作为一名IT工程师,网络通信编程相信都会接触到,比如Web开发的HTTP库,Java中的Netty,或者C/C++中的Libevent,Libev等第三方通信库,甚至是直接使用Socket API,但是很多程序员都仅限于使用,对于使用的方式是否合理并没有特别深的理解,比如有一股脑的使用线程池解决问题的(虽然大部分情况采用多线程方案不会有什么问题,但是编程复杂度比起单线程提升了很多,线程开的太多也会导致切换过于频繁,性能未必有太大提升),也有始终用一条线程处理所有业务的,然后上线之后经常出现各种服务响应慢等问题。
在介绍TCP的网络通信编程时,不得不提到同步,异步,阻塞,非阻塞这几个概念,C++系和Java系沟通网络IO相关时,经常把这几种混在一起描述,比如同步阻塞,同步非阻塞,异步非阻塞等等,实际上,Linux AIO相关的API很少有使用在网络编程上,用同步异步描述网络IO并不准确,对于我们常用的Socket API,比如:Connect、Send、 Recv、Close等,只有阻塞非阻塞之分,没有同步异步之分,而各种应用提供的API接口可以分同步异步,比如Redis,MySQL官方提供的库大都是同步接口,Aerospike则既提供了同步接口,也提供了异步接口。
下面我们列一下在阻塞与非阻塞下,这些API都是如何表现的
看到了上面阻塞API执行的表现,那么我们假设一些异常情况
Connect: 在网络情况差的情况下进行Connect操作
