前言
一直以来,作为互联网软件工程师接触最多的事务之一便是持续集成(Continuous integration,简称 CI)。持续集成俨然已成为主流互联网软件开发流程中一个重要的环节。现今有赞内部在实践持续交付(Continuous delivery,简称 CD),它可以被看成是后持续集成时代的产物。需要强调的是,不管是 CI 还是 CD,更多的是强调作为软件开发交付过程中的实践,而一旦交付到生产环境CI和CD就无能为力了。有赞线上拨测系统正是为了弥补这一不足。现有的线上保障手段可分为运维层面、产品层面、安全层面、服务层面和测试层面等维度。本文重点介绍我们在测试层面的实践。
基于测试脚本的线上监控产生
我们做测试线上拨测系统的初衷有以下几点:
1. 主动预警线上问题。有赞有很多个业务线,各个业务线有不同的开发测试同学对接,我们很难做到每次发布都把影响面评估得十分准确。运维层面的监控更多的是被动告警,即用户流量触发了线上 bug,我们才会收到报警,用户体验不够好。我们需要在线上 bug 预警方面变被动为主动,周期性地知晓各个业务线的健康状况。
2. 小流量下敏捷发现线上问题。通常我们软件的发布都是在凌晨流量非常低的时候进行。发布完成后,回归时间长(靠手动),测试面有限(无法做到次次发布全量回归)。此时需要敏捷构造一波覆盖面全的流量,在小流量背景下,敏捷发现线上问题。
3. 知晓紧急情况下业务的受影响范围以及后续收敛情况。例如当生产环境出现网络异常等非软件故障时,需要清楚业务层面的影响;当网络恢复后,需要知道业务影响是否都已经收敛。
在此之前这些场景都需要测试人员手工介入,灵活度敏捷度都非常差。有了这套系统后,测试人员可以增加自己关注的场景,场景可以通过主动触发和定时触发来执行,通过告警系统通知到有关人员,做到第一时间排查问题,减少故障影响,降低故障时长。
基础版
1.0 版本我们使用通用的 SpringWeb 搭建,有赞内部称为线上机器人检查。系统结构如下
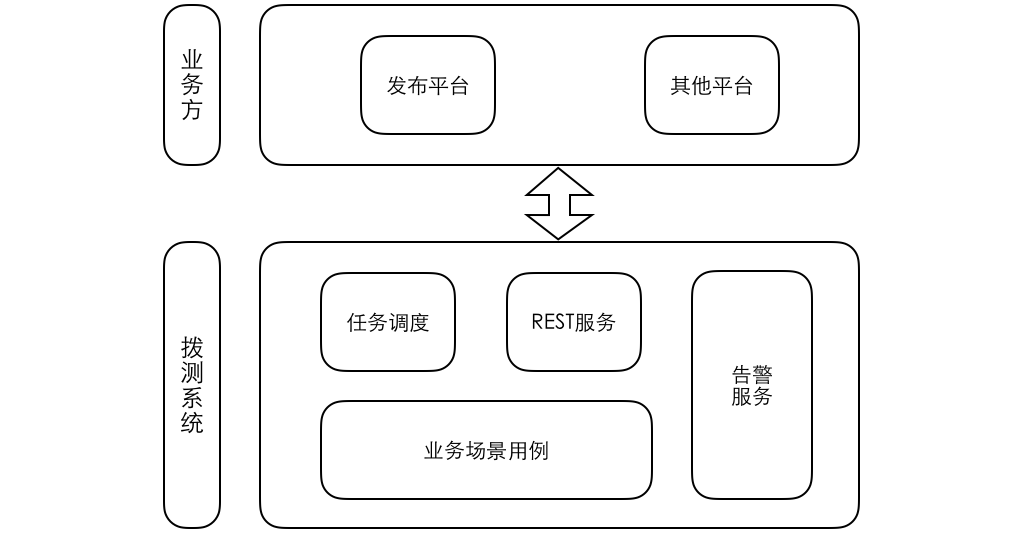
系统主要为三个模块:
1. 任务调度模块。该模块将用例执行封装成系统任务,使用 Spring Quartz 来定时触发。对外提供 API 对接有赞发布平台,每当系统发布上线完成后主动触发用例执行。
2. 测试用例模块。包括业务访问,断言和告警。测试场景需要各个业务线的测试同学投入开发。
3. 告警模块。对接有赞内部告警平台。
