一、引子
根据CAP原理,分布式系统无法在保证了可用性(Availability)和分区容忍性(Partition)之后,继续保证一致性(Consistency)。我们认为,只要存在网络调用,就会存在调用失败的可能,系统之间必然存在着长或短的不一致状态。在服务化流行的今天,怎样及时发现系统服务间的不一致状态,以及怎样去量化衡量一个系统的数据一致性,成为每个分布式环境下的开发者需要考虑并解决的问题。
二、背景
以交易链路为例,存在着如下一些潜在的不一致场景:
- 订单支付成功了,但是订单状态却还是“待付款”
- 物流已经发货了,但是订单上面还是“待发货”
- 银行退款已经到账了,但是订单上面还是“退款中”
- 订单发货已经超过7天了,但是却没有自动完成
- …
上述每个业务场景,都可能产生用户反馈,给用户带来困扰。业务对账平台的核心目的,就是及时发现类似问题,并及时修复。使问题在反馈前即被提前处理。
三、挑战
那么一个业务对账平台,会面临着哪些挑战?
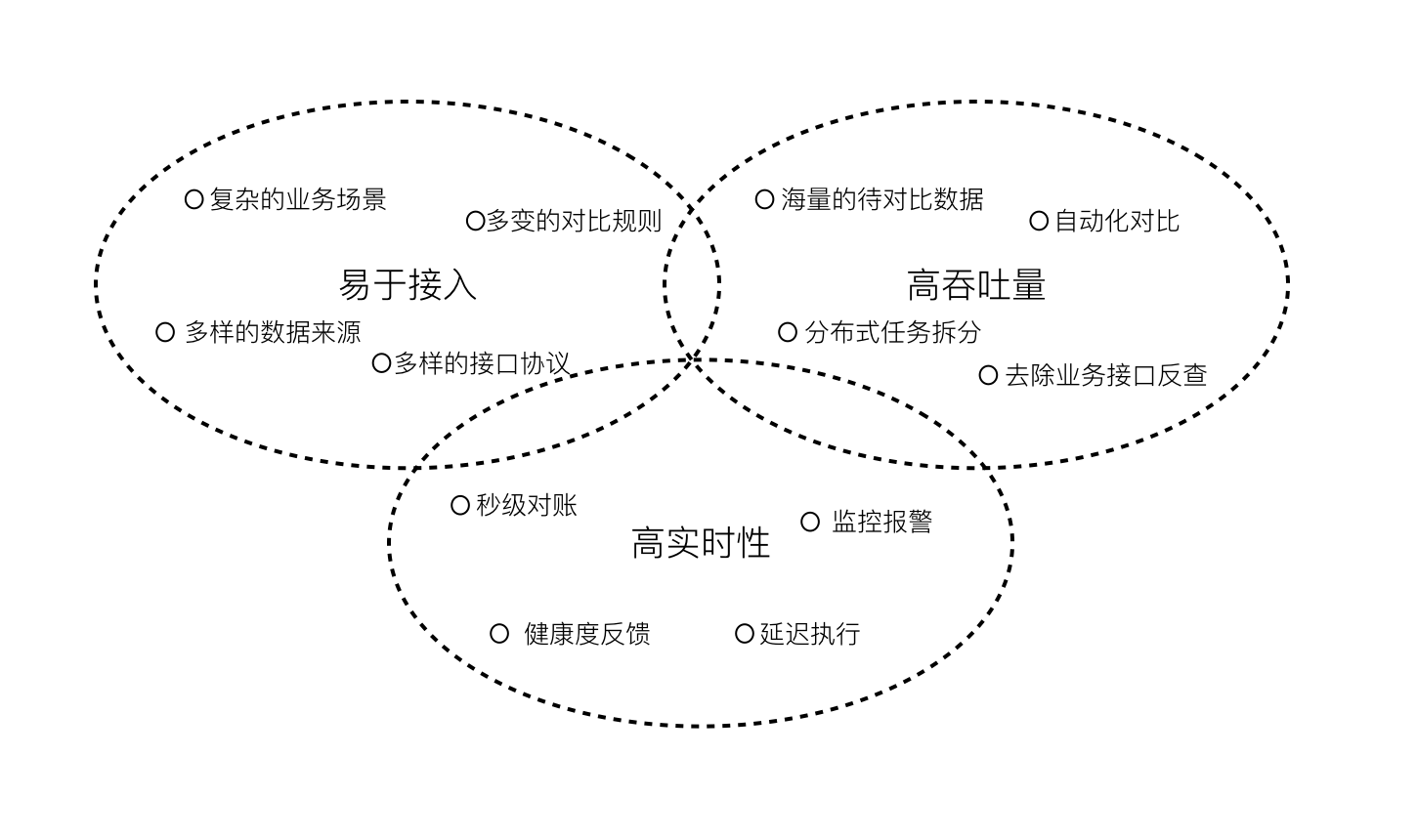 我们对于一个业务对账平台的核心诉求,主要包括要方便业务系统快速接入,要能处理业务方海量的数据,并保证一定的实时性。这会深刻影响业务对账平台的系统设计。
