埋点质量保障
常见问题
我们收集日志,目的还是为了分析用户行为,挖掘潜在价值,最终能优化产品体验。因此,“高质量”是最基本要求,这是保证分析效果准确性的基石。那么,常见的质量问题有哪些呢?
- 事件重复&丢失。重复是由于SDK自身或者前端开发疏忽的问题,导致相同事件重复发送;丢失可能是设备、网络原因,或者是开发者漏埋导致。
- 事件参数错误。常见的情况有:”必传而未传“、”非空而为空“、”值类型不对“、”值内容不对”等。
- 前端常见错误。比如值为“undefined”、“null”,通常是前端代码bug导致的值错误。
- 事件断流。这种case经常发生,前端在做改造升级的时候,可能导致事件上报不规范,或者误下线。
保障机制
针对埋点质量问题,我们尝试以下的保障机制,去解决。从业务开发的过程出发,在不同阶段提供服务支持,形成一个解决问题的闭环,保障日志处于高质量状态。
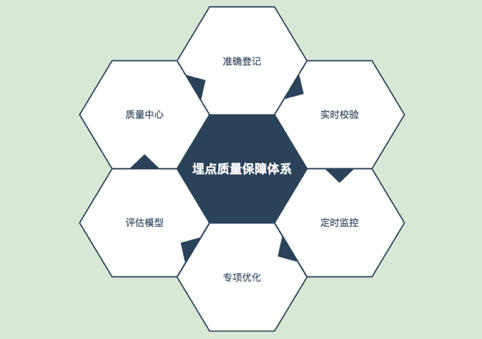
准确登记
业务需要根据“埋点规范”,规划好页面、组件和事件,并且在埋点平台上准确地登记。登记的信息越全,内容越细,越有利于自动化判定日志的准确性。目前我们登记的要素有:
- 页面/组件类型,登记该元素的业务标识,以及是否有业务ID。日志上报时,会有对应的字段记录该信息。
- 事件信息,事件的名称/标识/描述,所属页面/组件,以及所处状态等信息。
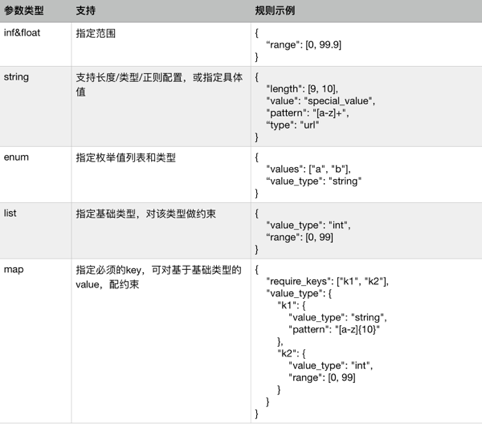
- 事件参数,属于该事件的一系列业务参数,比如一个点击事件的参数可能是被点击的商品的ID。对于参数的登记,我们支持标识/类型/是否必传/参数结构的设置。其中类型支持int/string/float/list/map,用于申明值内容结构;参数结构支持对复杂的数据类型,进一步定义其细节。
实时校验
做好了埋点的登记工作,开发就可以按照埋点方案做相应的开发了。如何快速验证上报日志的准确性,以及如何及时发现线上问题,是我们面临的直接问题。因此,我们做了实时校验。除了实时外,校验还需要考虑更新及时性/完备性/扩展性,避免规范或校验点的变更,带来频繁的修改代码或重启任务。另外,对于校验结果,还需要要做到可解释/可沉淀/可分析。
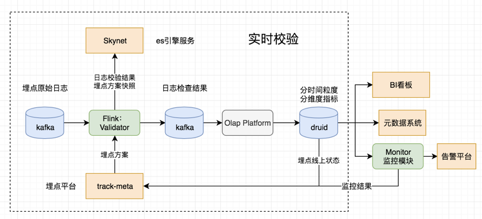 对于实时性,我们采用Flink开发校验模块,实现秒级日志校验;校验规则更新的及时性上,每分钟从埋点平台同步;可沉淀,校验结果除了推送给测试工具外,还会落到druid,用于后续分析。这些点的思路比较直接,就不赘述了。下面着重介绍下其他考虑点:
对于实时性,我们采用Flink开发校验模块,实现秒级日志校验;校验规则更新的及时性上,每分钟从埋点平台同步;可沉淀,校验结果除了推送给测试工具外,还会落到druid,用于后续分析。这些点的思路比较直接,就不赘述了。下面着重介绍下其他考虑点:
完备性/扩展性
完备性比较好理解,校验需要支持的,除了底层的埋点规范外,还有分业务的页面/组件的合法性、事件关联页面/组件的情况、事件参数格式内容等;扩展性的考虑点在于,校验点会持续不断完善,如何“以不变应万变”。这点上,主要思路有两个:
