有赞订单同步的探索与实践
一 引子
有赞是提供商家SAAS服务,随着越来越多的商家使用有赞,越来越多的需求铺张而来,搜索或详情的需求会越来越多,针对需求及场景,之前提到过的订单管理架构演变及AKF架构等在这两篇文章里已经有所体现,而这些数据的查询来自于不同的Nosql,怎么同步这些非实时存储系统将是一个很有趣的事情
同步由来
先不说同步是什么,一般情况下,公司达到一定规模,有类似全文检索的需求或者高频key:value的时候,大家会推荐ES+HBase的架构体系去完成搜索和详情的需求,而现实中,绝大多数情况下生产环境不会将数据直接写入到ES或者Hbase,大家都会优先写入数据库,不进行双写的操作是因为增加链路影响业务。当然Hbase可能还好一点,ES本身就是非实时查询系统(为什么是非实时,有兴趣的可以去看看ES读写流程),这种情况下也造就了ES和HBase的一个准实时系统。如图所示:
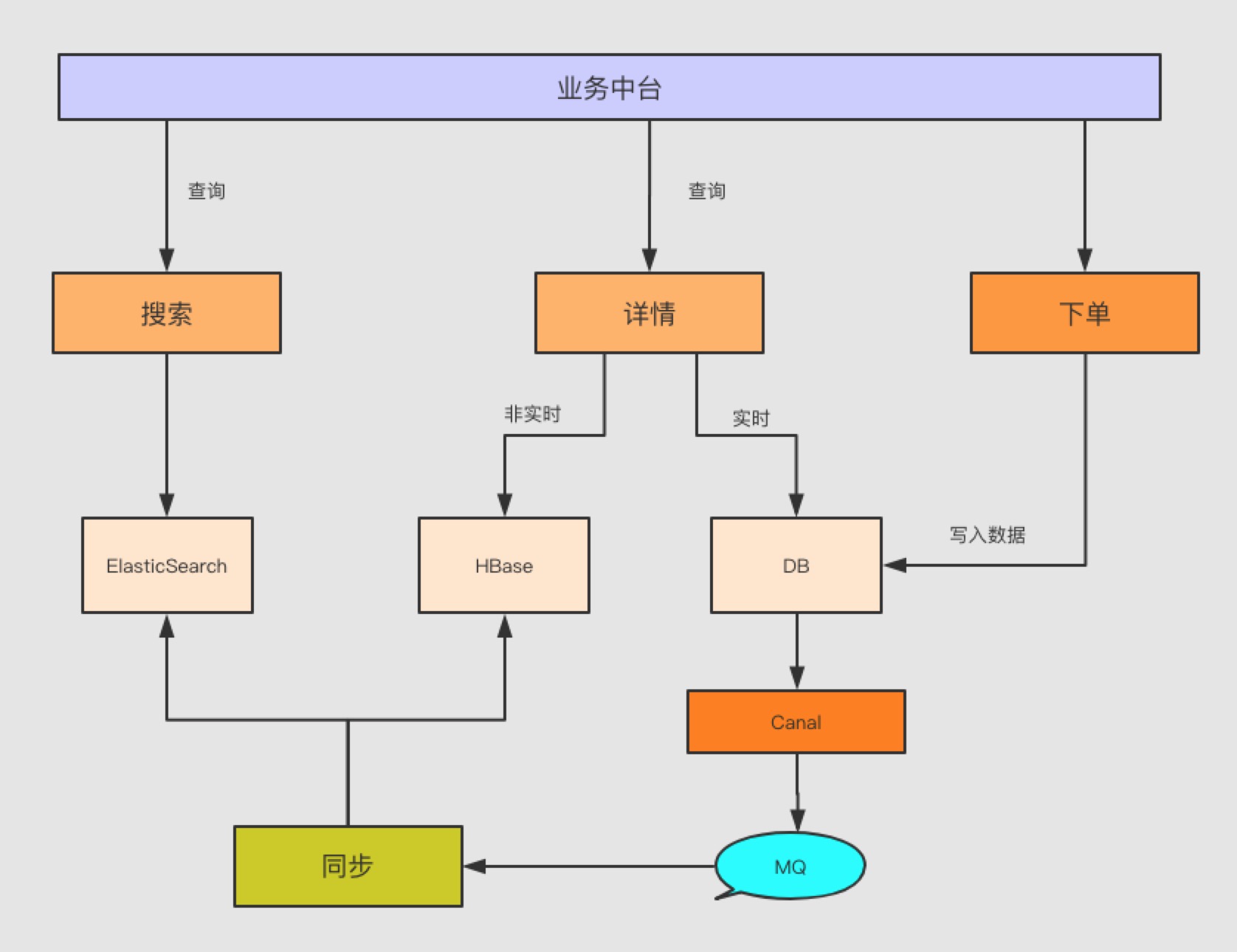
二 同步
实现同步基础 - 单表同步
乱序问题
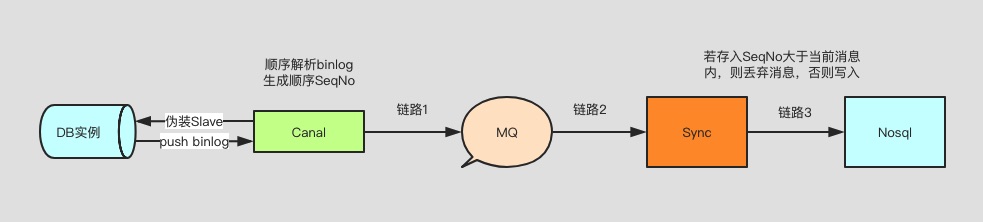
单表同步如图所示
 业务场景中,在这任何一个序号链路中,如果并发出现同一主键的两条消息,同时在Nosql中没有做版本控制,都有可能造成消息乱序问题,
而相反,如果通过顺序解析binlog的同时,为每条statement sql执行的结果分配一个顺序SeqNo,该SeqNo保证有序(tip2),再通过Nosql中控制乐观锁就可以解决顺序性问题
