Overview
从有赞双机房开始到金融云架构,针对业务方在多机房的应该部署以及消息发送订阅需求,需要NSQ针对双机房以及多机房部署提供消息发送与订阅服务。本文主要介绍了NSQ双机房以及多机房设计以及经验总结。
场景和需求
下图1是一个机房内基本的NSQ消息生产和消费的部署。一个机房内生产者往NSQ集群发消息,多个消费者订阅消息。
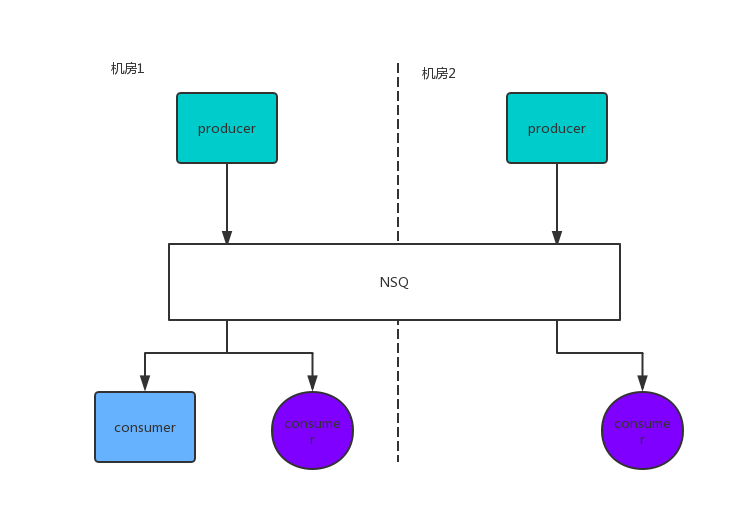
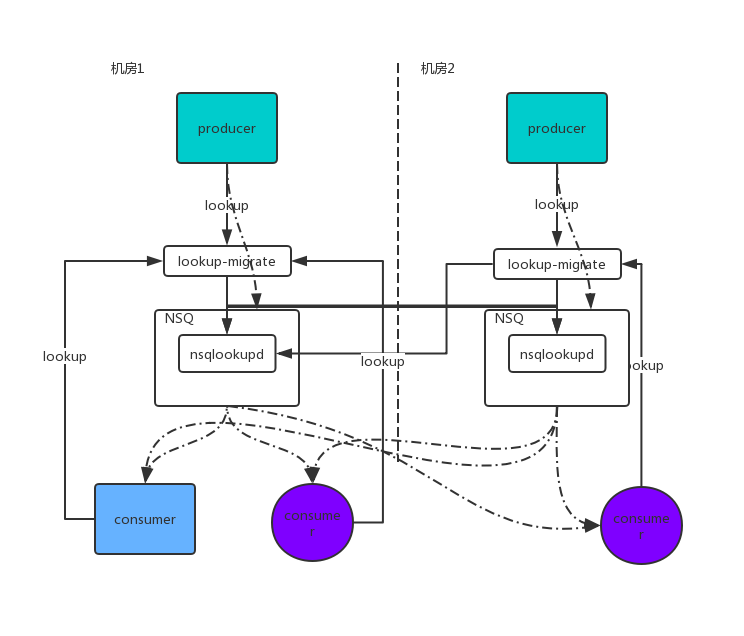
双机房场景下,业务的生产和消费在两个机房都有部署,也有可能部署在不同机房中,如下图2。
 对于生产者和消费者,在满足升级房生产消费的同时,NSQ的双机房方案需要做到业务方无感知,尽量降低业务方的使用成本。同时,NSQ的双机方案署要能够实现topic切换,当某一机房不可用时,通过切换机房能够尽快恢复消息生产和消费。
对于生产者和消费者,在满足升级房生产消费的同时,NSQ的双机房方案需要做到业务方无感知,尽量降低业务方的使用成本。同时,NSQ的双机方案署要能够实现topic切换,当某一机房不可用时,通过切换机房能够尽快恢复消息生产和消费。
NSQ双机房设计
我们结合NSQ中的服务发现组件nsqlookupd的功能实现NSQ的双机房功能。nsqlookupd是NSQ组件中用于topic生产以及channel订阅的额服务发现的组件,消息生产者/消费者通过nsqlookupd的查询接口发现目标topic所在的nsqd节点。目前有赞使用的NSQ经过分布式改造后,由于topic会在nsqd节点之间动态分配,消息在生产或消费前需要通过nsqlookupd进行服务发现。
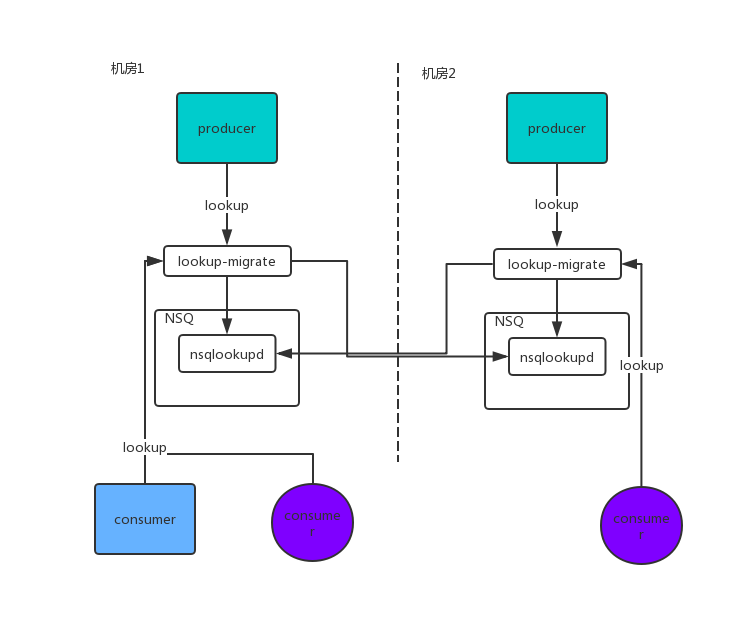
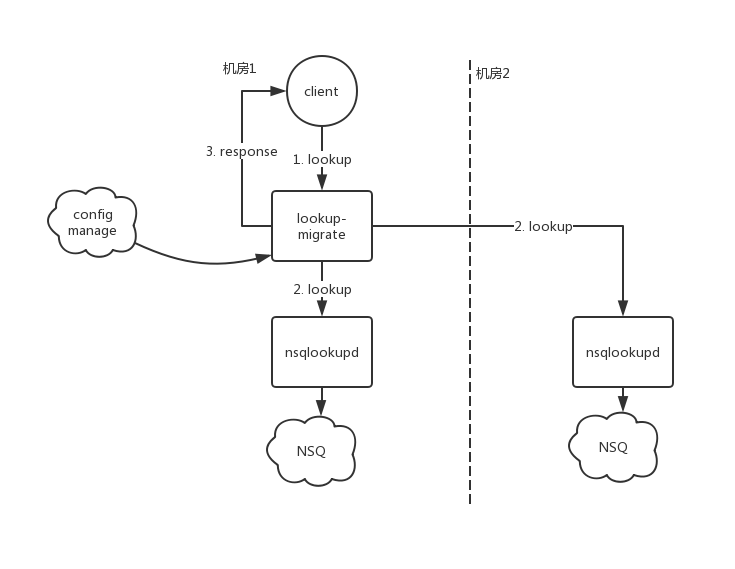
有赞NSQ的双机房服务发现由nsqlookupd的服务发现入手,引入了lookup-migrate(以下简称migrate)。lookup-migrate作为nsqlookup的代理,机房内的lookup请求首先发送到lookup-migrate。migrate根据双机房配置,返回对应机房中的nsqd(图3)。
 在双机房NSQ集群部署上,采用了镜像部署,一个topic在2个机房中都存在。由于有赞NSQ集群内已经实现了副本机制,消息只在一个机房落盘,不同步到对端机房。一旦本地机房NSQ无法正常服务,已经落盘的消息不会丢失(恢复前无法被消费)。
在双机房NSQ集群部署上,采用了镜像部署,一个topic在2个机房中都存在。由于有赞NSQ集群内已经实现了副本机制,消息只在一个机房落盘,不同步到对端机房。一旦本地机房NSQ无法正常服务,已经落盘的消息不会丢失(恢复前无法被消费)。
根据代理的路由配置,NSQ的双机房方案经历了两个阶段。
NSQ双机房方案一期
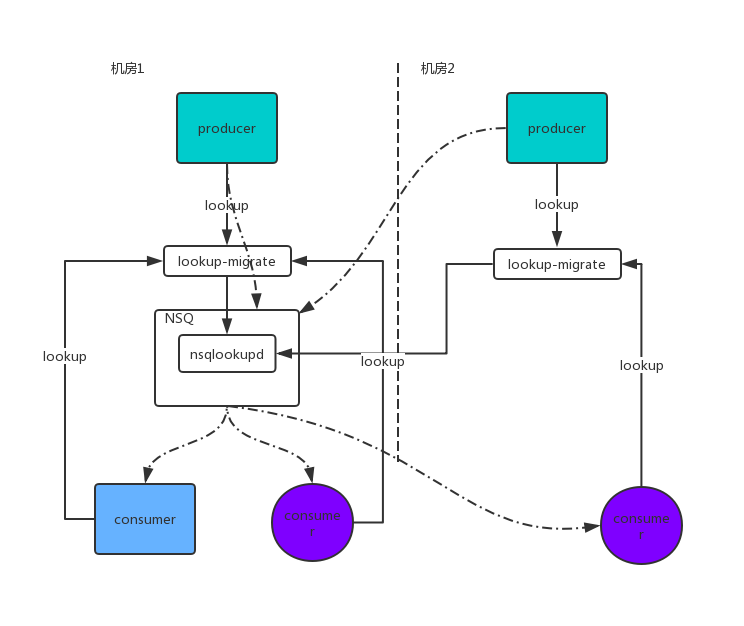
