
背景 & 痛点 & 价值
稳定性始终会是一家成功公司的重要指标,在移动端亦是如此。跟大部分创业公司一样,有赞在创业初期选择以核心业务为主, 在一些基础设施的搭建上主要以使用三方平台为主(腾讯bugly)。随着业务的发展和bugly的长期不维护,慢慢出现一些三方平台的弊端。例如: * 某次版本上线之后,没有及时发现其隐藏的Crash, 导致故障产生 * Crash发生之后,无法根据特定规则分给某位处理人。 * 某个版本上线灰度时,该版本在特定角色下存在Crash。这个时候没法中断灰度版本的下发
crash平台建设的线路规划
为了解决这些问题,我们就开始着手搭建自有的Crash反馈平台。平台建设的规划大致的路线是:
- 基础架构搭建。Crash的收集、上报、分类、查看、处理
- 增加三方平台没有的功能。实时监控、告警、日报
- 补齐三方平台的功能,Crash趋势统计、Crash符号化
crash平台的功能集
总结下来,Crash平台大概需要有以下功能:
- Crash收集:某次Crash从发生,保存本地到上报的过程
- Crash查看:查看Crash的发生堆栈,版本分布,发生页面,操作页面路径,帮助处理人快速定位问题。
- Crash处理人以及状态:将某个Crash分配给指定人,发送通知。处理人修复完成之后,修改Crash的状态。
- Crash分类:根据上报的Crash将Crash进行分组,不同机型、不同版本可能发生同一个Crash,某个Crash标识某段代码错误。
- Crash告警检测:针对新版本引入的Crash以及因为服务端变更引起的老版本Crash,增加告警功能,第一时间发现影响面广的Crash问题。
- Crash报告:每日报告,本日Crash情况,让团队的小伙伴能够清晰的了解到当天整体的crash情况,及时解决crash次数较多的问题。
Crash平台整体设计