我们对于一个业务对账平台的核心诉求,主要包括要方便业务系统快速接入,要能处理业务方海量的数据,并保证一定的实时性。这会深刻影响业务对账平台的系统设计。
四、架构
从局部到整体,本文先从解决上面三个问题的角度,来看有赞业务对账平台的局部设计,再来看整体系统结构。
4.1 易于接入
我们认为所有的对账流程,都可以分解为“数据加载”、“转换解析”、“对比”、“结果处理”这 4 步。为了适应多样化的业务场景,其中的每一步都需要做到可编排,放置各种差异化的执行组件。在每一个流程节点,需要通过规则可以自由选择嵌入哪个组件。其次,需要把数据从原始格式,转换到对账的标准格式(基于标准格式,就能做标准的通用对比器)。总结起来,我们认为对账引擎需要具备以下的能力:
- 流程编排能力
- 规则能力
- 插件化接入能力
目前业务对账平台的对账引擎结构如下:
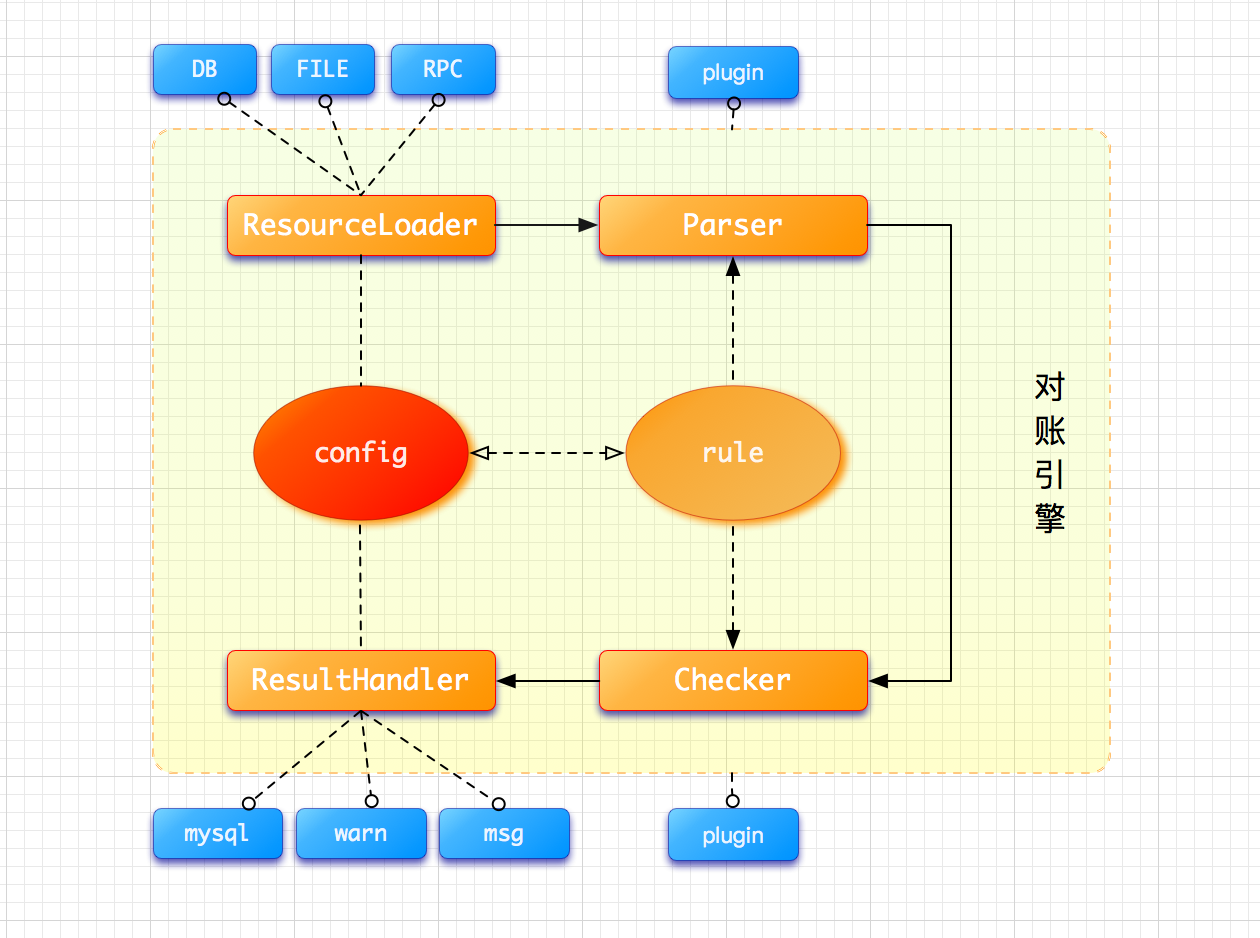 其中的 ResourceLoader 、 Parser 、 Checker 、 ResultHandler 均为标准接口,所有实现了对应接口的 spring bean ,都能被编排到对账流程之中,包括业务方自己实现的 plugin。