业务场景中,在这任何一个序号链路中,如果并发出现同一主键的两条消息,同时在Nosql中没有做版本控制,都有可能造成消息乱序问题,
而相反,如果通过顺序解析binlog的同时,为每条statement sql执行的结果分配一个顺序SeqNo,该SeqNo保证有序(tip2),再通过Nosql中控制乐观锁就可以解决顺序性问题
HBase同步
Hbase同步相对来说比较简单,Hbase内部拥有timestamp协助控制每个qualify的版本,只要让timestamp传入上文所说的顺序SeqNo,那么就可以保证每个字段读取出来的数据是最终一致性的。
ES同步
ES同步针对单表场景可以通过index的操作来进行写入,index可以采用exteneral版本也称作外部版本号来进行控制,同样适用上述的SeqNo来做乐观锁去解决该问题
同步过程图
实现同步进阶 - 多表同步
乱序问题
多表同步基于单表同步的基础上做相关的同步,如图所示
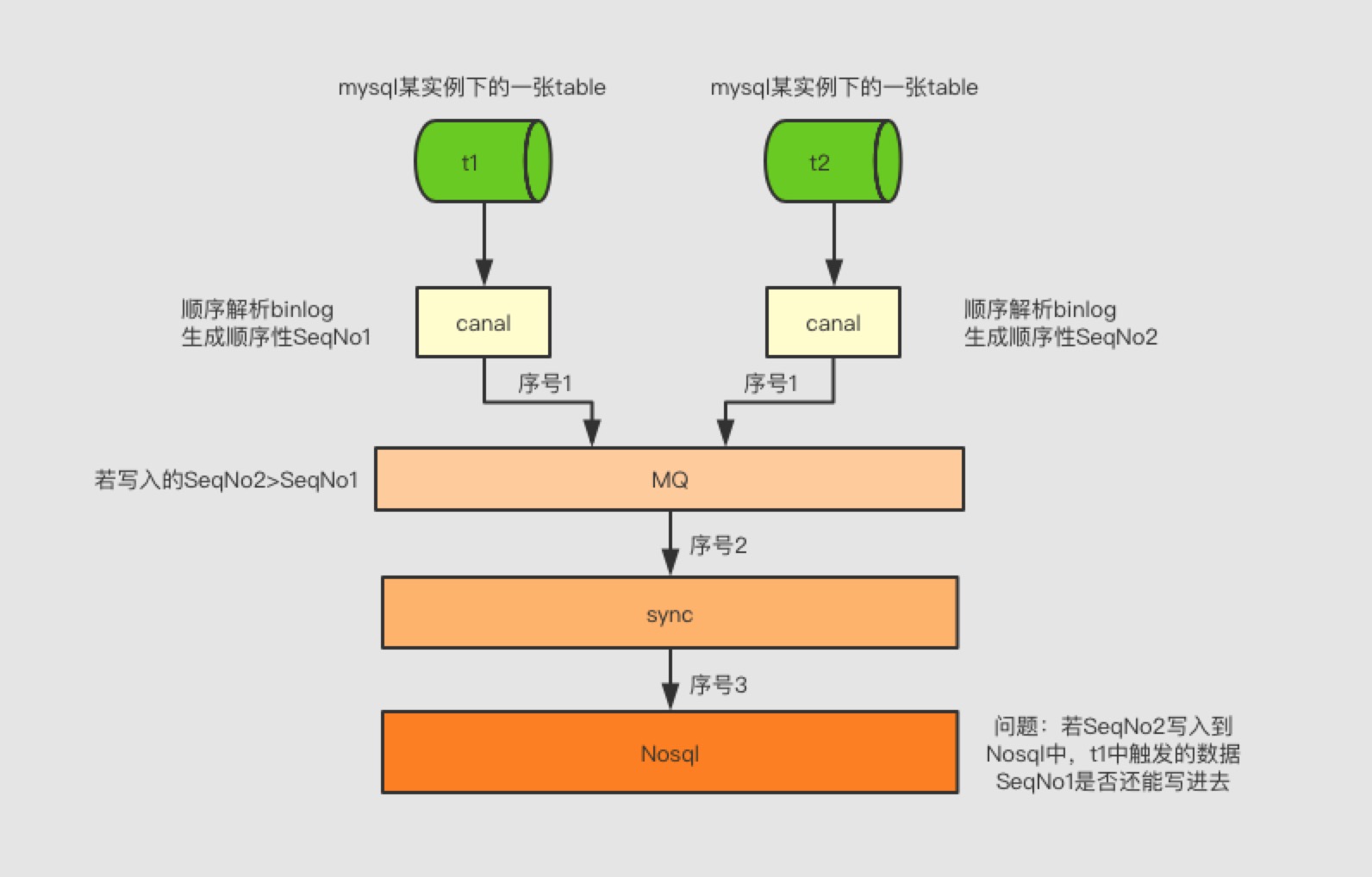 当数据库的两张表(不关系是否在一个实例上,如果不在,还更惨,SeqNo还不一定能够保证有序)触发了更新操作,假设t1生成binlog的SeqNo小于t2生成binlog的SeqNo,若t1这条消息因序号链路中的网络抖动或其它原因造成消费晚于t2,也就是t2的binlogSeq先写入Nosql中,那么就会造成一个t1的数据无法写入到Nosql中
当数据库的两张表(不关系是否在一个实例上,如果不在,还更惨,SeqNo还不一定能够保证有序)触发了更新操作,假设t1生成binlog的SeqNo小于t2生成binlog的SeqNo,若t1这条消息因序号链路中的网络抖动或其它原因造成消费晚于t2,也就是t2的binlogSeq先写入Nosql中,那么就会造成一个t1的数据无法写入到Nosql中