得益于有赞在数据埋点方面的建设,Crash数据收集可以通过埋点通道的进行上报,然后通过Flink实时计算任务将上报上来的Crash实时进行捞取、分组、实时监控,最后落到我们自己的业务数据库中。Crash平台上可以对Crash进行浏览,分配,标记解决等等。整个Crash上报过程、后续处理流程如下图:
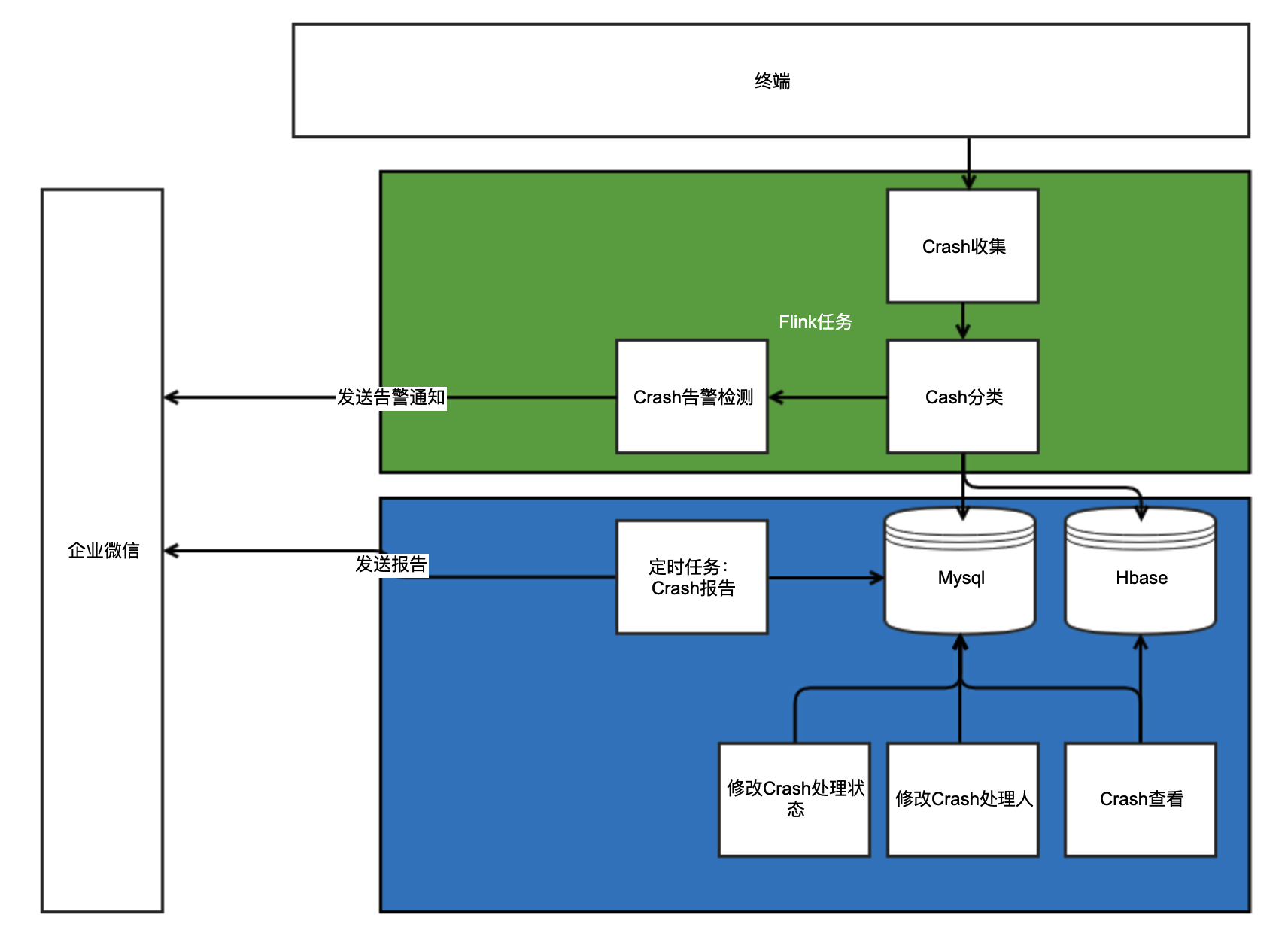
为了避免crash堆栈的数据量过大,crash堆栈等长字段存储至HBase. Mysql中只要存储前128预览字符与Hbase中的row_key即可
实现方案
1.1 Crash发生时的拦截+上报
Crash的拦截主要依靠各端系统的拦截机制。以Android为例,首先需要实现Thread.UncaughtExceptionHandler接口,在初始化的时候将线程默认的Handler替换为我们拦截的Handler(当然别忘了调用下原先默认的handler)。
1.2 Crash收集、数据整理--分组归类及自动分配处理人
1.2.1 Crash收集
Crash收集主要由埋点平台提供的实时计算任务来运行。
为什么要用埋点平台, 而不是用自己上报?
一个原因是避免重复造轮子,再者埋点平台需要设计之初就是为了超大数据量而设计,支持分布式存储,实时响应数据分析等等优点。而这些都是我们Crash收集所需要的,因此选择了通过埋点平台。
埋点平台在收到来自客户端的数据后为我们做了哪些工作
首先我们先来看下平台工作时的整体流程图:
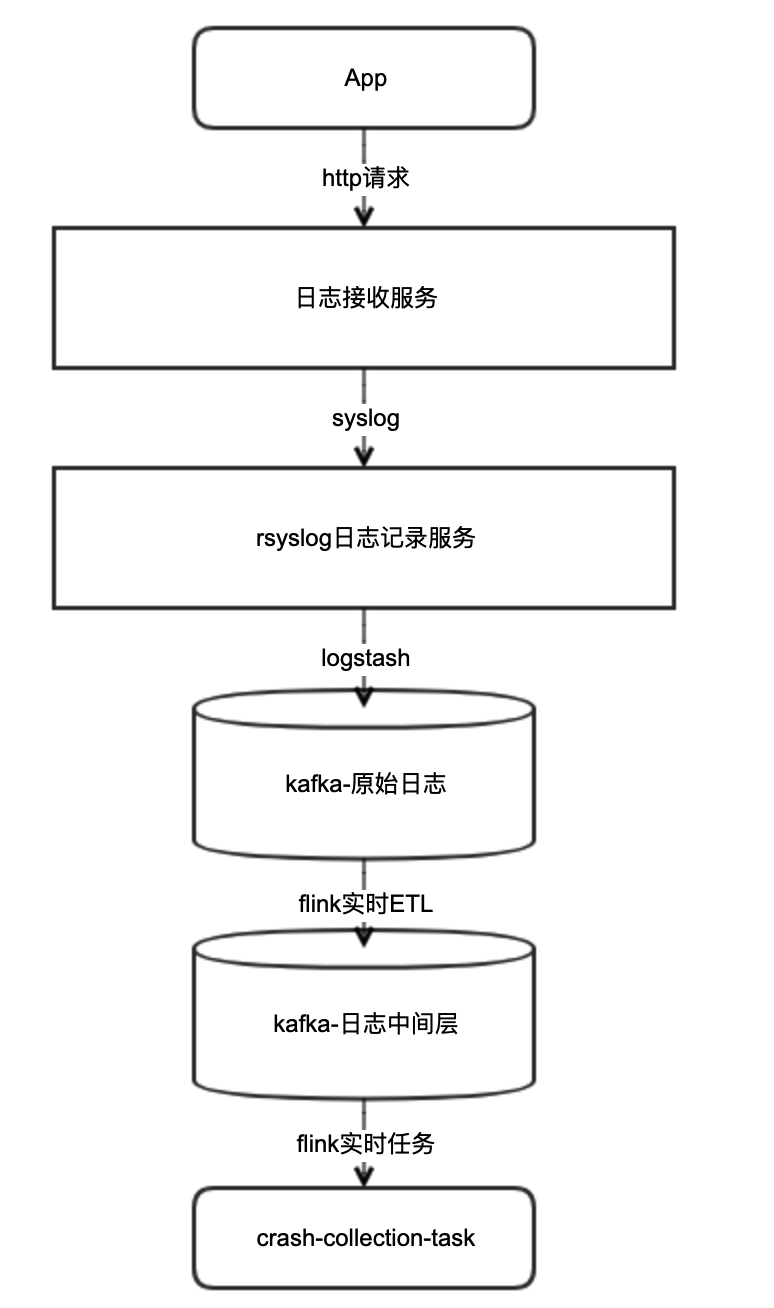
日志流转主要环节:
- 前端监控用户行为,收集并通过http请求上报
- NIO高并发日志接收服务将日志转发到rsyslog服务器中
- rsyslog服务器再通过logstash转发到kafka原始日志中
- flink实时ETl任务将原始日志加工成标准中间层格式,并继续落地到kafka
- 最后消息会到我们的Crash收集flink任务程序crash-clollection-task