NSQ的双机房方案目前计划分为两期,一期中读写流量全部通过migrate导到一个机房,对端机房中的NSQ集群作为冷备。如图4中所示,其中虚线的部分为消息的读写流量。由于本期方案中应用的读写全部在单以及防中,对于双机房部署的应用存在消息跨机房生产或消费的问题,存在一定的网络延迟。
NSQ双机房方案二期
一期稳定运行一段时间后,而其中通过迁移的方式将一部分流量平滑导入到对端机房。二期中基于“本地生产,双机房消费”的策略,将应用的写请求路由到本地NSQ集群,对于消费者的消费请求,migrate返回双机房的nsqd节点信息,如图5中所示。
写入的lookup请求统一路由到本地集群,而作为消费者会去消费双机房中所有topic的节点。相较于一期,二期不存在跨机房生产方的写入延迟,消费者通过消费所有机房的节点,保证了对于单机房部署的消费者应用能够消费到全量的消息。
lookup-migrate的路由以及迁移策略
migrate的lookup路由涉及双机房NSQ的lookup查询以及查询结果的整合。先了解一下youzan NSQ的一个lookup请求以及返回结果。
youzan的lookup请求中,增加了access的读写参数,lookup能够根据access来区分读写请求。
{
"channels": [
"default"
],
"meta": {
"extend_support": true,
"ordered": false,
"partition_num": 2,
"replica": 2
},
"partitions": {
"0": {
"broadcast_address": "127.0.0.1",
"distributed_id": "127.0.0.1:4250:4150:871995",
"hostname": "nsq1",
"http_port": 4151,
"id": "127.0.0.1:59208",
"remote_address": "127.0.0.1:59208",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
},
"1": {
"broadcast_address": "127.0.0.2",
"distributed_id": "127.0.0.2:4250:4150:1033760",
"hostname": "nsq2",
"http_port": 4151,
"id": "127.0.0.2:54296",
"remote_address": "127.0.0.2:54296",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
}
},
"producers": [
{
"broadcast_address": "127.0.0.1",
"distributed_id": "127.0.0.1:4250:4150:871995",
"hostname": "nsq1",
"http_port": 4151,