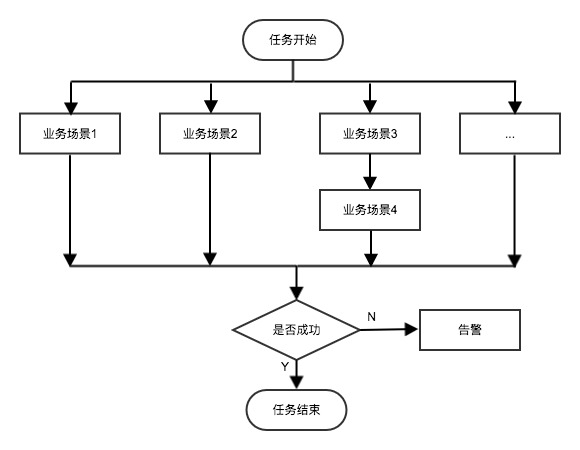
系统将用例分为基础用例和场景用例,支持场景并发或者顺序同步执行。具体执行策略由用例设计者结合具体情况在用例开发过程中设定。
存在的问题
基础版满足了最小可用,这种方式优点在于前期能够快速投入使用,且对于经常写集成用例的人来说成本不高,但对其他人(测试新人、开发、运维等)则不然。概括而言,其缺点主要集中在以下几点:
- 业务线一旦多起来,用例代码开发成本提高;
- 随着用例数量增加,后期用例维护成本很大;
- 用例上线不灵活,每次用例改动需要重新发布;
- 无法直观看到运行情况和业务覆盖情况;
- 每次执行不区分业务,全量执行;
- 用例代码存在冗余,效率比较低。
配置化和可视化
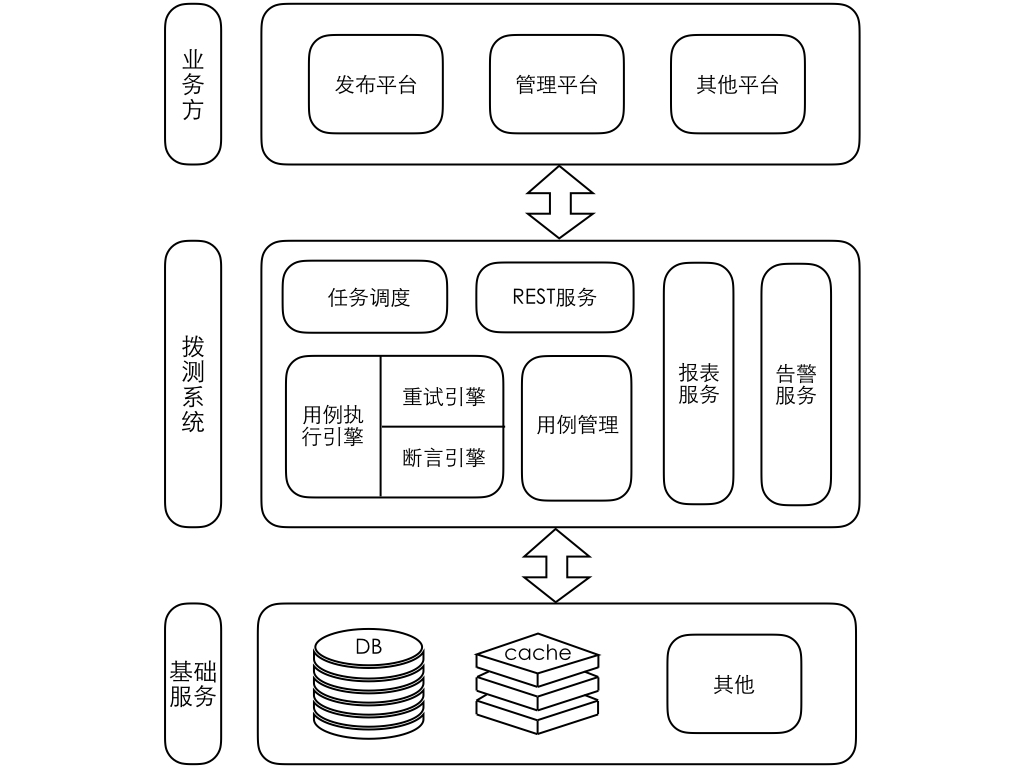
由于这些不可规避的问题,我们重新设计并发布了 2.0 版本。对应解决以上问题:
- 测试用例和测试场景支持配置化,可以从管理平台上配置;
- 用例配置标准化,给定标准用例结构和断言策略;
- 通过管理平台来管理自己的用例,用例改动实时生效,无需发布;
- 增加前端展示,通过图表直观展示运行情况和业务覆盖情况,方便不同人群查阅;
- 对接发布平台,按照指定的应用名来区分跑哪些用例;
- 设计用例执行框架,实现核心代码复用。
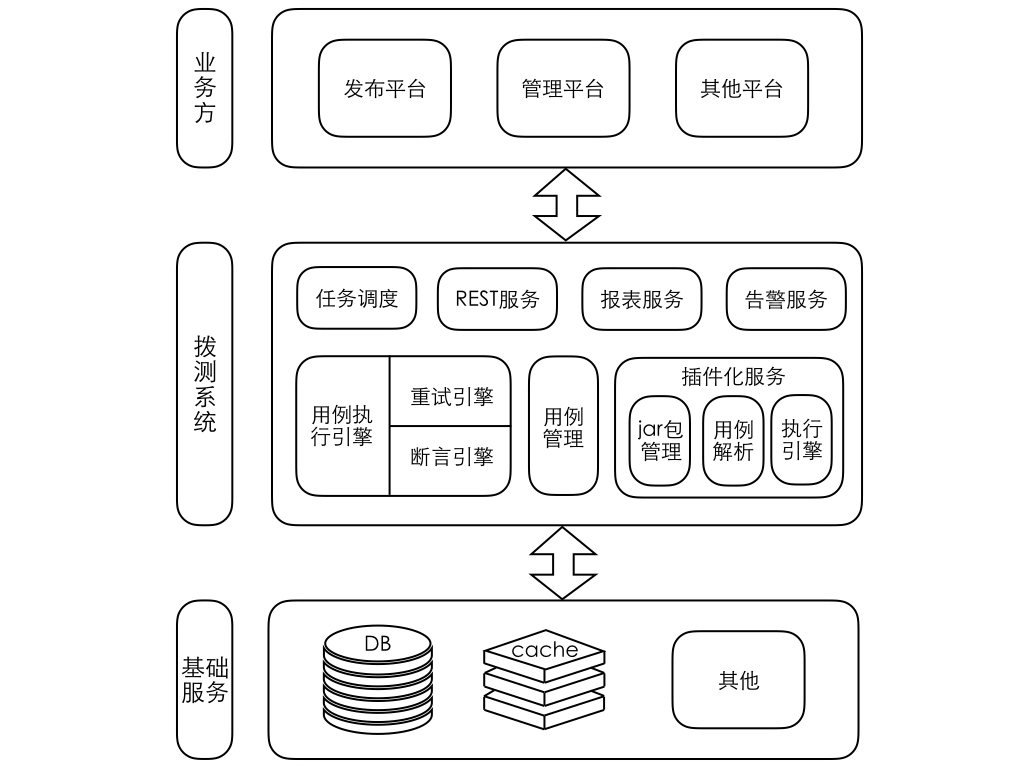
新版系统架构图如下
用例模型如下:
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 用例名称 | 是 | 建议命名格式:“用例类型:服务:方法” |
| 用例类型 | 是 | 两种类型可选http或dubbo |
| 用例描述 | 是 | 场景描述 |
| 所属业务 | 是 | 用例所属业务阈 |
| 请求url | 否 | http协议调用的url |
| 请求头 | 否 | http header |
| 请求参数 | 否 | http或dubbo的请求入参。支持动态参数注入实现用例间依赖 |
| 服务名称 | 否 | 对应请求dubbo协议的接口名(包名+类名) |
| 请求方法 | 是 | http协议:GET、POST、PUT等;dubbo协议:方法名 |
| 断言 | 是 | 支持多个 |
| 是否开启 | 否 | 控制开关,关闭后不再运行。默认开启 |
| 是否登录 | 否 | 开启后,使用默认账号进行登录操作。默认不开启 |