crash-clollection-task实时任务只要订阅相关的Topic,就能实时接收到订阅相关的Topic消息:
// 隐去敏感数据,更改为测试数据
{
topic: "topic.log",
servers: "****",
type: "kafka010",
consumerGroup: "crash_collection_task"
}
因为我们订阅的Crash涉及到的有赞全部移动端的Crash,所以订阅了全量的数据。在代码中对数据进行过滤,只过滤Crash相关的数据:
@Override
public boolean filter(String line) {
try {
JSONObject data = JSON.parseObject(line);
String type = data.getString("event_type");
return Objects.equal(type, "crash");
} catch (Exception e) {
System.out.println(String.format("line:[%s]: \n解析发生错误:%s", line, e.toString()));
}
return false;
}
这样就只剩下我们关心的Crash相关的数据了。
1.2.2 分组归类、自动分配处理人
分组归类
分组归类是必不可少的一个工作,理想情况下。针对同一处代码错误的Crash上报上来,可以精确的将其分组归类。
但是因为代码混淆、同一处代码错误,错误堆栈缺不能完全匹配等等原因。做到这一点其实不容易。
那目前采取的做法是以App标识、系统、crash类型、crash错误原因、crash发生页面这五个维度来将crash分配到指定组。
其中App标识、系统是用来区分具体哪个App上报的crash的。
crash类型、crash错误原因是来根据crash发生的错误堆栈来区分出不同错误的类型。