"id": "127.0.0.1:59208",
"remote_address": "127.0.0.1:59208",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
},
{
"broadcast_address": "127.0.0.2",
"distributed_id": "127.0.0.2:4250:4150:1033760",
"hostname": "nsq2",
"http_port": 4151,
"id": "127.0.0.2:54296",
"remote_address": "127.0.0.2:54296",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
}
]
}
查询结果中,partitions包含了topic的分区信息映射,producers中包含了分区信息中的nsqd节点以及开源版本的nsqd节点作为兼容方案。客户端在建连时依据如下约定:首先根据partition中的分区节点建立连接,之后从producer的节点中找出不属于partitions的节点建连。客户端会定时根据lookup的查询结果,更新nsqd的连接。
以此为基础我们进行改造,使得lookup的返回信息中能够包含2个机房的nsqd节点信息。partitions中包含一个集群的nsqd信息,将另一个集群的nsqd节点信息更新到producers数组中。假设topicA配置为1分区2副本,双机房中2个节点ip分别为11.0.0.1以及21.0.0.1。整合后的lookup结果为:
{
"channels": [
"default"
],
"meta": {
"extend_support": true,
"ordered": false,
"partition_num": 1,
"replica": 2
},
"partitions": {
"0": {
"broadcast_address": "11.0.0.1",
"distributed_id": "11.0.0.1:4250:4150:871995",
"hostname": "nsq1",
"http_port": 4151,
"id": "11.0.0.1:59208",
"remote_address": "11.0.0.1:59208",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
},
"1": {
"broadcast_address": "21.0.0.2",
"distributed_id": "21.0.0.2:4250:4150:1033760",
"hostname": "nsq2",
"http_port": 4151,
"id": "21.0.0.2:54296",
"remote_address": "21.0.0.2:54296",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
