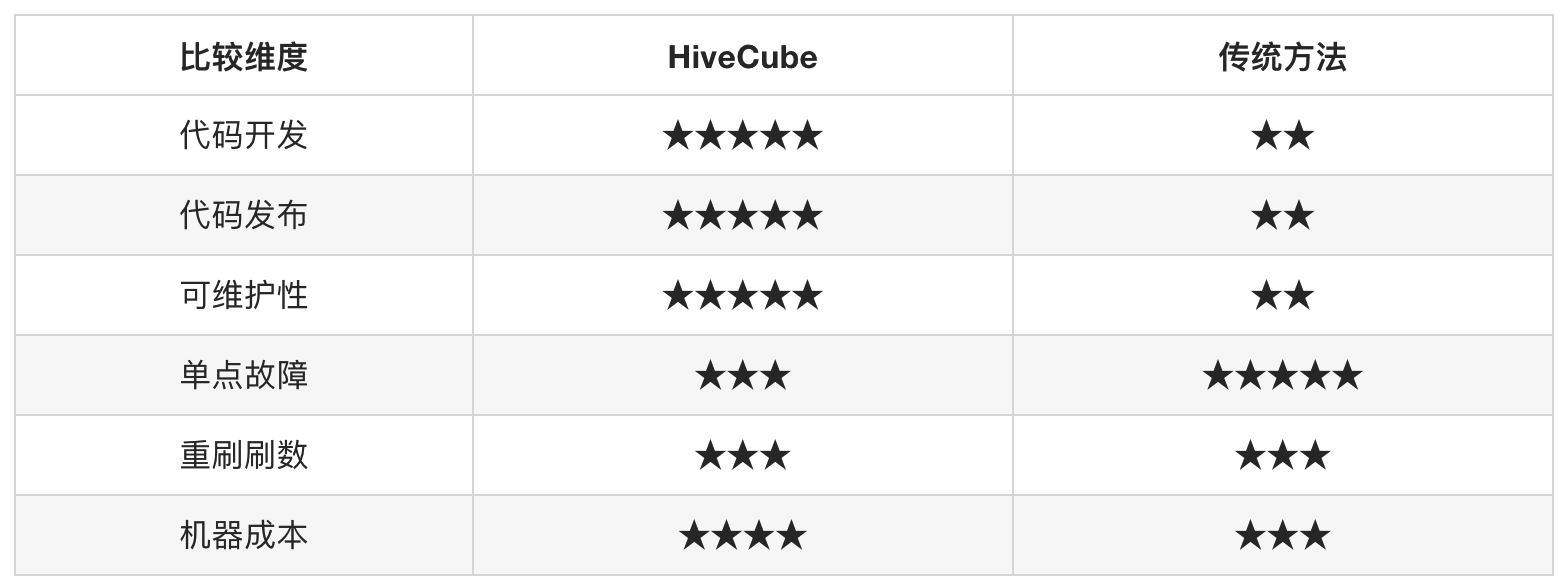 代码开发:传统方法对于一个具体的汇总粒度需要建设一个独立的任务来维护;HiveCube可以更加浓缩,相同逻辑不同粒度的汇总任务,只需开发一个任务即可,代码开发效率提高不只一个level。
代码开发:传统方法对于一个具体的汇总粒度需要建设一个独立的任务来维护;HiveCube可以更加浓缩,相同逻辑不同粒度的汇总任务,只需开发一个任务即可,代码开发效率提高不只一个level。
代码发布:每个任务的上线都要经历explain、保存、测试、发布,如果一次性有100个任务上线,是不是会疯掉,HiveCube减少了任务的数量,间接降低了任务发布的工作量。
可维护性:当某个原子指标口径需要调整,传统模式开发下不同汇总粒度的独立任务都需要去遍历的调整代码,HiveCube只需要修改一处。
单点故障:在这一点上,HiveCube有先天的劣势,容易掉死在一棵树上。传统方法大多都是独立开发,影响的可能是某个点,而不像HiveCube是一个面。虽然HiveCube有这个劣势,但并不表示就不能去使用。我们可以通过配置压测预警任务,在晚上集群空闲的时间段运行一个Cube压测任务以此来检测集群的稳定性,以防集群参数做了调整,导致Cube任务不能正常产出的尴尬局面。
重刷数据:HiveCube需要维护刷数脚本,首次操作会麻烦些,到后期会比较轻松,可以一次性动态分区插入,时间比较短。传统方法需要借助调度平台的重刷数据能力,按批次执行,有时还要注意跑批顺序,人工介入成本还是很大。总体看两种方法投入成本相当。