以Android堆栈为例:
java.lang.OutOfMemoryError: Failed to allocate a 8306416 byte allocation with 502326 free bytes and 490KB until OOM
at dalvik.system.VMRuntime.newNonMovableArray(Native Method)
crashType为“java.lang.OutOfMemoryError”,crashReson为“Failed to allocate a 8306416 byte allocation with 502326 free bytes and 490KB until OOM”
crash发生页面是用来区分不同页面发生的同一个错误类型的。
最后将这些字段通过MD5算法计算出一个groupId
private String generateGroupId() {
String groupKey = MD5Utils.crypt(bundleId + crashType + crashReason + pageType);
return "Android-v4-" + groupKey;
}
自动分配处理人
自动分配处理人主要目的是为了让对应业务的人快速处理属于自己业务的Crash。为此做了两种方式的自动分配。
- 配置清单分配
- 历史页面自动分配
配置清单分配
我们先来看下配置清单:
{
"modules": [
{
"name": "xxxxSDK",
"key_stacks": [
"com.youzan.mobile.xxxx"
],
"cas_id": 10086
}
}
清单中配置着模块列表,模块中主要有两个字段keystacks(关键堆栈)、casid(模块负责人)。有crash上报时,会根据模块列表一一匹配其crash堆栈,看是否能匹配上若匹配上,则将该crash分配给该模块负责人。