这样就实现了插件化和可编排。每个流程节点的功能如下:
其中的 ResourceLoader 、 Parser 、 Checker 、 ResultHandler 均为标准接口,所有实现了对应接口的 spring bean ,都能被编排到对账流程之中,包括业务方自己实现的 plugin。这样就实现了插件化和可编排。每个流程节点的功能如下:
- ResourceLoader :基于各种数据源(DB、FILE、RPC、REST等)提供加载器工厂,加载各个数据源的原始数据。加载的方式支持驱动加载、并行加载、多方加载等方式。业务方也可以自己实现加载器,利用流程编排能力嵌入到对账流程中。
- Parser :对已加载的原始数据进行建模,转换为对账标准模型。利用规则引擎,提供脚本化(Groovy)的转换方式。
- Checker :按照配置对指定字段、按指定规则进行比较,并产生对账结果。支持 findFirst(找出第一个不一致)、full(找出所有不一致)等对比策略。
- ResultHandler :使用指定的handler对结果进行处理,常见的处理器包括持久化、发送报警邮件、甚至直接修复数据等等。
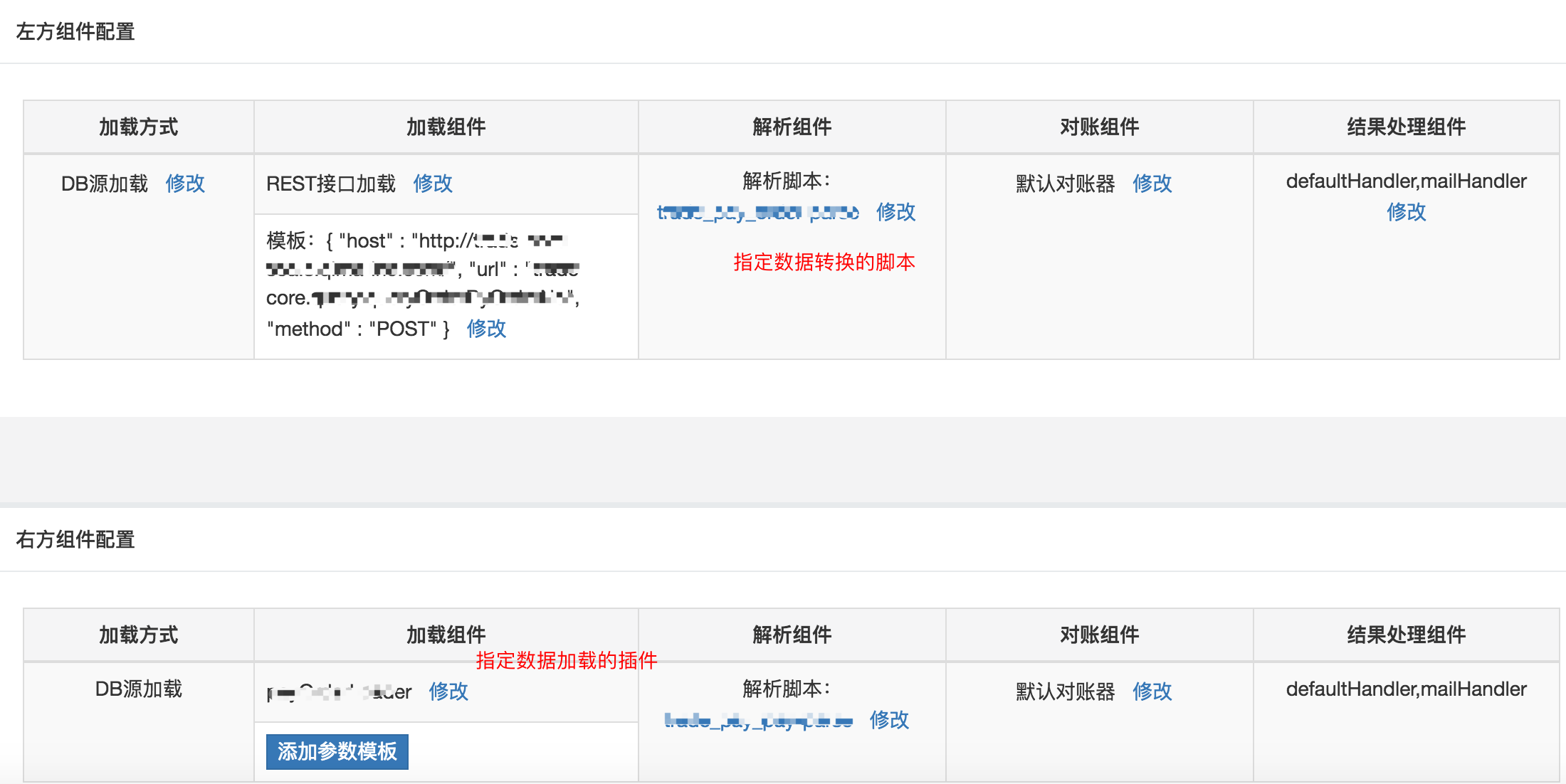
通过统一的 facade,将整个对账流程进行串联。在执行不同节点时,根据配置选择不同的默认组件或者插件来执行。可以在管理后台,对每个流程节点进行编排:
4.2 高吞吐量
一些离线定时对账场景,单次对账的数据量可能达到百万级,甚至千万级。这对对账平台的吞吐量造成了挑战。我们面对海量数据问题的通常解决思路,就是“拆”。分布式任务拆分+单机内任务拆分,将数据块变小。同时,也可以利用一些大数据的工具来帮我们减轻负担。
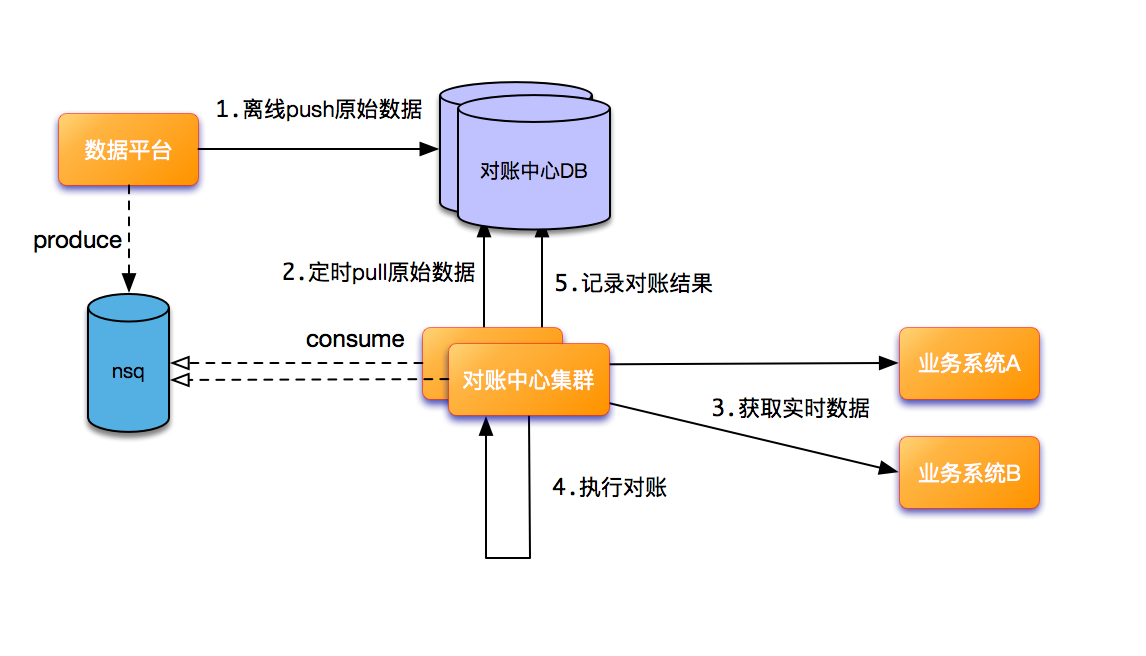 目前的对账有 2 种模式:一种常规模式,是通过数据平台(包含了所有要进行对账的原始主键数据,如订单号)将数据 push 到对账中心的 DB ,然后订单中心集群通过分片策略,并按分页分批加载,加载数据进行对比。另一种,则是当数据量超过千万时,利用数据平台的 spark 引擎从 hive 表中获取数据,然后投递到 nsq(自研消息队列)。