Send:Server端因为各种原因不Recv数据,导致Client端发送缓冲区满,Send无法写数据入缓冲区
按照上面的情景很容易想到,函数都会Blocking住,此时这条线程就被OS挂起,让出CPU资源,并且该线程无法处理其它业务,如果此时正处于请求高峰期,结果可想而知。
那么如何解决这个问题呢,可能很多人首先想到的是多线程,但是多线程也会带来一个问题,这个线程池创建多少合适,太少不够用,太多资源占用多,而且线程切换频繁带来的损耗也不小。
正确答案是使用Socket的非阻塞模式,现在的通信框架基本都采用这种模式,比如一些成熟的第三方库,Libevent, Libev等。
当使用非阻塞模式,再结合多路复用Epoll,一个解决C10k问题的高并发网络框架基本就形成了。
接下来就介绍几种基于多路复用的非阻塞服务端模型
常见的服务端模型
1.单进程单线程
比如事件驱动通信框架Libevent,Libev,应用有知名的Redis,Memcache,比较适合没有太多耗时任务的情况。
简单高效的代名词,对于网络IO来说,就是哪个Socket Fd有读/写事件触发了,就执行它的逻辑,缺点是当一个业务逻辑涉及到很多RPC调用时,业务代码会分散在各处,可读性比较差,后面会与常见的非事件驱动Web框架做个对比。
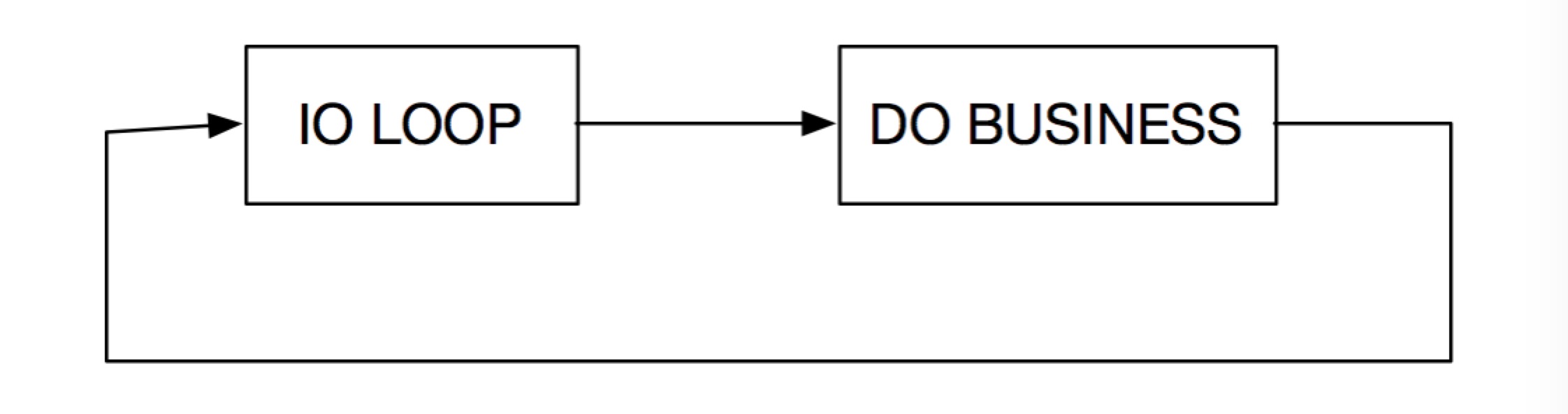
2.单进程多线程
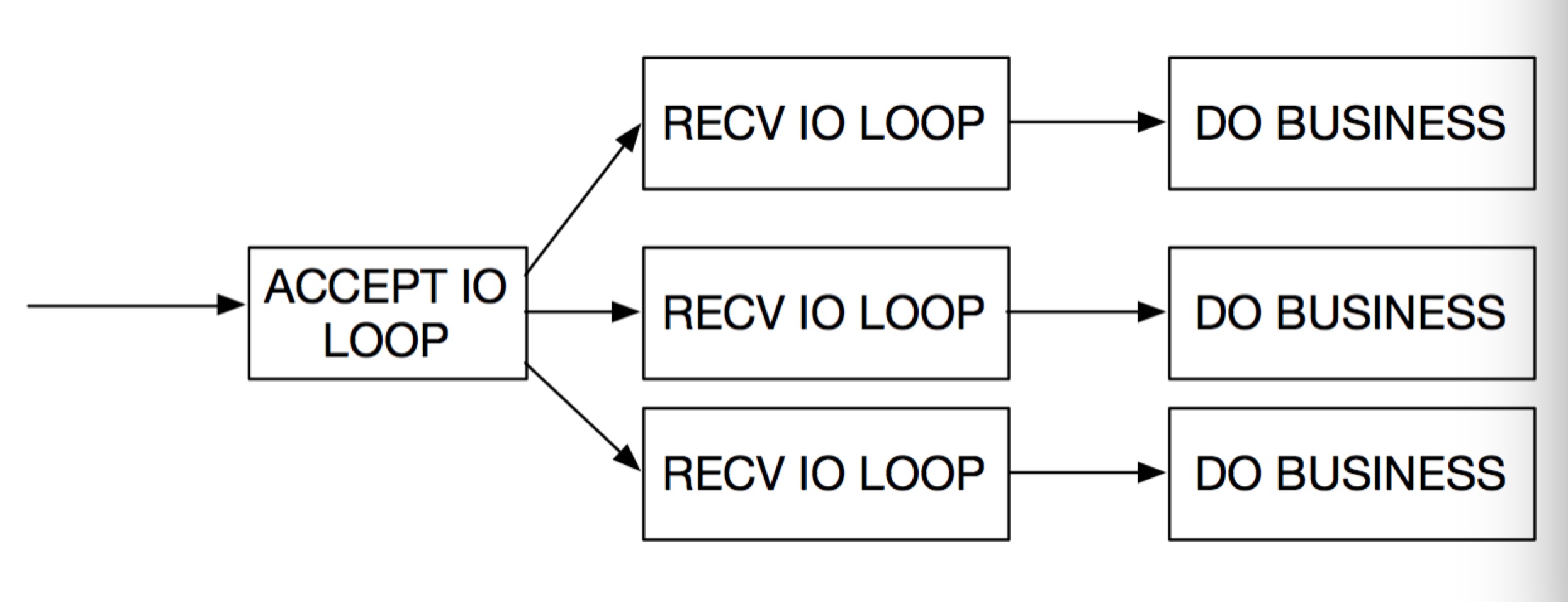
