有赞发号器多机房方案
发号器一般用来产生全局唯一 ID,有赞发号器的设计及背景参见文章《如何做一个靠谱的发号器》,本文在此基础上进行扩展,提供多机房发号与集群拆分能力,下文中使用 March 表示发号器服务。
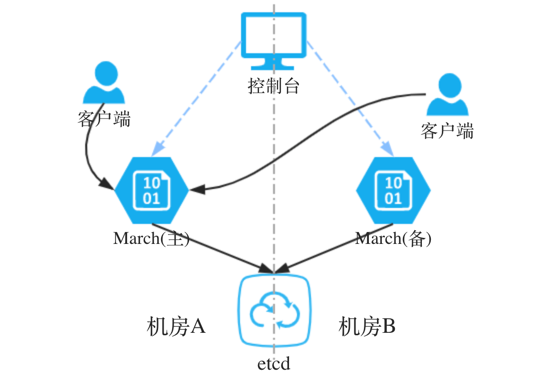
图1 展示了改造前发号器双机房的架构,其中:控制台负责管理发号器配置,March 包括主备节点,主节点负责发号,备节点进行灾备,etcd 作为持久化存储。
问题
根据图1 架构可以看出,将 etcd 跨多机房部署,借助 etcd 本身的就能保证在多机房的数据一致性及可用性,但在实践中还是会碰到一些问题:
- 若只有两个机房,没法实现机房级别的高可用(极端情况下一个机房完全不可用时需要人工恢复)
- March 单主节点模式,多机房时造成大量的跨机房请求,网络稳定性和时延都会变差
- March 单主节点不利于水平扩展
- 集群拆分需要停机,运维复杂度高
多机房方案
针对现有架构碰到的一些问题,进行了如下的改造:
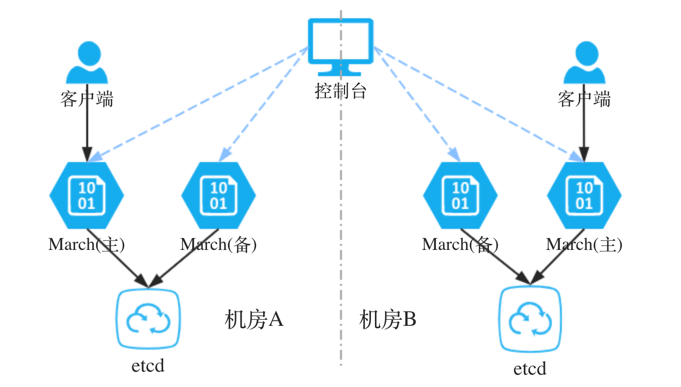
图2 架构进行调整后可以发现已经解决了上述的问题中的:1(高可用)、2(跨机房请求)、3(水平扩容) 这些问题,接下来会详细说明方案如何实现及问题4(动态拆分)的解决方案。
有经验的读者可能会想到,发号器多机房同时发号只需要在ID 上选取几个bit 位作为机房的标记就万事大吉了,其实有赞的实现并非如此,其中原因牵涉到一些历史背景。读过《如何做一个靠谱的发号器》的读者应该有印象,有赞内部的发号器可以分为两种类型:1. 单纯的 Sequence,即一个不断递增的整数;2. Timestamp 相关的,在可选时间精度的基础上,支持额外加一段 Sequence。这两种类型都支持批量获取,即一次性获取[ id, id + batch_size ) 的区间,这样能大大减少客户端对 March 服务的请求数,发号效率有质地提升。细心的读者可能已经发现使用低位的 bit 作为机房标志是没法兼容现有的缓存机制。如果把机房标志放在高 bit 位呢,这个对于 Timestamp 类型是可行的,并且在原有的设计中 Timestamp 类型已经预留好了机房标志位,该版对此稍做扩展就完成了 Timestamp 的升级,因此本文接下来主要讨论 Sequence 类型的双机房升级。
对于 Sequence 类型,将机房标识放在高位上看似能解决问题,但会碰到几个问题:1. 作为标识的位已经被占用,假设ID 只有8位,并且当前已经发号到 0110 0000,那么使用高3位作为机房标识,就可能引起重复发号;2. 本身 Sequence 是为了让生成的ID 近似有序,高位加上后不同机房生成的ID 值相差过大。
这里采用分段的思想来处理 Sequence 类型,关键配置包括:
| 配置 | 含义 |
|---|---|
boundary |
边界长度,生成的 ID 对 boundary 取余后要处于 [lower, upper) 区间内,保持所有机房相同 |
lower |
上边界 (包含边界点的值),取值范围 [0, upper) |
upper |
分段的 (不包含边界点的值),取值范围 (lower, boundary] |
限制条件:不同机房间的区间长度必须相同,并且发号区间不能相交。如果机房1 的配置为 (boundary1, lower1, upper1),机房2 的配置为 (boundary2, lower2, upper2),它们必须满足如下的约束条件:
boundary1 == boundary2
lower1 != lower2
// 假设 lower2 > lower1,需满足如下条件
0 <= lower1 < upper1 <= lower2 < upper2 <= boundary
这样保证了机房1 生成的 id1 和机房2 生成的 id2 不会相同:
id1 mod boundary1 ∈ [lower1, upper1)
id2 mod boundary2 ∈ [lower2, upper2)
boundary1 = boundary2 && upper1 <= lower2
=> id1 mod boundary ≠ id2 mod boundary
=> id1 ≠ id2
为了方便理解,举个例子来说明双机房下时是如何工作的,假设配置如下:
// 机房1 的配置
{
"boundary":100,
"lower":0,
"upper":50
}
// 机房2 的配置
{
"boundary":100,
"lower":50,
"upper":100
}
机房1 生成的 ID 序列为: (0, 1, 2, ..., 48, 49, 100, 101, ..., 148, 149, 200, 201, ...);
机房2 生成的 ID 序列为: (50, 51, 52, ..., 98, 99, 150, 151, ..., 198, 199, 250, 25, ...)。
对于机房1 来说,如果当前生成的最大 id 为 45,需要批量获取 10 个 id,由于区间 [50, 99) 不属于机房1,则需要跳到下一个区间开始生成id, 区间为 [100, 109]。这里需要限制批量获取的数量不能大于子区间的大小,上例中最大一次能获取50 个 id,因此实际中区间长度需要设置的不能太小。
扩展&迁移
接下来讨论如何在上述方案的基础上实现高效地运维。在原始方案中如果想从发号器服务中拆分出部分 key 到另一个集群需要非常小心谨慎,并且还需要停服务,最可怕的是一些业务在迁移完成后发现还有配置指向老的服务,更不用说一些谁都不敢动的应用。
改造后扩展其实比较安全,流程总结为:
- 搭建新的发号器集群
- 在原集群中配置发号区间
- 在新集群中配置发号区间,保证满足约束条件
- 配置发号的初始值,开始发号
整个扩展过程中无需停机,并且可以多集群同时工作保证充足的时间验证。
迁移只需要在扩展的基础上进行回收操作,简单的说就是在一个集群删除再在另一个集群扩展。虽然理论上已经没问题了,单如果每个步骤完全由人来操作还是容易出错的,所以在有赞内部我们实现了一个控制台,完成约束条件的判断和具体步骤的执行。
小结
发号器天然具备机房间独立发号的优势,实际开发中还需要考虑对原有功能的兼容、支持在运行中升级、兼顾运维的可操作性。一个可靠的系统还需要尽量减少人的操作,提供一套自动化执行平台,减少运维的负担。