1. 通过分析校验规则,抽象语义,我们设定以下语法(示例):
{
"compare":"length",
"condition":[
"sdk_type",
"in",
[
"iOS",
"Android",
"js"
]
],
"assert":"true",
"assert_fail":"ERROR",
"value":36,
"key":"uuid",
"fail_msg":"did/uuid invalid",
"require":1
}
本示例的含义:在sdk_type为iOS、Android或js的情况下,检查uuid参数,保证其是必传的字符串,且长度是36,如果不是则是ERROR级错误,错误信息为“did/uuid invalid”。具体字段说明:
- key:参数名
- value_type:参数值类型,默认为string,可指定int
- compare:参数值检查方式,支持:
- in:在一系列值内
- length:对于字符串类型,指定长度
- regex:对字符串类型,指定正则
- value:参数值约束,对于compare=in是一个list;对于compare=length是一个数值;对于compare=regex是一个正则字符串
- assert:检查结果需符合的值,true或false
- assertfail:检查失败给出的异常等级,WARNING、ERROR、TESTWARNING
- fail_msg:检查失败给出的错误信息
- condition:检查前置条件,符合该条件才进行检查。
- require:该参数是否必须,非必需情况下,若为空则不检查
2. 开关&配置化
不同时期,校验关注的点可能是不一样的,不同阶段,校验的逻辑也会有所区别。比如初期在问题重灾区,我们对未登记的事件,没有直接发送异常告警,但后期会;在新校验点试验阶段,其校验登记会设定为WARNING或TEST_WARNING,而上线稳定后,可能会改成ERROR。因此,在实现中,就特别注意使用开关或配置,达到功能点的可定制。
可解释/可分析
校验发现了问题,是为了解决问题。因此对结果,要求是可解释的:在哪个层次,哪个参数发生什么样的错误,原因是啥;可分析的:分析不同级别、不同维度组合的异常分布、走势,便于集中定位和解决问题。
实现上,我们会对校验的层次、范围、结果等级作区分,对于每条日志可能产出多条校验结果(1+n)。 其中的n,是指不同层次和字段,可能会有ERROR/WARNING/TEST_WARNING状态;1指的是整体上,会有个最严重的状态汇总。
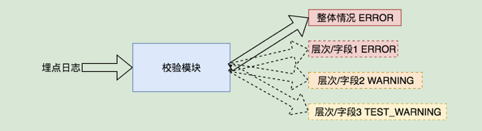 简化后的校验结果格式,是这样的(包含多个关键维度,维度所处层级,问题字段、级别等):
简化后的校验结果格式,是这样的(包含多个关键维度,维度所处层级,问题字段、级别等):
{
"log_id":"571531737e29586094318d3bf64e9407",
"timestamp":1556174577000,
"event_type":"click",
"sdk_version":"0.7.7",
"sdk_type":"js",
"display_url":"url",