适合有比较耗时的业务的情况,比如流媒体,文件传输服务器,数据库代理等,其中又可以划分出如下两种比较典型的情况。
图一
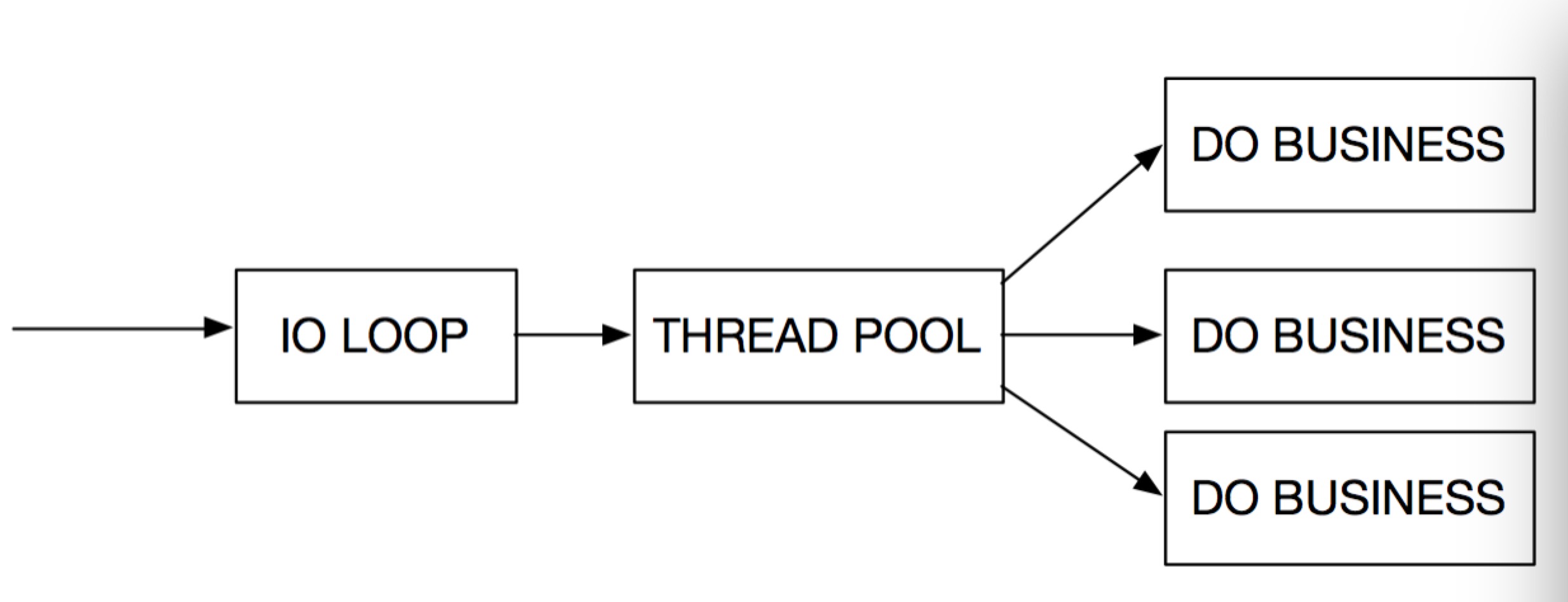
图二
对于图一,是比较常见的情况,比如DB Proxy使用线程池的方式建立多个连接以提供并行处理的能力。
对于图二,Accept IO Loop 只负责Accpet Client端的Fd, 然后将Fd传递给 Recv IO Loop,这样有一个好处,每个Client的请求都只会在一个Recv IO Loop中处理,从而保证了单个Client请求的有序性,而不像图一中需要其它手段保证有序。
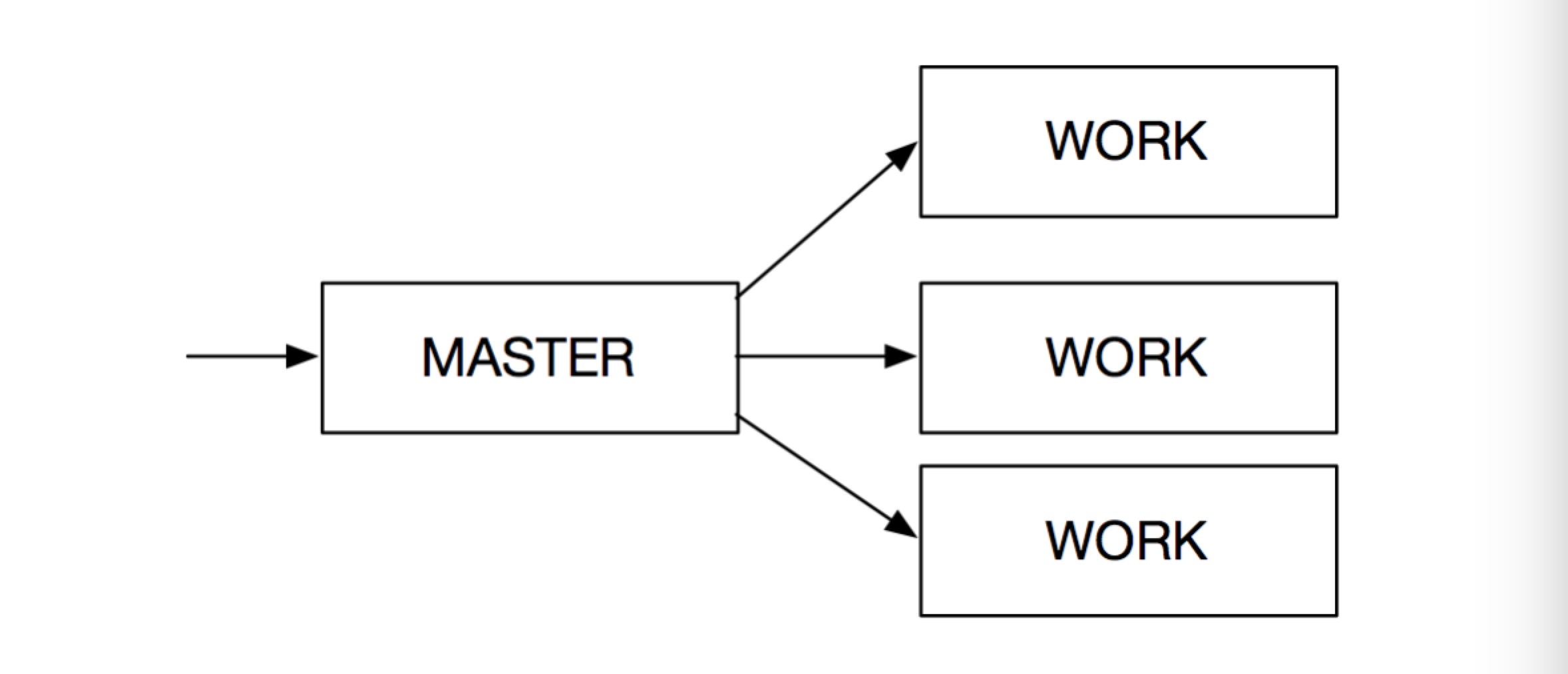
3.多进程
这种模式和单进程多线程的有点类似,而且如果Work是单线程的话,就可以不用考虑多线程带来的锁问题。
Master进程可以负责Accpet Client的连接,同时Recv数据并通过IPC的方式将数据包交予Work进程处理。
另一种,Master只负责Accept Client端的链接,然后将Fd传递给Work,让Work进行数据的收发与逻辑处理。
常见的Client模型
1.阻塞的Send,Recv模式
使用Send,Recv编写简单,适合于同步接口的封装,比如Aerospike,HTTP,的同步接口都可以使用这种方式,问题是不适合做成异步接口,在Recv的时候该线程不能处理其它业务
2.阻塞/非阻塞的多路复用模式