机器成本:从目前采集的成本数据来看,成本基本相当,但也有特殊情况。 对于数据量巨大,但无去重操作的任务,计算成本会节省非常明显。
综上,HiveCube是一种比较优秀的方案,因为它给我们带来的开发提效确实非常惊人。
4.8 HiveCube的拆分
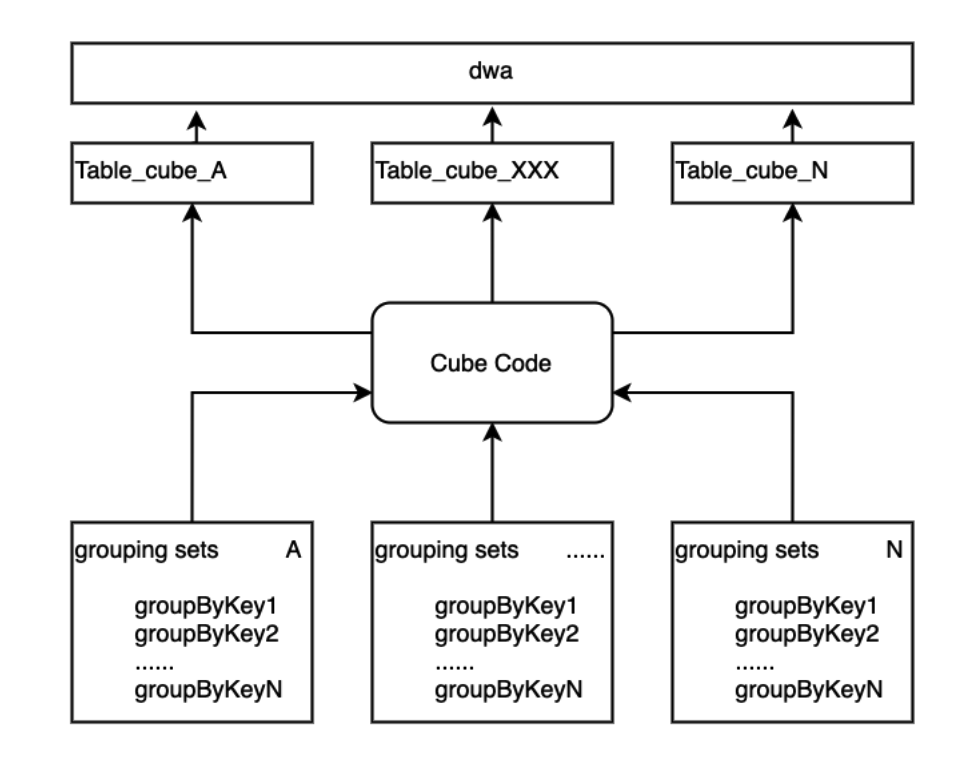
假设随着业务和需求的发展,grouping sets包含的聚合维度一直在增长,到了100,200,300个,Cube还能扛得住压力吗?很明显,肯定扛不住,即使扛住了产出时间也会拖很久。如果真的遇到这种场景,也不是无计可施,可以适当对Cube进行拆分,将grouping sets的配置进行分组,从而拆分出多个Cube任务,降低单个Cube压力过大的场景。
五、展望
我们下一步计划将数仓公共汇总层统一采用HiveCube来进行建设与收口,将各主题域的汇总逻辑进行归一化处理,数仓开发同学不用过多去关注重复性较高的汇总层代码,而将重点投放在Cube所依赖的底层星型模型的设计上。
最后打个小广告,有赞数据中台团队长期招人,期待你的加入~,
数据业务架构师、数据平台架构师、大数据开发工程师
如果你也是聪明、皮实、有要性的小伙伴
如果你对电商、SaaS有更多想法
欢迎投递简历:liuyijun@youzan.com
加入我们,一起enjoy