nsq 会选择其中一个 consumer 进行投递(不会投递到多个consumer)。这样千万级的数据会变成消息被分散的对账服务器执行。
目前的对账有 2 种模式:一种常规模式,是通过数据平台(包含了所有要进行对账的原始主键数据,如订单号)将数据 push 到对账中心的 DB ,然后订单中心集群通过分片策略,并按分页分批加载,加载数据进行对比。另一种,则是当数据量超过千万时,利用数据平台的 spark 引擎从 hive 表中获取数据,然后投递到 nsq(自研消息队列)。nsq 会选择其中一个 consumer 进行投递(不会投递到多个consumer)。这样千万级的数据会变成消息被分散的对账服务器执行。
对账任务一般会选择在业务量较小的凌晨进行,是因为在对账过程中会需要通过反查业务接口,来获取实时数据。而更好的情况是,对账时能去除对业务接口的反查。因此,会需要对业务数据进行准实时同步,提前进入对账中心的 DB 集群。
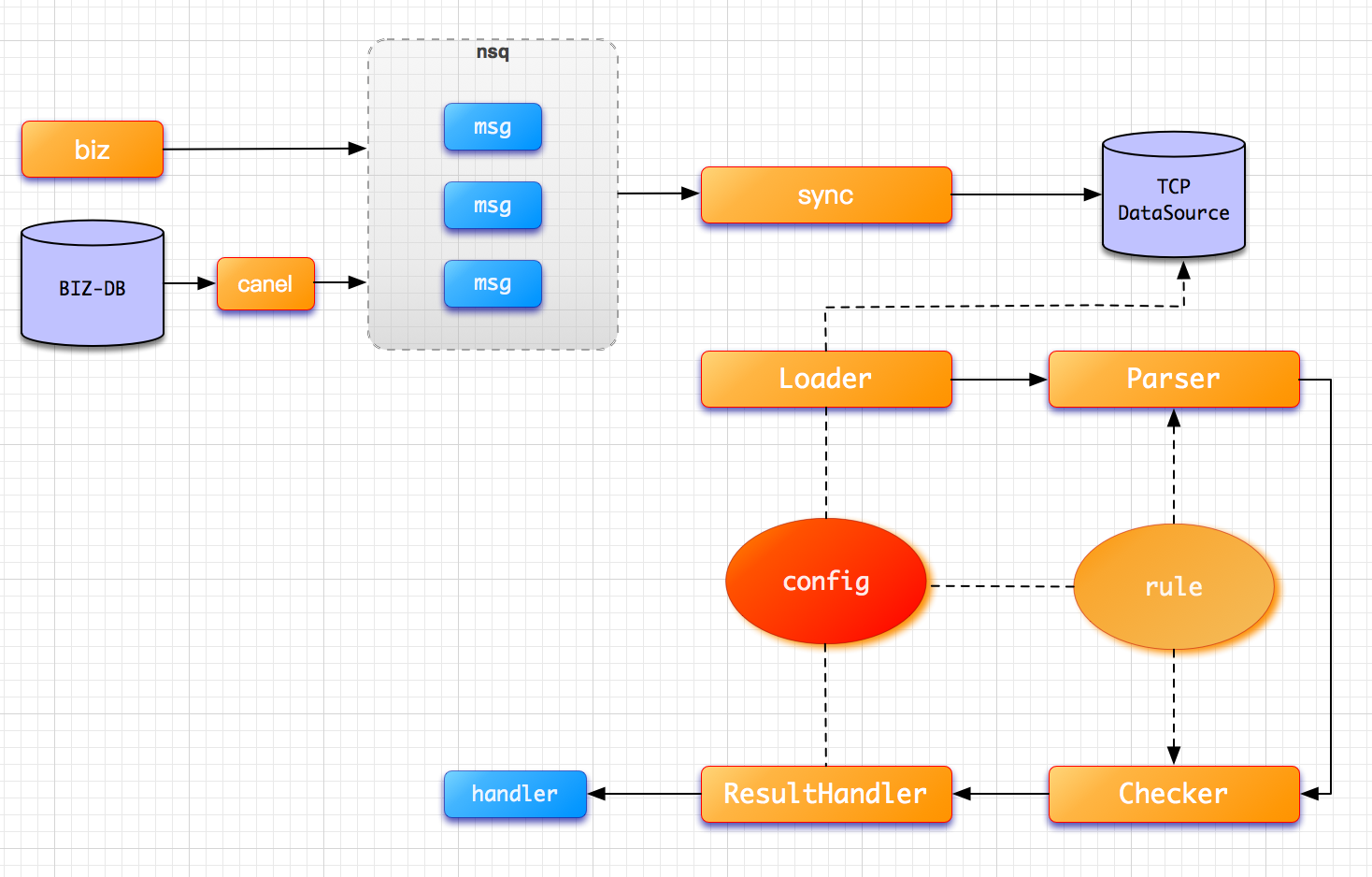
主要思路是基于业务 DB 的 binlog 日志或者业务系统自身的消息,进行数据同步。后续流程则类似。