| 是否重试 | 否 | 开启后,⽤例失败重试1次。默认否 |
| 前/后置检查 | 否 | 执行⽤例前/后,先执行前/后置检查,失败则中断 |
*此处略去了部分有赞内部使用的字段
为了更直观展示线上业务的健康状况我们增加了丰富前端报表
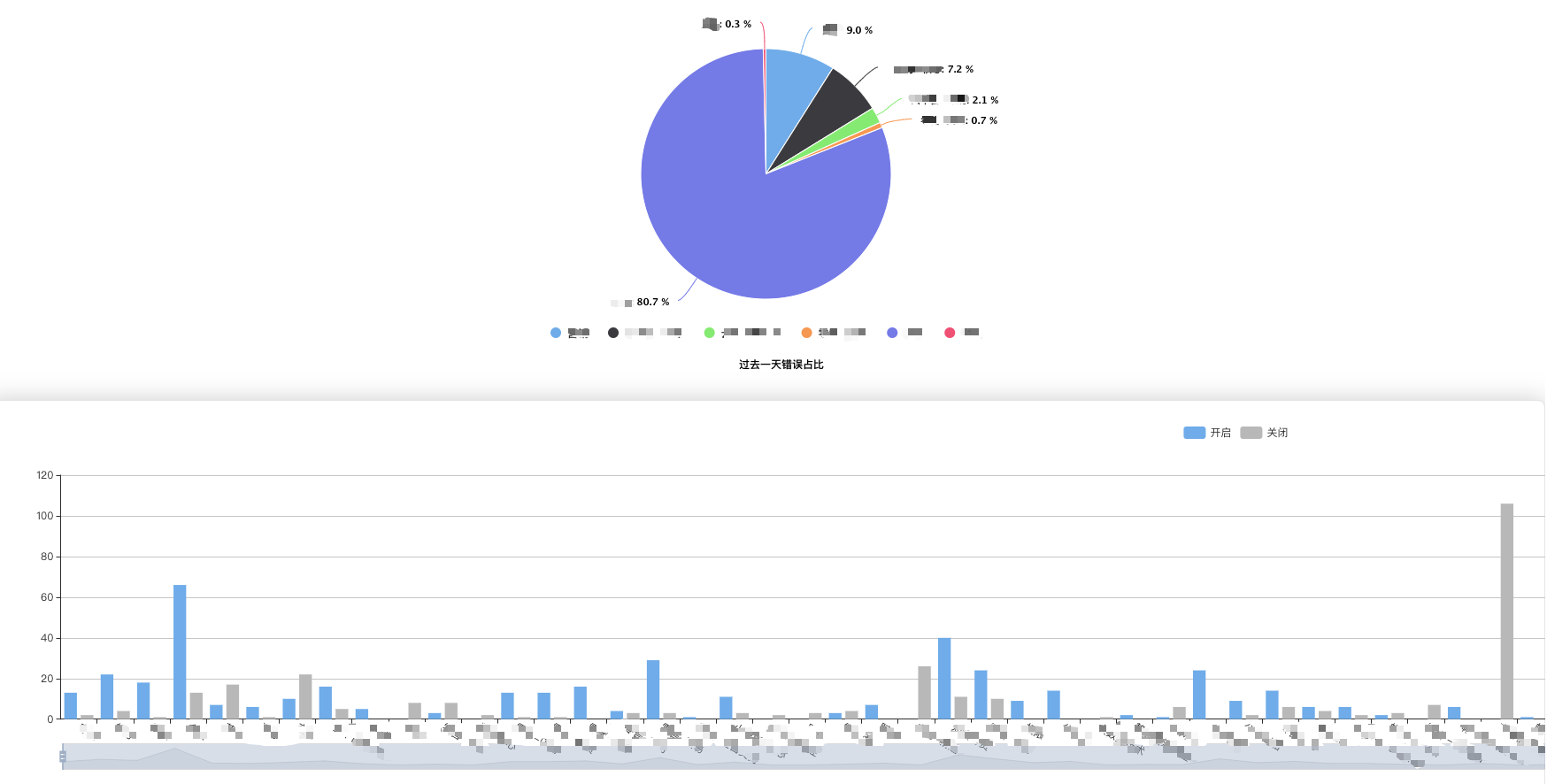
新版本与老版本的主要区别在于:
- 将执行流和数据流进行了分离,测试用例设计无需编码,支持配置化,用例作为数据存放到 DB 中重复使用,用例的执行引擎管理用例的执行流。
- 对通用的事务进行了封装,比如登录、切换店铺等操作,通过统一的线程池进行管理。
- 支持动态参数注入,实现了用例间的相互依赖,后面再单独介绍这块内容。
任务执行流程图如下:
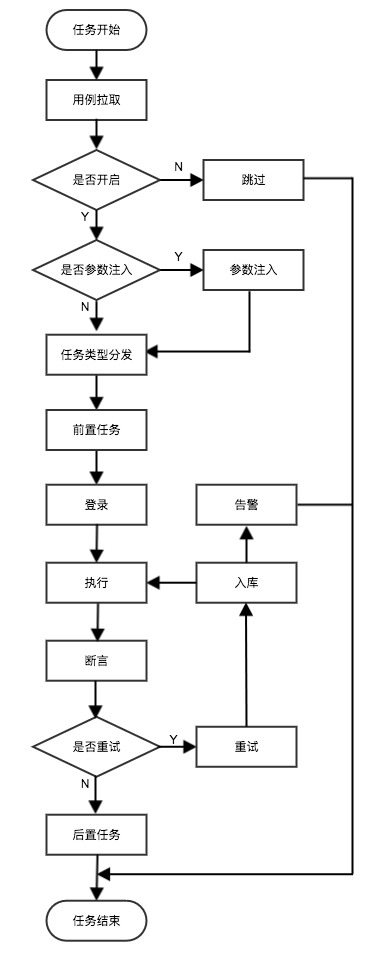
任务执行引擎通过不同的工作线程实现。不同业务用例并发执行,业务内部用例串行执行。系统根据不同的用例的类型(http/dubbo)分发到具体任务流中。

用例间依赖的实现
从用例的复杂度上讲,我们的用例主要分为两大类:单一场景的基础用例和复杂场景的组合用例。组合用例是在基础用例的基础上进行一定的集成,用例的输入输出存在一定的依赖。我们实现用例依赖的方式有两种:
- 通过配置用例的前置后置关系。
- 通过参数注入。
第一种方式,在配置用例的时候,给它一个前置用例,当然前置用例也是在平台中管理的。这样当执行到该用例的时候,执行引擎会先去执行前置用例。
第二种方式,针对 Json 格式的入参,我们定义如下格式进行参数注入:
$#a,b,c#$各个字段分别代表的含义为:
a:被依赖用例的ID
b:被依赖用例响应的字段(key值),比如:name
c:可选字段,当被依赖值位于 array 里面时,取其 index 下标
举例:{"code":"$#8,data,0#$","type":"$#10,type#$"}
参数注入的流程如下:
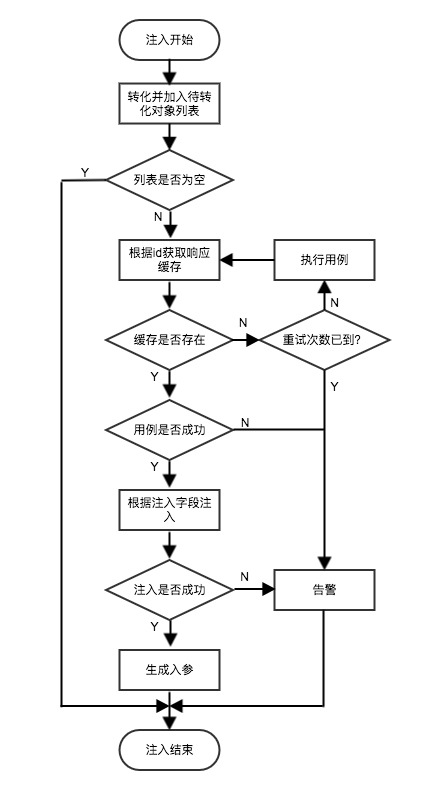
断言模块设计
在新版系统里面,我们设计了四种类型的通用断言,几乎可以满足我们自己的所有应用场景。这四种类型分别是:
1. 是否包含。
响应内容包含指定内容为 true,反之为 false。
非空/null。
响应内容非空/null为 true,为空/null为 false。JSON 特定位置的值的“相等”判断。