"scope":"OVERALL",
"field1":"",
"field2":"",
"status":"SUCCESS",
"value":""
}
有了这样的校验结果,可以做很多事:埋点错误重灾区、错误趋势、原因分布等,实现可解释和可分析。
定时监控
除了上线前的把关,事后的监控也是很有必要的。从质量角度,关心规范的实际约束情况;从流量角度,特别关注事件断流和异常波动情况;另外,业务上有很多约束,也需要去做监控。
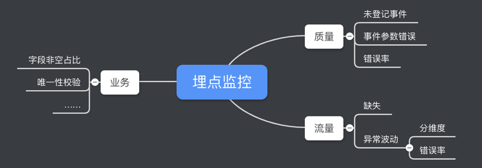 基于实时校验结果,我们做到分钟级的质量和流量监控,在业务层面,会有小时级的个性化监控。
基于实时校验结果,我们做到分钟级的质量和流量监控,在业务层面,会有小时级的个性化监控。
监控的“低误报”是一个很重要的考虑点,泛滥的监控等于没监控,在这点上,我们对监控做了一系列优化,如设定流量门槛、结合历史流量饱和度判定断流等。
专项优化
发现问题是手段,解决问题才是目的。
对于质量问题,会反馈到业务方去整改;除了业务上,还有许多基础SDK或开发上的通病问题,需要单独去做分析,成立专项,集中整改。比如SDK的重复率和丢失率问题,需要具体分析问题,推动底层优化。
这类工作主要是:问题分析>追根溯源>确定解法>持续跟踪。这里边涉及到许多特定场景的细节问题,就不展开讲了。
评估模型
如何去评估质量状态,是一个值得深思的问题。如果不能正确评价,就会摸不清重点,不知道如何优化,以及状态是在改善还是恶化。
我们的衡量维度目前是这样的:
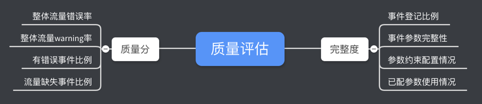 需要注意的是,各维度的权重,不应该是一成不变的,而要随着问题的重点而调整;甚至考虑的问题,也要不断去做优化,加入新的考量点。
需要注意的是,各维度的权重,不应该是一成不变的,而要随着问题的重点而调整;甚至考虑的问题,也要不断去做优化,加入新的考量点。
有了一套这样的评估模型,质量的状态就可以以“分数”的形式直观地呈现。对于问题的关键点,也可以有重点有方向地去解决。
质量中心
日常的质量问题,需要统一的呈现和管理,便于业务方有整体的感知,集中解决。
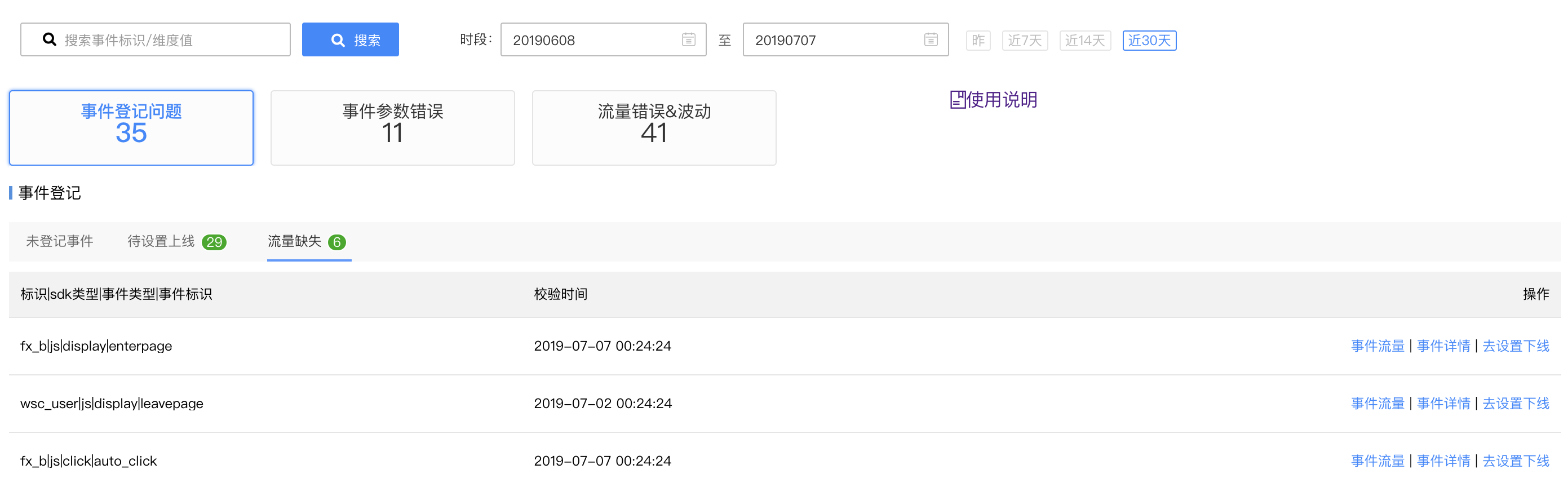 此外,对于汇总信息,也会以日报/周报的形式提醒到。
此外,对于汇总信息,也会以日报/周报的形式提醒到。
现状&规划
在以上介绍的一整套体系化的质量保障工作下,有赞的埋点质量有了大幅度提升。从状态未知到数字化的衡量;从缺少管理到集中化的呈现,并能提供优化辅助功能;从“不及格”的低质量到绝大部分问题被解决,质量问题已经不是业务分析的绊脚石。
我们的质量保障工作已经取得不错的成果,并形成良性的循环。但是还有许多可以优化的点:
- 支持更丰富的校验功能,将复杂的校验配置可视化
- 结合流量预测做监控告警,优化误报率
- 评估模型优化,结合现状,调整维度和权重
- 更完善的质量中心,集成快捷的优化操作
- 明确奖惩机制,推动业务方主动关心和优化质量问题,让前文提到的闭环,顺畅运行
通过这些方向的努力,相信有赞的埋点质量会持续保持高质量状态,更有力地为业务分析保驾护航。