HBase同步
其实上述多表同步乱序的问题并不是绝对的,针对Hbase这种自带列版本号的将会自动处理或丢弃低版本数据,同时针对这种情况,设计成每个table表中的字段都会列入到Hbase中。 举个例子,针对订单的情形存入订单主表和订单商品表
场景1:1
针对订单主表,我们写入的数据以订单号做hash,然后以 hash值:订单号作为主键降低热点问题,同时定义单column family,qualifiy格式为 表:字段 value为对应的value值,timestamp为SeqNo,如图所示:

场景1:n
针对订单商品表,我们写入的数据同样以订单号生成相应的rowkey,同时定义单column family,qualifiy格式为 表:字段:对应记录的id值 value为对应的value值,timestamp为SeqNo,如图所示:
 通过上述写入,能够针对具体到某个字段都有对应的timestamp值的更新,为后期写入更新数据能够更新到具体字段级别
通过上述写入,能够针对具体到某个字段都有对应的timestamp值的更新,为后期写入更新数据能够更新到具体字段级别
ES同步
针对上面的同步乱序问题,ES没有HBase这种列版本号,ES只有doc级别的version,如果上述真的出现SeqNo2>SeqNo1,且SeqNo2早于SeqNo1写入到ES中,则就会出现SeqNo1的内容无法写入,也就会造成顺序不一致的情况。那如何去解决这个多表同步问题呢?