}
},
"producers": [
{
"broadcast_address": "11.0.0.1",
"distributed_id": "11.0.0.1:4250:4150:871995",
"hostname": "nsq1",
"http_port": 4151,
"id": "11.0.0.1:59208",
"remote_address": "11.0.0.1:59208",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
},
{
"broadcast_address": "21.0.0.2",
"distributed_id": "21.0.0.2:4250:4150:1033760",
"hostname": "nsq2",
"http_port": 4151,
"id": "21.0.0.2:54296",
"remote_address": "21.0.0.2:54296",
"tcp_port": 4150,
"version": "0.3.7-HA.1.9.5"
}
]
}
上述lookup查询结果的整合便由lookup-migrate完成。以下为lookup-migrate的流程图,首先migrate根据配置信息查询对应的lookup,之后将结果整合后返回结果。
迁移场景下,需要将生产以及消费的流量迁移到目标机房的NSQ上,考虑到尽量不引起消息积压,对于非顺序消费的topic主要有以下步骤:
- migrate将topic消费者的消费请求代理到两个机房的nsqd;
- 消费者建连后,migrate将topic生产者的生产请求代理到目标nsqd;
- migrate将topic消费请求代理到目标nsqd,和源机房的连接断开;
对于顺序消费业务,则需要先切换生产到目标机房,在确认源机房channel已无消息积压后,将消费请求迁移至目标机房。
一个在双机房代理基础上拓展出来的场景则顺序topic的不停机扩容。对于基于顺序topic的生产消费场景,当topic需要扩容时,由于涉及到分区变化可能引起消费到的消息在扩分区过程中出现乱序。通过migrate进行扩容,先对对端机房的topic进行扩容,扩容完成后,将顺序消息的生产和消费依次迁移至对端机房的NSQ集群后,在对本地机房进行扩容,等到全部扩容完成后将生产和消费迁移会本地机房。
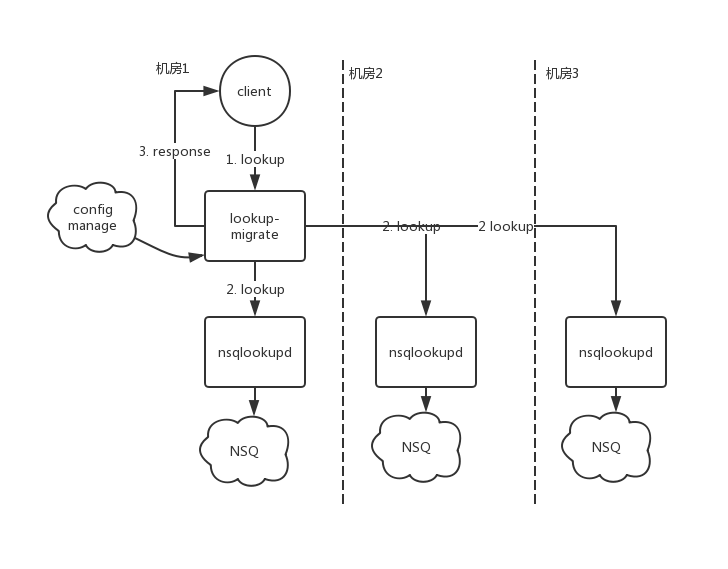
双机房到多机房
随着业务增长,NSQ集群上topic数量以及读写流量日渐增加,同时为了满足更多的业务场景,公司机房再度增加。migrate的双机房方案的实现主要基于NSQ在两个集群间的迁移设计,而多机房场景下,生产消费流量要求在多个集群之间路由。针对新的多机房集群需求,我们重新设计了migrate的数据结构,提出了一种保存lookup数据格式,以及一种lookup地址的schema。
{
"topics": [
{
"topicA": {