既可封装成同步接口,也可以封装成异步CallBack接口,扩展性更强,比如Aerospike的异步CallBack接口,优势是可以进行多个请求发送,有数据可Recv时才处理
Client库的并行调用
编写一个应用时,我们经常会遇到同时发送多个Req至服务端的场景,比如MySQL,HTTP,Redis或者自定义的协议,经常使用的一个方式是连接池,不同的Req分别用一个连接进行处理,这样做的原因是协议的特性决定的,因为使用一个连接,对于Rsp我们无法回溯哪一条Req,所以只能使用连接池方式,而我们自己设计协议时,一般都会在协议头都会增加一个唯一序列号,这样Rsp返回就可以通过该序列号找到对应的Req,了解了这一点在做Client端的并发调用时就可以更清楚的选择以下哪一种模式了。
1.线程池:
比较常见的就是使用MySQL,Redis等开源产品的同步库,线程池使用比较方便,但是问题也比较明显,依赖线程的数量,设置太少,并发处理能力太弱,设置太多,线程切换频繁。
2.连接池:
通过创建多个连接,并结合多路复用的方式进行操作。比如自行解析MySQL,Redis,HTTP等协议,直接操作Socket Fd,Aerospike的异步连接池就是使用这种方式,好处是可以避免频繁的线程切换,问题就是如果官方的库没有提供这种功能的话,就只能自己去解析协议,没有线程池使用起来方便快捷。
3.连接复用:
一般我们自定义的二进制协议,协议设计时都会带有一个唯一的序列号,Rsp通过这个序列号来找到对应哪个Req,这样就可以复用一条链接进行多次发送,而无需使用上面提到的线程池和连接池方式了。
