
很多系统的优化最后往往是对 DB 的优化,比如索引优化、并发控制,但如果提前剧透本次优化过程,其实最终只调整了一个bit,并且性能几乎翻倍,猜测很多人会觉得这是标题党在吊胃口,说实话剧情如此翻转笔者也没猜到。
背景
应用 T 的数据库连接池使用了 druid 1.1.20 (https://github.com/alibaba/druid) ,在压测时碰到 DB 的性能瓶颈,表现是单机 cpu 使用率上不去,增加数据库连接数不会增加吞吐量,集群最终吞吐量维持在 1w 左右,其中 T 应用对数据库的主要操作是 select 和 insert。
排查
首先怀疑是否是 DB 的瓶颈,于是用 mysqlburst (https://github.com/xiezhenye/mysqlburst) 模拟核心请求,并发 500 下写入(insert) 能达到 4w 左右,应该来说还有比较大的优化空间。不过应用 T 在碰到瓶颈后尝试过扩容 2 台服务器后性能没提升,DB 的确是重点怀疑对象,于是在压测期间抓包:
sudo tcpdump -i eth0 port $db_port -s 0 -w /tmp/t.pcap
拷贝 t.pcap 到本地用 wireshark 分析,图1 是其中一条连接的请求详情。
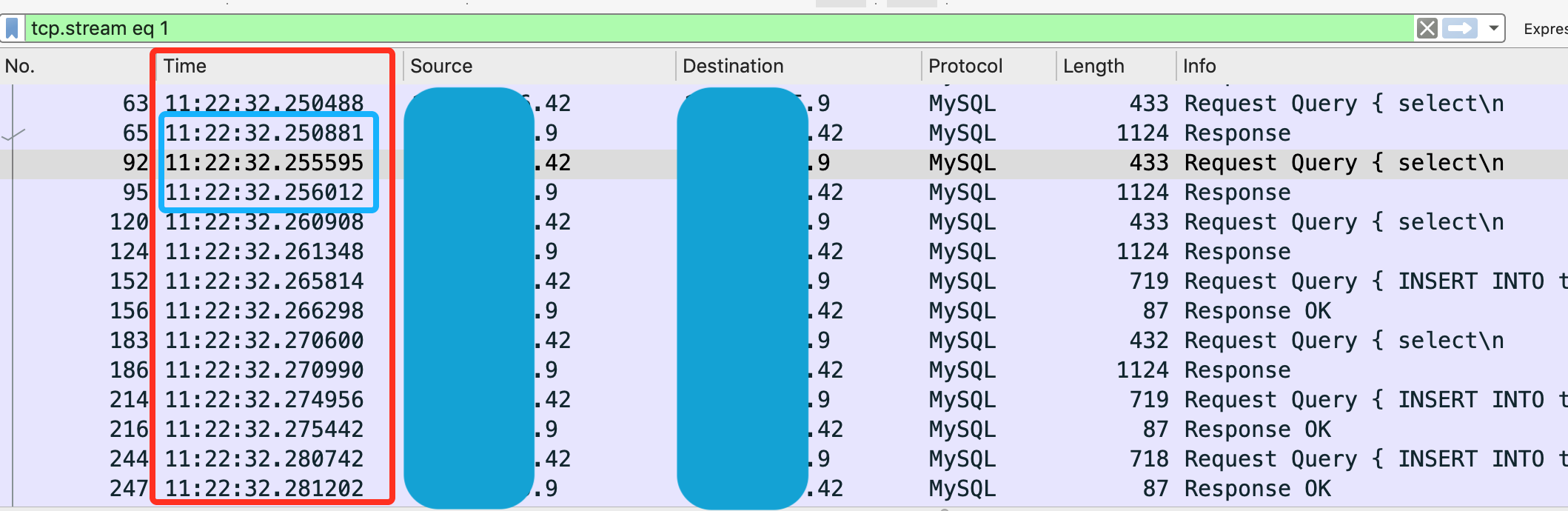
从上图中看出响应的时间普遍在 1ms 以内,但是上次请求完成后到下次请求的时间间隔平均有 4~5ms,这是连接池最大配置 15 的结果,最大连接数调整为 30 后发现请求后平均等待时间变为 9ms 左右,这能解释为什么连接池调整对性能没什么效果。
开始怀疑的是获取连接后需要执行一些监控或者调用链的采集,导致没有立即执行,于是打算用perf 工具查看一下性能,不过由于Java 的方法是jvm 维护的,所以需要先用工具 perf-map-agent 生成方法映射map。其实生成后对本次并没有多大帮助,后来想了一下 perf 工具一般寻找cpu 瓶颈,但真实压测cpu 其实水位只有 60% 左右。这里就顺带介绍这个工具,并且作为一个反面教材:性能问题分析需要先看看各项指标,分析瓶颈在哪,不能瞎碰运气。
这个现象其实表明要么是获取连接后没有立即查询或者是还连接慢,于是用 arthas (https://github.com/alibaba/arthas) 统计返还连接的平均时间:
## 进入 arthas 后使用 monitor 命令查看方法的统计信息
monitor $class_name $method