"#C": [
"lookup_addr1",
"lookup_addr2",
"lookup_addr3"
],
"#P": "lookup_addr1"
}
},
{
"#D": {
"#C": [
"default lookup_addr1",
"default lookup_addr2",
"default lookup_addr3"
],
"#P": "default lookup_addr"
}
}
]
}
其中,#C代表消费者要消费的各个nsq集群lookup地址数组,#P代表生产者的要生产的nsq集群lookup地址,#D表示默认的topic所对应的生产以及消费lookup地址。通过这个数据结构将topic与对应的生产和消费NSQ集群建立关联。实例中的lookup地址在实际过程中可能对应了比价长的URL,为了简化配置的数据量,通过一个lookup的schema将实际的lookup地址关联到NSQ集群名称上。
{
"lookupSchema": {
"nsq1": "this.is.url.of.nsq1:4161",
"nsq2": "this.is.url.of.nsq2:4161",
"nsq3": "this.is.url.of.nsq3:4161"
}
}
支持多机房lookup代理的流程如下图7
经验总结
在此针对migrate实现和运行过程中遇到的问题进行总结。
首先是部署问题,作为nsqlookupd的代理,对外暴露的端口为nsqlookup的公共端口。而nsqlookupd作为topic资源的管理和服务发现组件,除了lookup接口之外还有其他公共接口。migrate在实现时,或者透传lookup请求之外的其他请求,或者通过其他反向代理,劫持lookup请求到migrate的端口。两种方案各有利弊,方案一额外实现了请求透传,而方案二对于运维有一定的要求,代理配置以及端口映射之间的梳理需要一定的工作量。
lookup查询结果通过migrate进行聚合时,消费者的lookup结果可能包含多个NSQ集群的lookup信息,migrate在查询各个NSQ集群时存在并发,如果migrate返回的结果中partition信息是更具lookup查询返回结果决定的,比如,先返回的节点设置为partition。可能会导致部分客户端在处理连接时对已建连的连接重复进行断开/重连。migrate在进行lookup查询前,根据NSQ集群信息进行排序,第一个lookup地址的查询结果设为为partition的信息。
migrate需要针对NSQ集群可能返回的异常做处理,对于消费lookup请求,当查询的多个集群中有查询失败的情况下,返回给客户端的lookup相应中可以合并成功返回的节点信息。
有赞NSQ的nsqlookupd支持listlookup查询来发现集群中所有的nsqlookupd主备,migrate可以考虑通过listlookup发现集群中的nsqlookupd节点,将代理的lookup请求负载到各个nsqlookupd节点中。