事件驱动型框架
在上面的服务器模型介绍中提到过事件驱动,简单介绍了事件驱动的原理,就是利用多路复用Select/Epoll监听一堆Socket Fd,当哪个Socket Fd有读/写事件后,就处理它的事件。

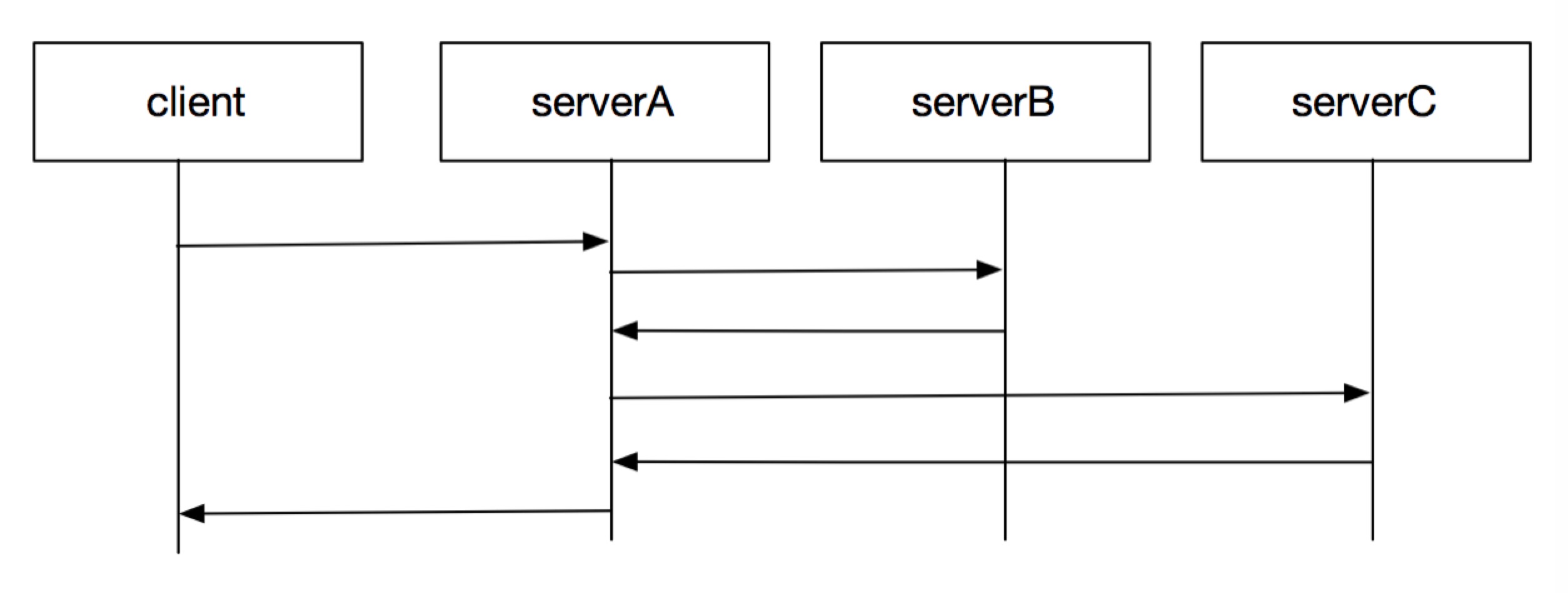
如上图,是一个很常见的请求流程,对于很多Web框架的用法来说,ServerA对于Client的请求代码都是如下写法:
def DoReqClient(req):
res1 = Call_RPC_B()
res2 = Call_RPC_C()
Send_Rsp_To_Client()
ServerA对ServerB与ServerC的RPC都是同步的,ServerC的RPC需要等到ServerB完成后在执行,假如一个请求ServerB处理很慢,则处理这个任务的线程/进程就必须等待,如果ServerA是PHP-FPM就相当于一个进程堵住,完全不能处理其他任务,假如开启了500个进程,则表示PHP-FPM最多只能同时有500个这样的请求,之后该机就完全无法处理新的请求,直到任务完成释放一个进程。
但是我们可以看到对于这台机器来说,他的单机性能完全没有机会发挥,全部堵塞在了网络IO上,要解决并发量的问题,要么用机器堆(钱多),要么优化业务,看看如何提高后端业务的处理能力,还有一种就是采用事件驱动型框架,有网络IO事件了才处理,这样就不会有任何的网络IO阻塞,唯一的缺点是业务代码逻辑分散,比如上图的ServerA如果换成事件驱动的写法就会如下面的样子。