自动分配处理人的初步匹配就是读取配置清单中的key_stacks, 然后从上报crash的堆栈中找是否包含目标堆栈。
如果包含就匹配成功,会将该crash发送至配置好的messenger群中去,并且@casid字段指定的处理人。
历史页面自动分配
如果清单匹配匹配失败,还会落入历史页面自动匹配。与清单匹配不同的是历史页面自动分配给该页面上次的处理人。
当手动分配crash给指定人时,这张表中会记录着这个crash发生页面分配给某个人。例如 工作台页面有一个crash发生,是分配给张三。那么当下次工作台页面有crash发生时,都会以此分配给张三
2.2 Crash实时监控、每日报告
得益于实时计算平台,我们能很容易做到实时监控。我们可以做到只要有Crash上报,就会向企业微信对应的处理人发送消息通知。这样做的在某种程度上来说是无意义的,尤其是疑难杂症问题多的时候,最多的时候一天能产生1000条通知,对于这样的通知无异于没有通知。
后来发现我们报上来大部分问题都是针对最新版本解决就OK,因为老版本要么是趋于稳定。要么如果因为后端某个接口变动,那么新老版本同样会受到影响。所以就只要监控最新版本(针对老版本我们只做超过一定阈值之后才告警) 。因此问题就变成如何版本过滤。
2.2.1 版本过滤
想要过滤版本就需要知道目前某个App的最新版本多少。目前有赞移动端的打包发版控制已经都使用自研的构建发布平台。
crash上报之后,只要它的版本号大于等于最新全量的版本号,就实时上报到秒级响应群,以便及时发现最新版本、灰度版本、项目测试包的crash问题。
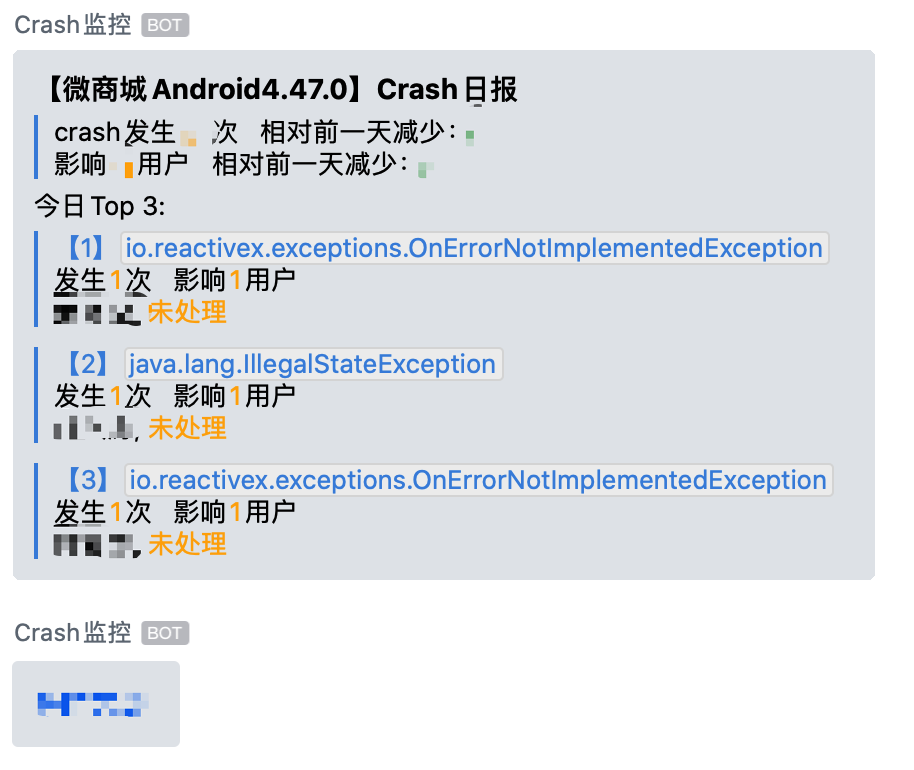
2.2.2 每日报告
每日报告功能有两个目的,一是为了让各个App负责人对每天的Crash大致状况有个大致上的了解。二是为了让没时间及时处理的小伙伴,当有属于自己的模块,发生次数、影响面比较大的Crash出现时要引起重视。