既然会乱序,那让它有序就好了,数据保证有序不就能够解决这个事情嘛,让整个链路有序也就代表canal消费binlog数据保证有序且丢到MQ中有序,MQ然后保证顺序投递到Sync消费处理程序中,通过消费一条消息然后ack告诉MQ是否成功,已达到保证所有数据全部有序(若多线程或多机器处理MQ中的多个分区都是会存在问题)。如图所示
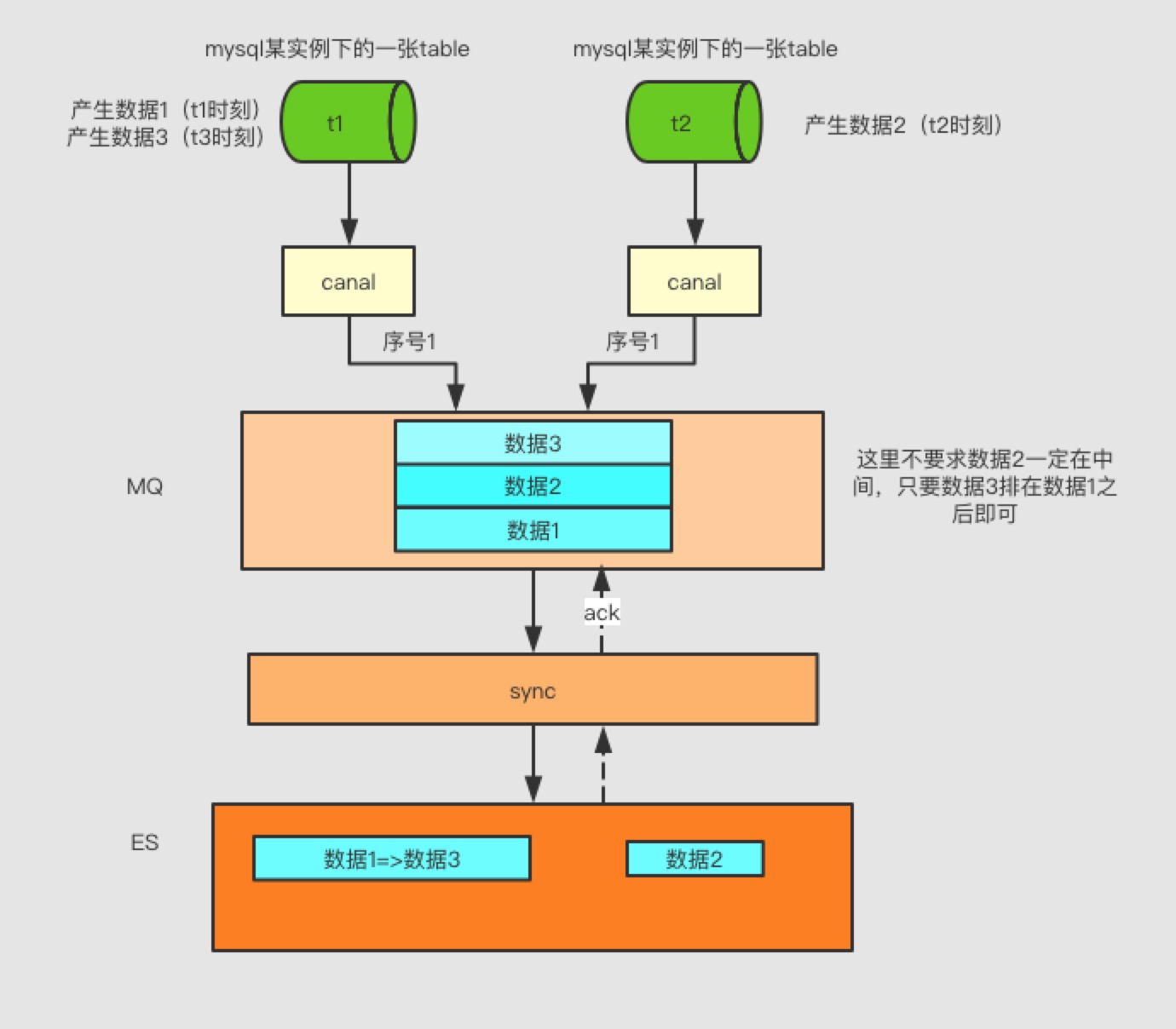 如此只要保证t1表的数据和t2表中的数据在ES不互相关联,每个数据写入的时候按照update方式写入(如果不存在需要做一次create操作),这样就能保证所有数据按照顺序执行。
如此只要保证t1表的数据和t2表中的数据在ES不互相关联,每个数据写入的时候按照update方式写入(如果不存在需要做一次create操作),这样就能保证所有数据按照顺序执行。
配置化同步
上文已经讲到数据同步是由一个数据源(这个数据源可以来自于MQ、Mysql等)同步到另外一个数据源(Mysql、ES、HBase、Alert等),也就是一个管道的过程。
借鉴了一下logstash官网,同样处理流程分为input、filter、output组件,这些流程称之为task任务,如图所示:
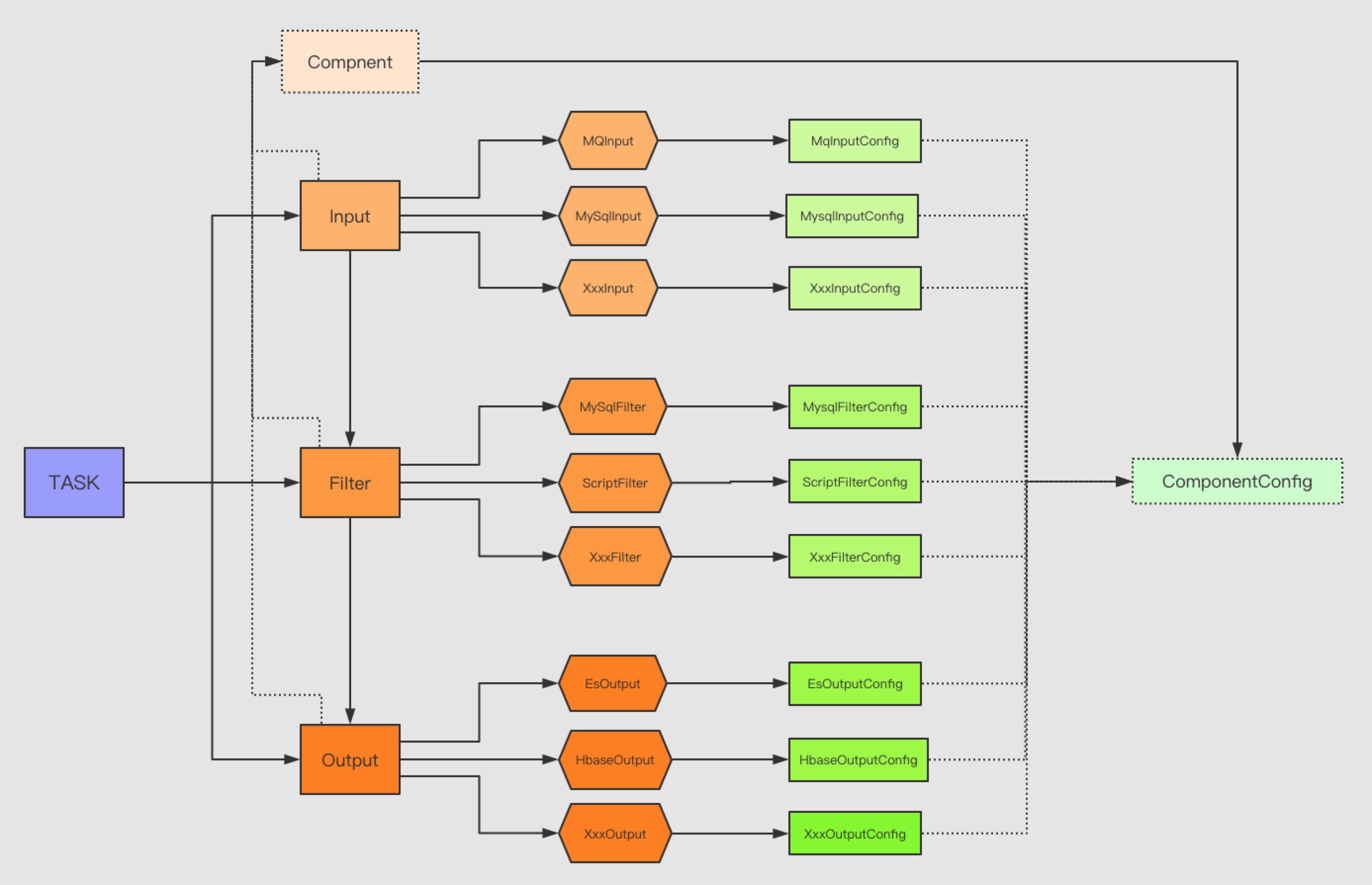 通过这些组件,抽象化出每个组件都有对应的配置,由这些配置来进行初始化组件,驱动组件去执行流程
简单来说,只需要在页面中配置一些组件,无需开发任何一行代码就能实现同步任务。如图所示:
通过这些组件,抽象化出每个组件都有对应的配置,由这些配置来进行初始化组件,驱动组件去执行流程
简单来说,只需要在页面中配置一些组件,无需开发任何一行代码就能实现同步任务。如图所示:
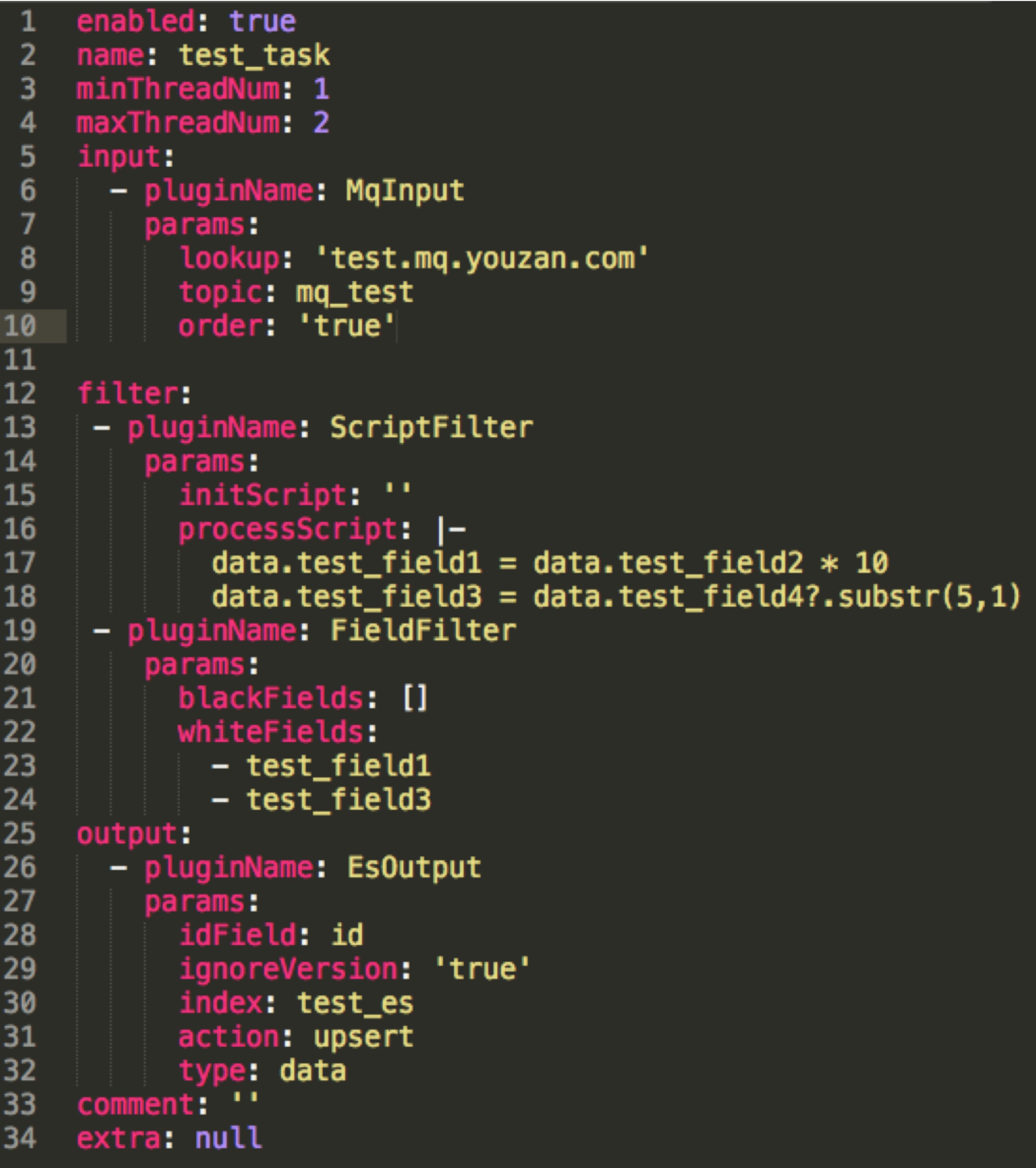 通过一系列的配置,就能配置出一个任务,针对业务逻辑,可以采用动态语言groovy来实行脚本化处理(复杂业务场景可以通过UDF函数来做支持),针对mqinput拿到的字段然后经过处理,经过过滤filter等,可以直接拿到相关的数据进行组装,然后配置化的写入到ES中,无需开发任何一行java代码即可实现流程自动配置化,针对需求也能够高效率快速支持
通过一系列的配置,就能配置出一个任务,针对业务逻辑,可以采用动态语言groovy来实行脚本化处理(复杂业务场景可以通过UDF函数来做支持),针对mqinput拿到的字段然后经过处理,经过过滤filter等,可以直接拿到相关的数据进行组装,然后配置化的写入到ES中,无需开发任何一行java代码即可实现流程自动配置化,针对需求也能够高效率快速支持
性能瓶颈
上述就能解决ES多表同步的问题,但是同样会存在一些问题
1.性能瓶颈问题
2.失败堆积问题
性能瓶颈:比如写入量超级大的场景情况下,而Sync消费程序只能针对MQ中的分区(kafka的partition概念)消费,每个分区只能有一个线程去执行,消费速率与消费分区成正比,与消费RT成反比,尤其是大促场景下就会造成数据消费不过来,数据堆积严重问题
失败堆积:因为是顺序消费,只要某个分区的某条消息消费失败,后续消息就会全部堆积,造成数据延迟率超高