这种情况系统首先会将响应内容转换成 json,添加断言时需要指定待比较对象在 json 串中的坐标。如果该坐标上的值与指定的值相等则为 true,反之为 false。 那么如何给一个 json 串的每个值设置一个独一无二的坐标呢?考虑到 json 存在嵌套关系且 key 可能重复,我们通过一种复合 key 的来表示这个坐标,例如有如下 json:{
"data": {
"list": [
"1",
"2"
],
"info": {
"name": "张三",
"age": 18
}
},
"code": 200
}
对标红的值的断言可以这样表示:{"data":{"info":{"name":"张三"}}},如果返回的位置的值为"张三"则判断结果为 true,否则为 false。
- 面向 JSON 的伪代码表达式判断
前面三种类型的断言仅满足了部分场景,对于一些复杂的断言仍然无法满足,比如上文 json 中 list size 的断言。为此,我们引入第四种断言方式---伪代码断言。针对 list size 的断言我们可以这样写:
getJSONObject("data")getJSONObject("list").size() > 0代码在处理的时候会将该表达式拼接在 json 对象后进行执行。整段代码执行的结果为真断言为 true,否则为 false。 伪代码的动态编译、加载和调用,采用 GroovyShell 来实现。该部分代码实现如下:
public Result compare(String response) {
Result result = new Result();
// 单例获取GroovyShell
GroovyShell shell = SingleGroovyUtil.getGroovyShell();
Binding binding = null;
JSONObject jsonObject = new JSONObject();
JSONArray jsonArray = new JSONArray();
Object value = null;
try {
if (response.startsWith("[")){
jsonArray = JSON.parseArray(response);
binding = new Binding();
binding.setVariable("data", jsonArray);