基于这样的目的我们在每日报告中加了每日Crash变化趋势(与前一日相比)、每日Crash Top N两大块。 这里主要讲下设计思路。
每日Crash变化趋势
日报中会取昨日的crash与今日的crash对比。如涨幅过大,则说明很可能新版本是存在问题的,需要引起注意。
碰到的坑
起初昨日与今日的Crash次数是按照自然日取的。这样有个问题,就是昨日的次数是一整天的,今天的次数不是一整天。所以这里对比,应该以报告时间往前24小时内、48~24小时,这样来对比。才能正常反馈Crash的变化趋势。
每日Crash Top N
排序规则
排序的背后是Crash的影响面大小,影响面大的排在前。这样让处理人与管理者能每天及时知晓影响大的Crash有哪些,是否需要及时处理等等目的。
我们为什么选择了Top3?
其实开始不是Top3 ,而是Top10。但是运转一段时间后发现,crash问题并不多,每天汇报时都报Top10,会有大部分次数少的crash,会让人失焦。无论是管理者还是处理人,都搞不清楚,某个问题是该及时处理还是可以延后处理。再集合运转的这一段时间的平均数据,最终选择了Top3。
技术实现
每日报告背后的技术实现有定时任务。起初使用的是SpringBoot自带的定时任务。
功能都能实现,有一个麻烦的点就是调试起来不方便。比如配置10点报告的,难道要等到10点么。或者改成1分钟一次,那调式完成之后是不是又得改回来?后来使用了TSP,具体可参考 有赞调度系统 TSP 调试起来非常方便,定时任务也像普通接口的形式书写即可。
日报的业务就是在不断的聚合查询当天的最新版本的数据,细节不再赘述,直接上日报最终效果图:
2.3 Crash反馈平台--管理后台
Crash管理后台的作用是提供Crash问题分析定位和Crash处理流程管理。
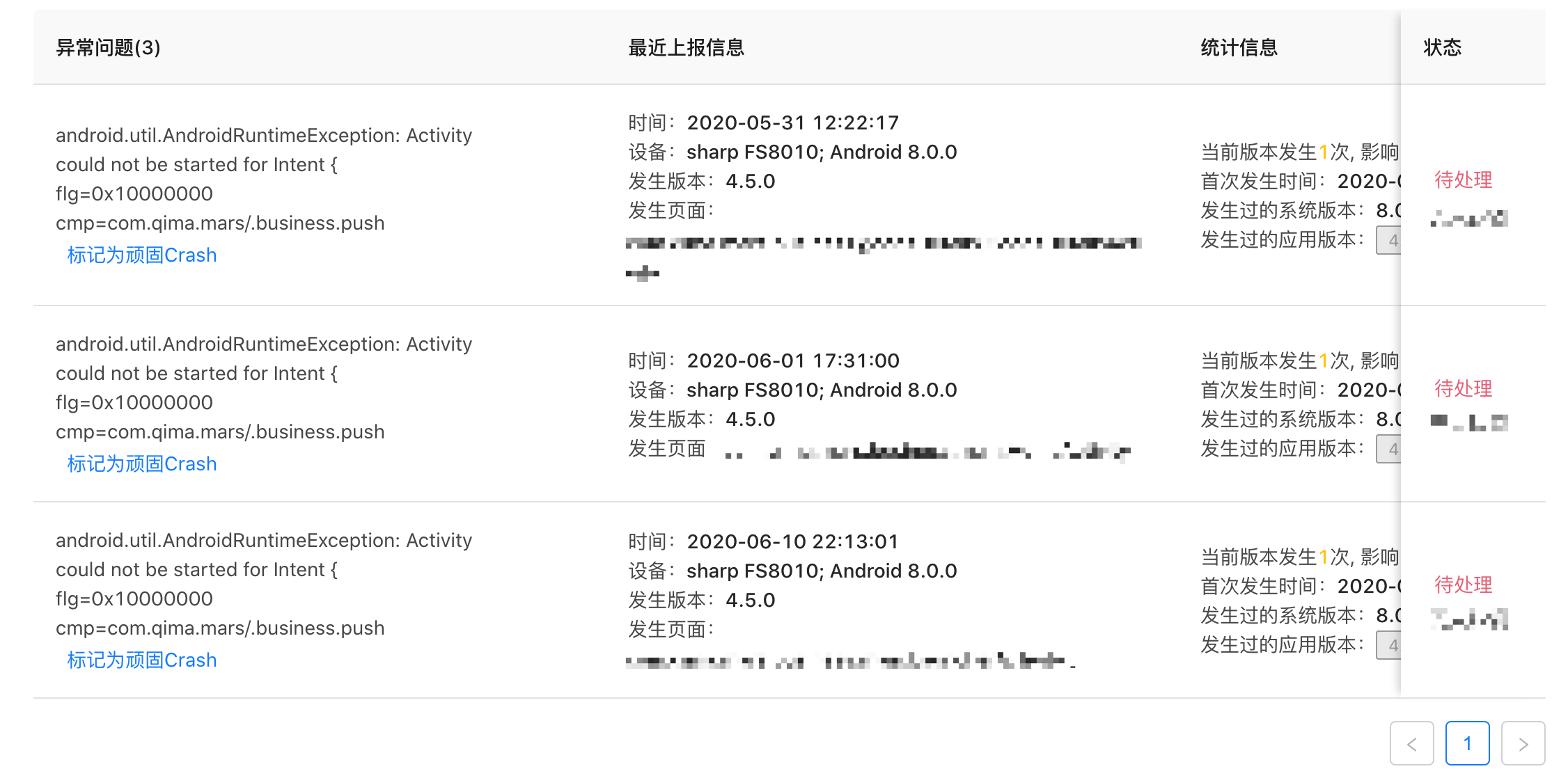