所以建议用顺序队列的场景除非是业务量没用性能瓶颈的情况下可以采取使用,而怎么去解决顺序队列或者去掉顺序队列呢?
用顺序队列无非就是保证有序,因为ES没有HBase的字段级别版本号,目前订单采用的是用HBase做一层中间处理层,解决该问题,如图所示:
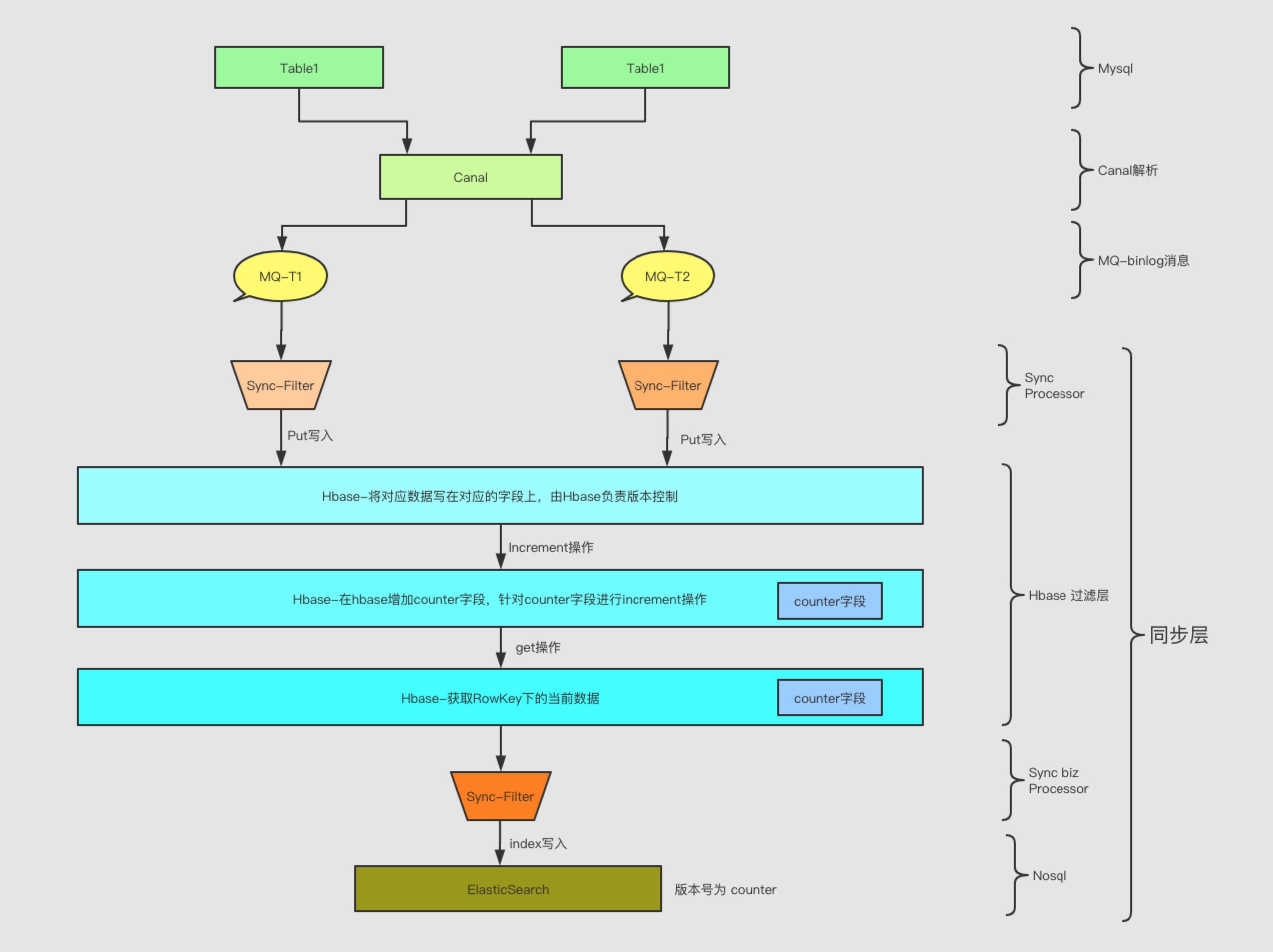 通过借助HBase字段级别版本号帮助每个表保证表内部字段有序,同时put写入完数据之后,通过额外字段version做increment操作,当这两个写入动作完成之后立马get操作拿到HBase的数据写入到ES中,无论并发程度如何,最终至少有一次的get请求拿到的版本version字段是最大的,用该version作为ES的外部版本号解决ES版本号问题
通过借助HBase字段级别版本号帮助每个表保证表内部字段有序,同时put写入完数据之后,通过额外字段version做increment操作,当这两个写入动作完成之后立马get操作拿到HBase的数据写入到ES中,无论并发程度如何,最终至少有一次的get请求拿到的版本version字段是最大的,用该version作为ES的外部版本号解决ES版本号问题
用此方案会有好处
1.HBase协助管理内部字段版本,同时根据内部操作,协助ES拿到对应的版本,且数据能拿到最新数据
2.去掉了顺序队列,HBase具有良好的吞吐,相对于顺序队列拥有更大的吞吐量
3.横向拓展增大消费速率
4.ES可以采用index操作,性能更好
也有弊端
1.HBase存在抖动的情况,以及主备切换问题
因为存在抖动或者准备切换问题,会造成数据不一致,我们该怎么去解决这个事情呢?