value = InvokerHelper.createScript(shell.getClass(), binding).evaluate("data." + textStatement);
}else {
jsonObject = JSON.parseObject(response);
binding = new Binding();
binding.setVariable("data", jsonObject);
value = InvokerHelper.createScript(shell.getClass(), binding).evaluate("data." + textStatement);
}
if((Boolean)value) {
result.setSuccess(true);
}else {
result.setSuccess(false);
String msg = JsonUtil.findErrMsgByJsonObject(jsonObject);
result.setMsg(String.format("断言失败。断言的内容[%s], 错误描述[%s]", this.textStatement, msg.length()>0?msg:response));
}
} catch (Exception e) {
result.setSuccess(false);
String msg = JsonUtil.findErrMsgByJsonObject(jsonObject);
result.setMsg(String.format("断言时发生异常。ErrMsg=[%s],actual=[%s]", e.getMessage(), msg.length()>0?msg:response));
} finally { // 处理完后,主动将对象置为null
binding = null;
}
return result;
}
插件化
新版系统满足了用例的可配置化以及可视化的要求,同时也牺牲了一部分的灵活性。例如一些复杂断言的伪代码会非常长,且可读性不高,一不留神就会出错;简单的用例依赖可以满足,复杂的用例依赖却很难满足。比如用例 A 在某些条件下依赖用例 B,其他条件下依赖用例 C,这种复杂依赖关系走配置化并不合适。基于以上考虑,我们在现有的系统的基础上又增加了插件化的特性,来支持复杂用例的接入。
插件化的设计思想如下:
- 平台对外提供一套用例标准,测试同学开发符合标准的用例添加到平台即可运行。