4.3 高实时性
一些特定的业务场景,比如买家已经付款成功了,但是由于银行第三方的支付状态回调延迟,导致订单状态还是待付款。这种情况,买家会比较焦急,可能产生投诉。面对这样一些场景,就需要进行实时对账,也可以叫做秒级对账。
秒级对账往往基于业务消息进行触发,需要在事件触发后的短时间内执行完对账任务。且事件消息的触发,往往具有高并发的特点,因此需要相应的架构来进行支持。
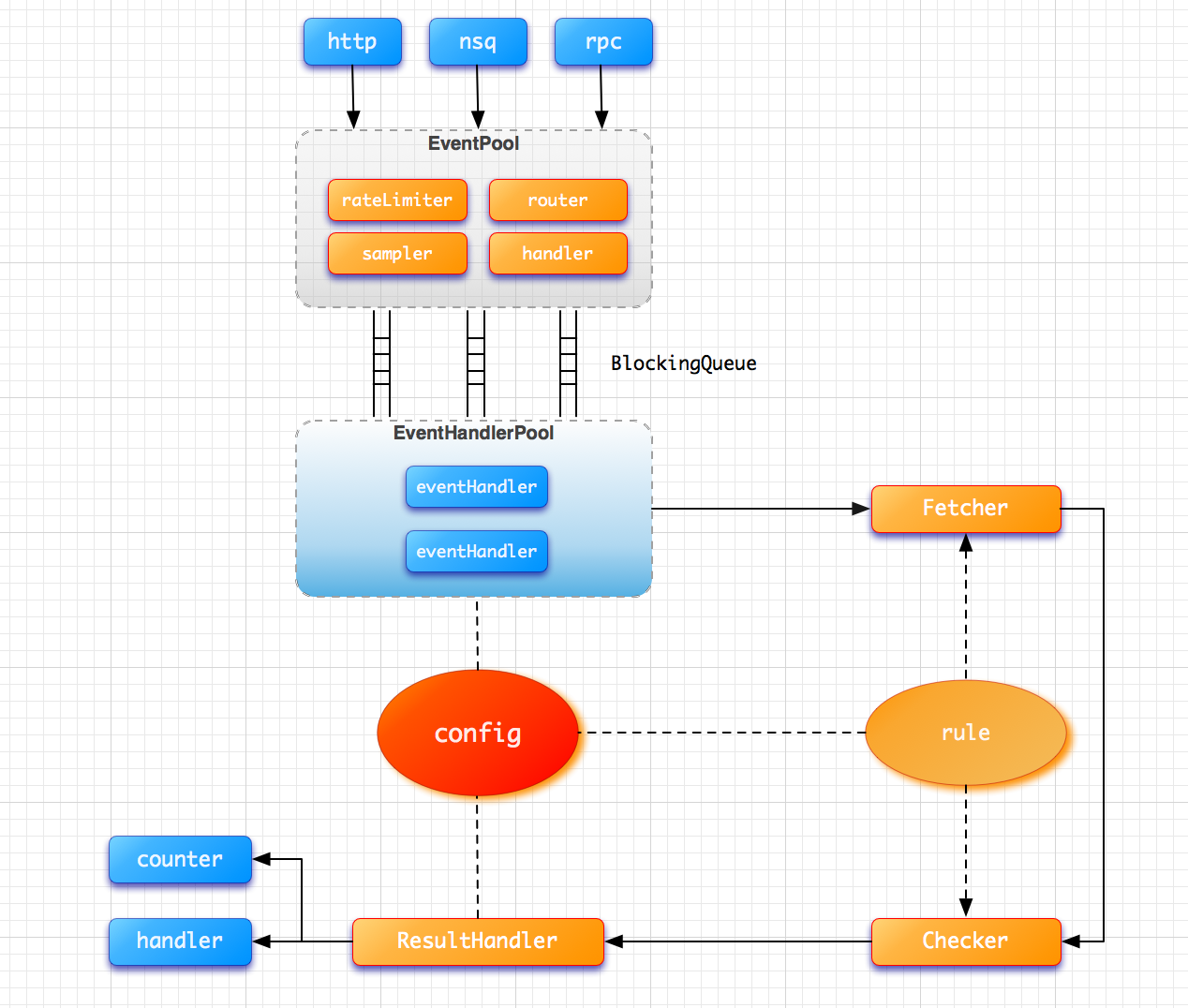 设计中主要加入了 EventPool 来缓冲处理高并发的事件消息,并加入限流、取样、路由、处理的 pipeline。同时在进入事件处理线程池之前,需要进入阻塞队列,避免大量的请求直接耗尽线程资源,同时实现事件处理的异步化。处理线程批量定时从阻塞队列获取任务来执行。同时,利用延迟阻塞队列,还可以实现延迟对账的特性。(我们认为出现不一致的情况时,如果立即去进行对比,往往还是不一致的。所以就需要根据情况,在事件发生后的一段时间内,再触发对比)