def DoReqClient(req):
...
Send_Req_To_ServerB()
def DoRspServerB(rspB):
...
Send_Req_To_ServerC()
def DoRspServerC(rspC):
...
Send_Rsp_To_Client()
然而坏消息是大部分Web框架并不支持这种事件驱动的模式,更多的都是使用第一种同步写法,简单快捷,便于快速开发出产品,因为初期的时候性能并不是第一要务,快速产出才是关键,毕竟通过堆机器有时候也可以提高网站的并发能力,而当你开始考虑以更少的机器支撑更大的并发时,基于事件驱动模型的框架是一个不错的选择。
想要优化事件驱动逻辑分散的写法可以用到现在比较流行的协程,用同步的代码实现异步的流程,现在很多语言都开始支持协程的语法,本文就不在具体展开了,有兴趣的同学可以去了解一下,比如PHP同学可以看看我们公司的Zan框架,Python同学可以了解一下tornado框架,或者直接学习一下Golang。
结语
通过以上的总结,我们可以知道服务器和客户端的网络通信模型并没有一个固定的模式,而是需要结合具体的协议,使用场景来判断,什么时候单进程单线程就能满足需求,什么时候必须使用多线程,连接池。只有采用了合适的模型,才能为一个高并发高性能应用打好坚实的基础。