- 用例与平台完全解耦,用例在平台可配置。
- 用例支持热插拔,平台无需重启。
用例标准通过接口的形式对外提供,封装成jar包暴露出来。用例设计者直接依赖该jar包并实现指定接口即可。用例接口定义如下:
public interface AbstractTestCase {
CaseResult before();
CaseResult run();
void after();
}
用例开发完成后打包成 jar 包上传到平台,一个 jar 包中可包含一个用例也可以包含多个用例。
jar 包上传后平台要做的事情如下:
- 动态把 jar load 进 JVM
- 解析实现了 AbstractTestCase 接口的类
- 按照指定策略调用类中的方法
- 上报并展示结果数据
获取 jar 包中实现了 AbstractTestCase 接口的代码如下:
/**
* 获取jar包中某接口的实现类
*/
public static List<Class<?>> getAllImplClassesByInterface(Class c) {
List<Class<?>> filteredList = new ArrayList<Class<?>>();
//判断是否是接口
if (c.isInterface()) {
try {
//获取jar包中的所有类
List<Class> allClass = getClassesByPackageName();
allClass.forEach(clazz -> {
if (c.isAssignableFrom(clazz)) {
if (!c.equals(clazz)) {
filteredList.add(clazz);
}
}
});
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
return filteredList;
}
未来
未来有赞线上拨测系统会提供更丰富的功能,例如更灵活的用例执行策略,核心用例执行频率更高,边缘业务执行频率降低;更全面的报警策略,各个业务方可以自由定制关心的用例,线上问题第一时间触达;支持多机房,目前该系统只在单机房进行部署,有赞核心业务已完成多机房部署,拨测系统也会随之调整;系统支持分布式,为了防范系统单点故障,未来还会考虑进行分布式部署。
目前这套系统可以保障测试同学第一时间知晓有赞线上核心业务异常,将来保障的业务广度和深度会进一步提高,成为有赞线上质量保障至关重要的一环。