未来扩展
目前订单同步是通过加载配置文件形式来做的,也就是横向拓展的机器都会去加载同一份配置文件,各个任务通过异常解耦,理论上不会有影响,但是会存在加载任务的重要度的问题。
举个例子
1. 我需要一台机器临时去消费数据解决线上问题
2. 有个量级很大但又不是很重要的任务,想不影响其他任务的进行
3. 要做对比,增量延迟对比或全量对比数据,但又不希望影响其他数据
4. 查询日志需要所有机器查看查询(当然,公司有内部日志系统,可直接上去查看)
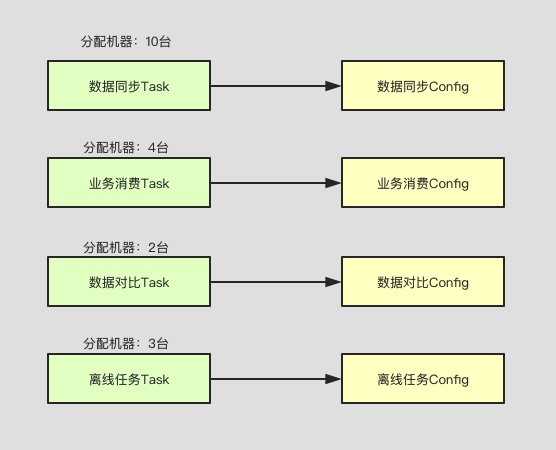
如此,可以让同步系统无状态化,每个任务的配置加载有任务配置平台来进行配置,指定相关的机器做相关的处理,扩容也可以动态申请扩容,如图所示,可以自由分配机器处理不同的任务
三 一致性保障
上文讲了有赞在处理订单的时候怎么讲数据同步到ES或HBase,数据来源于binlog,写入到MQ,也就是说处理的来源来自于MQ 简单一句话来讲:我们不生产消息,我们是消息的搬运工 ‘搬运工’的角色可以做一些事情,同样有赞在处理数据对比也是如此,这章讲讲'搬运工'可以做什么
数据对比
上述一般情况下不会出问题,那如果出问题了怎么办,需要做数据对比,而数据来源就是我们刚刚抛弃的顺序队列,顺序队列有个缺点就是堆积,同样我们也可以利用堆积的特性,让其第一条消息堆积十分钟,那么后续消息基本上也会堆积十分钟,然后就可以消费这个消息进行数据拉取,拿到最新的数据进行数据对比,如图所示