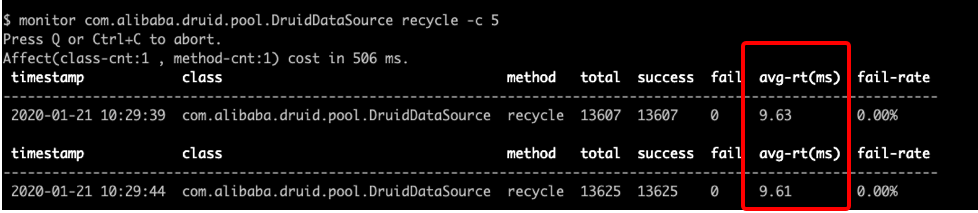
连接池配置 30 时和抓包的结果非常吻合,中间有 9ms 左右的空闲连接说明出现在还连接上,归还连接的等待比较要命,因为不还回去连接当然其它线程也就获取不了。接下来查找具体是哪里慢:
# arthas trace 命令
trace $class_name $method
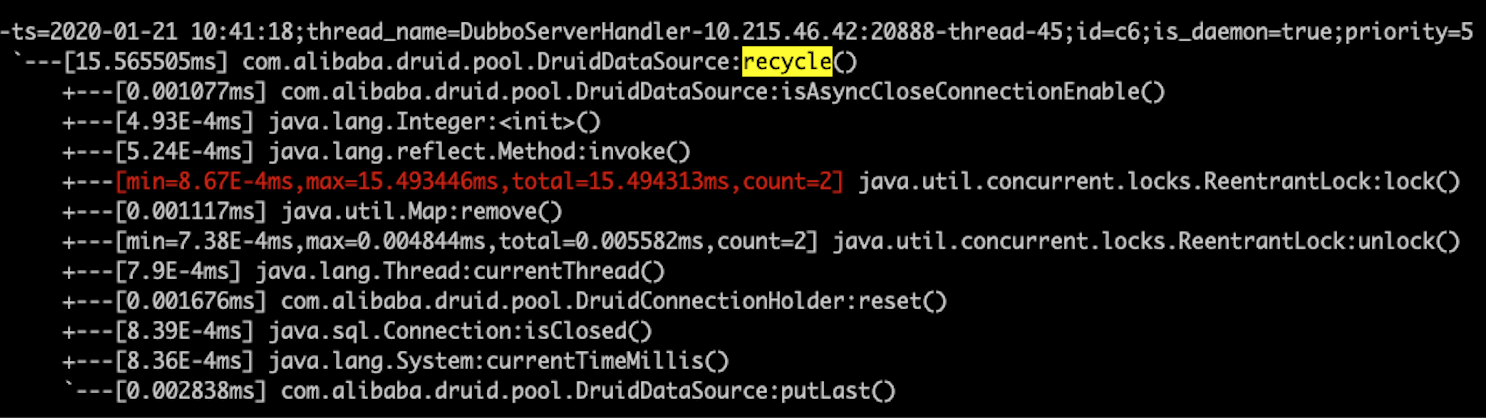
从上图中可见,主要耗时在其中的一次lock 操作,但是由于 recycle 方法中有多个锁操作,具体是哪次锁耗时这么久还未定位到,于是继续尝试查看锁调用的情况:

观察图4 发现 lockInterruptibly 的 rt 明显大于 lock,查看代码发现 locakInterruptibly 调用主要集中在 druid 获取连接中,所以基本上能确定慢的锁就是 com.alibaba.druid.pool.DruidAbstractDataSource#lock 这个对象。虽然 druid 中一把锁到处用性能应该会有影响,但这么差的性能的确大跌眼镜,第一时间还是觉得是不是哪里锁的时间太长,仔细分析了堆栈及业务日志并没有验证自己的想法,不过还是有些新发现,堵住的连接使用的都是公平锁,具体堆栈如下:
java.util.concurrent.locks.ReentrantLock$FairSync@60190bc0
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.locks.ReentrantLock$FairSync@60190bc0
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$FairSync.lock(ReentrantLock.java:224)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at com.alibaba.druid.pool.DruidDataSource.recycle(DruidDataSource.java:1913)
at com.alibaba.druid.pool.DruidPooledConnection.recycle(DruidPooledConnection.java:324)