设计中主要加入了 EventPool 来缓冲处理高并发的事件消息,并加入限流、取样、路由、处理的 pipeline。同时在进入事件处理线程池之前,需要进入阻塞队列,避免大量的请求直接耗尽线程资源,同时实现事件处理的异步化。处理线程批量定时从阻塞队列获取任务来执行。同时,利用延迟阻塞队列,还可以实现延迟对账的特性。(我们认为出现不一致的情况时,如果立即去进行对比,往往还是不一致的。所以就需要根据情况,在事件发生后的一段时间内,再触发对比)
4.4 整体设计
上面介绍了业务对账平台的各个局部设计,下面来看下整体结构。
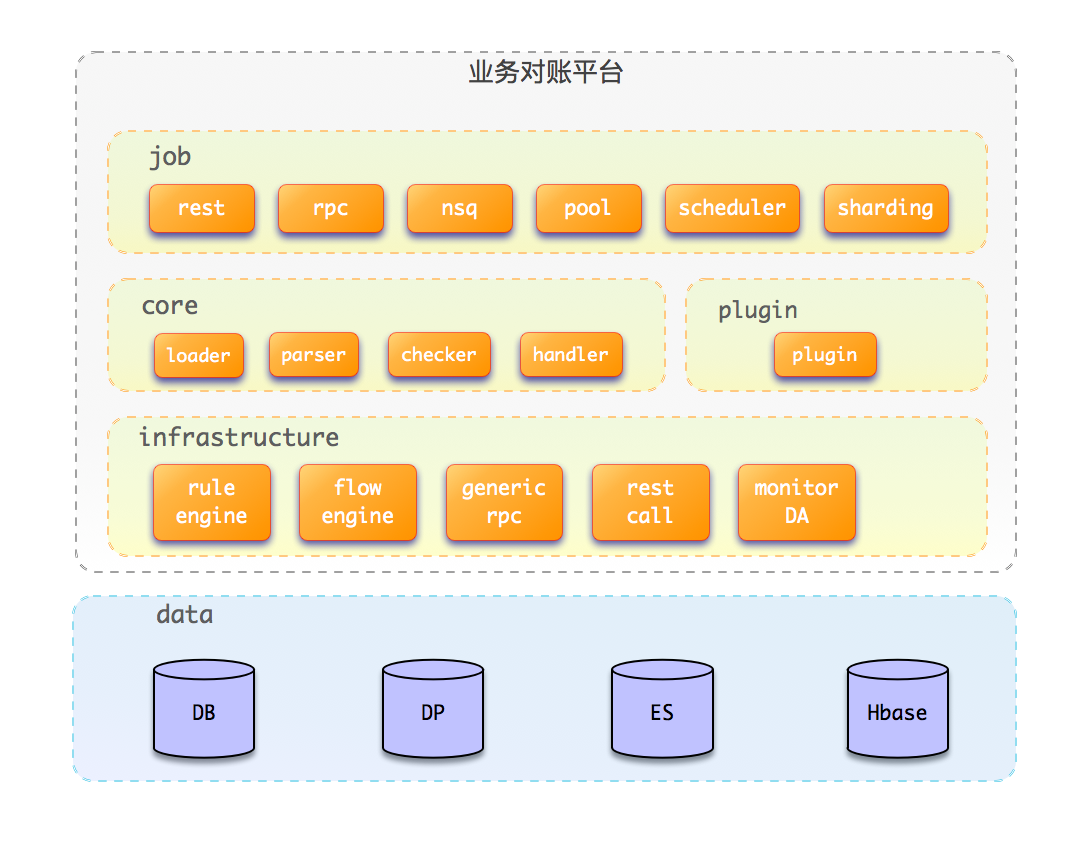 整体上主要采用调度层+对账引擎(core+plugin)+基础设施的分层架构。调度层主要负责任务触发、任务拆分、调度;对账引擎则负责执行可编排的对账流程;基础设置层则提供规则引擎、流程引擎、泛化调用、监控等基础能力。
整体上主要采用调度层+对账引擎(core+plugin)+基础设施的分层架构。调度层主要负责任务触发、任务拆分、调度;对账引擎则负责执行可编排的对账流程;基础设置层则提供规则引擎、流程引擎、泛化调用、监控等基础能力。
五、健康度
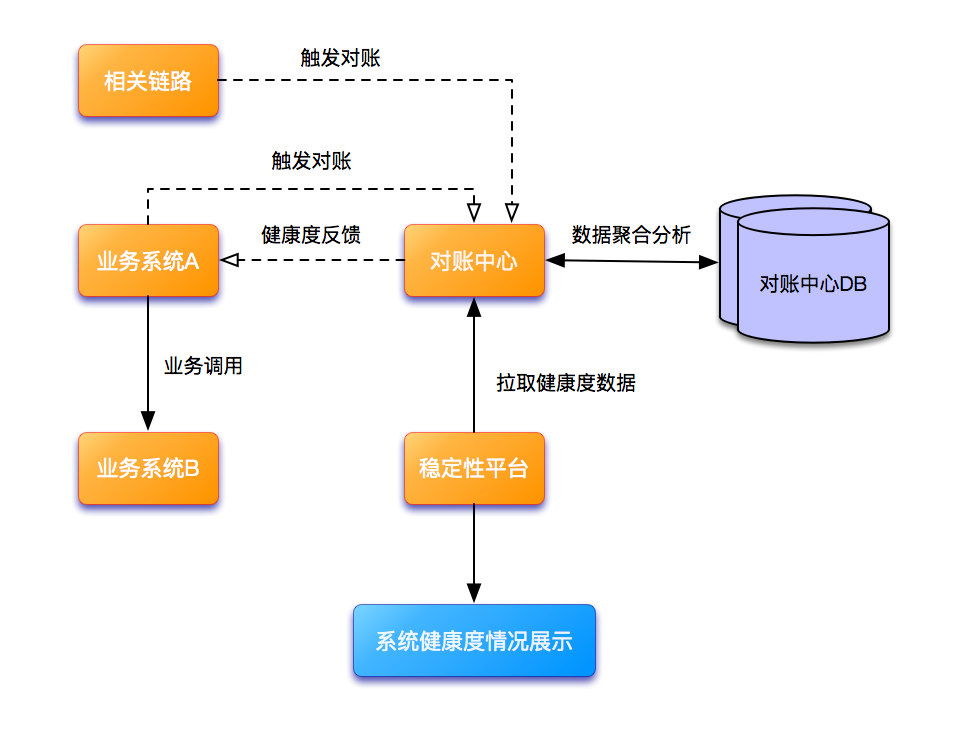
对账中心可以拿到业务系统及其所在整个链路的数据一致性信息。基于此,对账平台具备了给予业务系统和链路健康度反馈的能力。
六、共建
前面有提到,对账的流程被拆分为四个固定的流程节点,且有四个对应的标准接口。通过流程引擎和规则引擎的能力,可以根据 spring bean name,来将系统默认组件或者插件编排到对账流程之中。基于这种开放性的设计,业务对账平台支持与业务团队进行共建。
首先,对账平台提供标准接口的 API jar 包,业务方通过引入 jar,实现相关接口,并将 impl 打包。这样,对账平台通过 spi 的方式,可以引入业务方的插件包,并加载到对账中心的 JVM 中执行。
七、未来
业务对账平台,是面向业务场景建立,但同时属于数据密集型应用。平台上线以来,已经接入公司各团队数十个对账任务,每天处理千万级的数据。展望未来,业务对账平台的使命会从主要进行离线数据分析处理,演进到利用应用系统的健康度数据帮助系统进行实时调整的方向。在分布式环境下,没有人能回避数据一致性问题,我们对此充满着敬畏。欢迎联系 zhangchaoyue@youzan.com,交流心得。