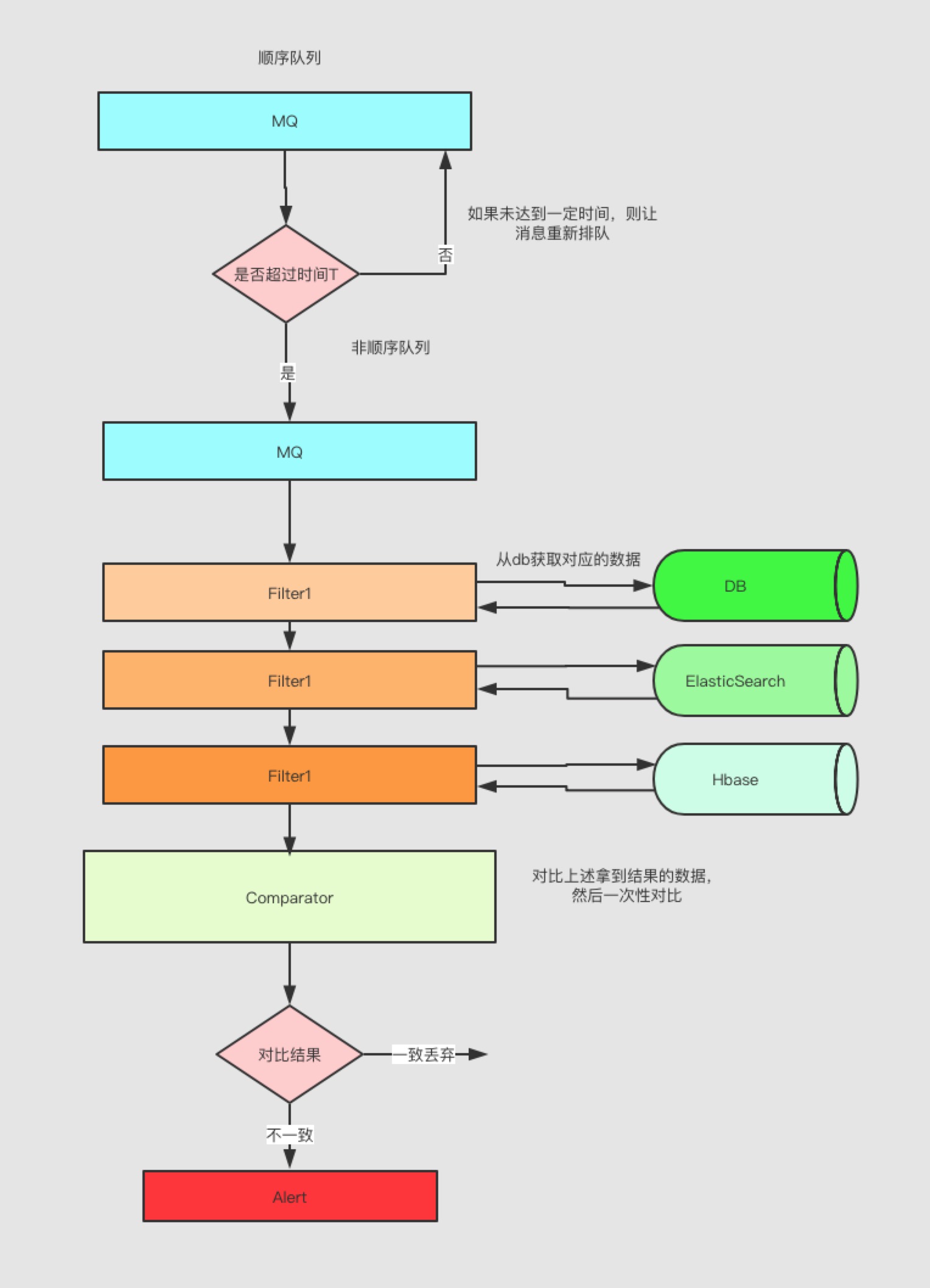 通过对比结果发送到alert中,就可以知道哪些数据不一致,频率多少,这也是一种同步(mq->filter->alert)!
通过对比结果发送到alert中,就可以知道哪些数据不一致,频率多少,这也是一种同步(mq->filter->alert)!
全量对比/数据刷入
上述我们讲到数据同步到Nosql中,但是只是讲了增量的一个过程,涉及到历史数据,就需要对历史数据进行迁移,同样,这也是一种数据同步,后面将会出相关博文怎么去做数据同步。
四 Tips
tip-1
为什么有赞选canal解析binlog,而不是采用业务消息进行数据同步?
- 数据表被更改,可能无法感知写入到对应的nosql中,
- 顺序性问题无法得到相关保障,
- 业务消息并不能拿到所有相关的数据进行写入到nosql中
tip-2
SeqNo实现方式,为什么不用binlogoffset
因为canal实例与mysql实例是1:N(推荐1:1),而大部分业务场景同一种数据一般会落在同一个实例上,canal就可以通过该台实例的时间与每秒处理的个数相结合 如:timestamp*10000+counter++,而不用binlogoffset的原因是mysql的实例挂了话,binlogoffset可能会乱序。
五 结语
有赞交易订单管理承接了亿级流量的同步任务,面临着众多的需求挑战,从最开始的mysql到如今的产品化的同步任务,从单表同步到多表同步,从单索引到多索引,从增量到全量,都有不同的解决之道,如今新兴搜索中台更是承接亿级搜索和同步流量,如有兴趣,可投简历wangqi@youzan.com,我们一起共同探讨。