如何快速定位问题
为了方便快速定位在列表接口添加了最近上报信息、发生过的系统版本、发生过的应用版本来帮处理人第一时间发现问题。
有这样一个场景:
4.47.0改了某块代码之后,发布至线上,因为用户老数据的问题,Crash一直隐藏着带到了线上。 此时根据发生过的应用版本就能很快定位到Crash就是出现在4.47.0这个版本上。
类似的发生过的系统版本能帮助快速识别某个系统版本特定的问题。
Crash列表页信息:
更详细的排查维度
为了降低排查难度,增加了Crash页面路径、Crash出错堆栈、符号化等功能来增加排查的线索。
Crash详情信息:
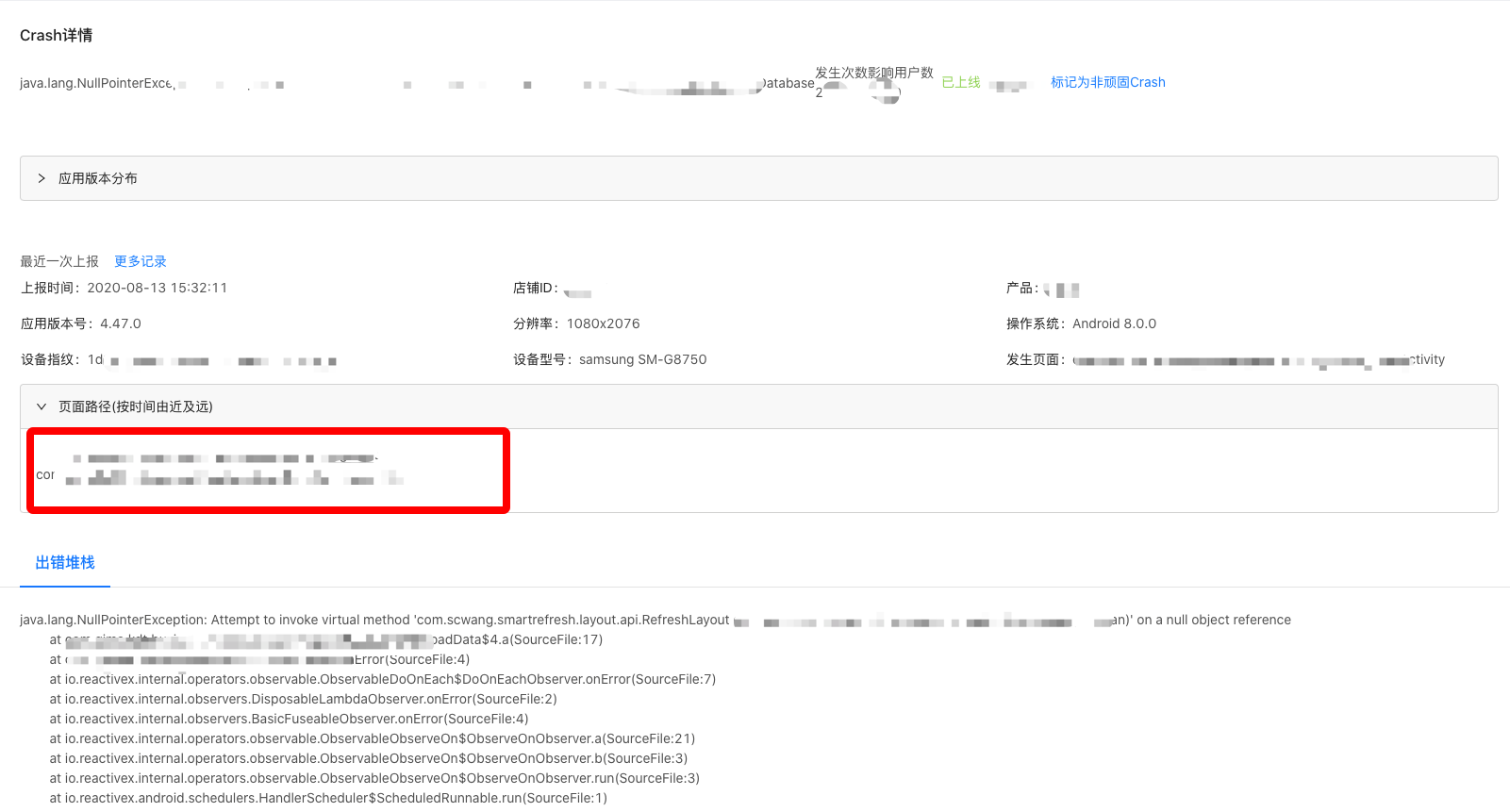
详情中展示全量的Crash堆栈信息,以及最新上报的一次设备相关信息。目的是为了帮助排查Crash。
Crash离线日志
值得一提的是某些时候需要再结合Crash时App端的日志来综合排查,这个点已经在着手设计排查,开始将Crash时跟日志绑定。后续在此页面会直接显示Crash时手机上的日志
总结
Crash反馈平台目前还没有实现Crash处理流程的闭环,存在大家在使用时不会去修改Crash的状态等问题,接下来会对这个流程做整体优化,提升整体协作效率。随着接入的业务方越来越多,为了保证业务方能更加容易、快速的排查与定位问题,修复问题,需要做的工作还不少,比如Crash的分组更加准确,Android堆栈符号化,顽固Crash定时提醒等等。
Crash反馈平台技术上来说他的综合性比较高,涉及的技术栈有大数据技术、后端技术、前端技术、移动端技术等4端技术栈。开发一个综合性的平台,不能单从技术层面去思考怎么解决技术上的问题,更多的需要从整个平台的目的出发。就crash平台而言,需要以去搭建一套能快速发现Crash、及时修复Crash为目标去思考。而技术更多的是“锄头”,它只是帮助实现“大丰收”的其中一个工具。