at com.alibaba.druid.pool.DruidPooledConnection.syncClose(DruidPooledConnection.java:300)
at com.alibaba.druid.pool.DruidPooledConnection.close(DruidPooledConnection.java:255)
at org.springframework.jdbc.datasource.DataSourceUtils.doCloseConnection(DataSourceUtils.java:341)
优化
根据上面的观察猜测可能是公平锁影响性能,于是将改为非公平锁模式,其实 druid 默认配置为非公平锁,不过一旦设置了maxWait 之后就会使用公平锁模式。
// 设置druid 连接池非公平锁模式
dataSource.setUseUnfairLock(true);
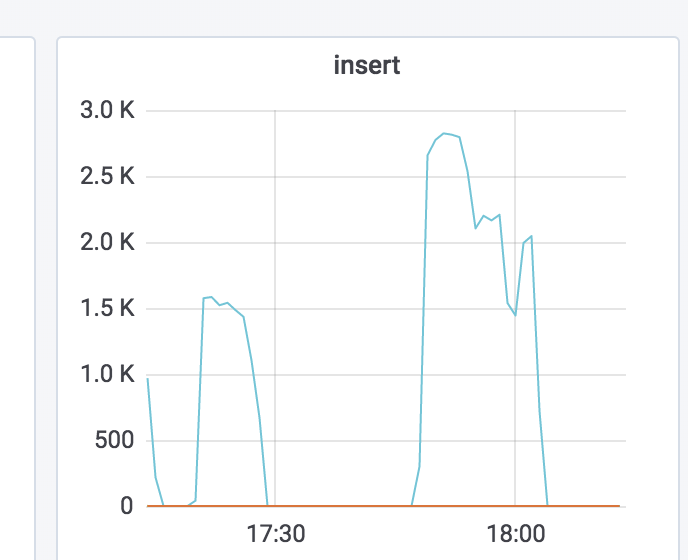
设置为公平锁后结果让人吃惊,简单的测试在(300并发下,30个连接)在一台机子上同时跑,非公平锁能跑到 9k+,公平锁只有5k 左右。然后小伙伴们立即修改 T 的代码,发现单机提升不少,见图5(其中前半部分是公平锁,后半部分是非公平锁,18:00 左右的下降是执行了 arthas 命令造成的额外性能损耗)。此时 cpu 已经跑到接近100%,说明本机 cpu 资源已充分使用。
小结
最终在只修改一个参数的请求下,单机性能提升接近一倍,集群的吞吐量也差不多提升 70%。不过公平锁与非公平锁有这么大的性能差距还是比较震惊的,其实单机几千请求量还真没想到瓶颈会是在加锁、释放锁这个过程,所以隐隐感觉还有更多的真相等待挖掘。
虽然最终一个小小的改动就达到了目的,其实整个优化过程中还是有些周折,并且是依靠小伙伴们的群体智慧完成的。还有一个小插曲是顺便调研了数据库连接池 HikariCP(https://github.com/brettwooldridge/HikariCP) ,使用 HikariCP 替换后发现效果还是非常不错,单机性能一下从 1.5k(druid 公平锁) 提升到接近 3k。其实 HikariCP 的一个优势就是快,当时都想要在公司推一波,不过要整个公司替换一遍也是不小的动作,虽然连接池使用上两者十分接近,但是配套的监控要重新弄一遍还是比较劳民伤财的。还好最终测试发现大部分情况下 druid 还不至于成为服务的瓶颈,而且配套的监控也比较全,如果真的追求更高的性能,HikariCP 是一个不错的选择。
