因为我们的生产环境没有专用的NAT设备,不得不使用Linux的NAT功能来解决生产内网访问公网的问题。
NAT的原理,大致如下图所示:
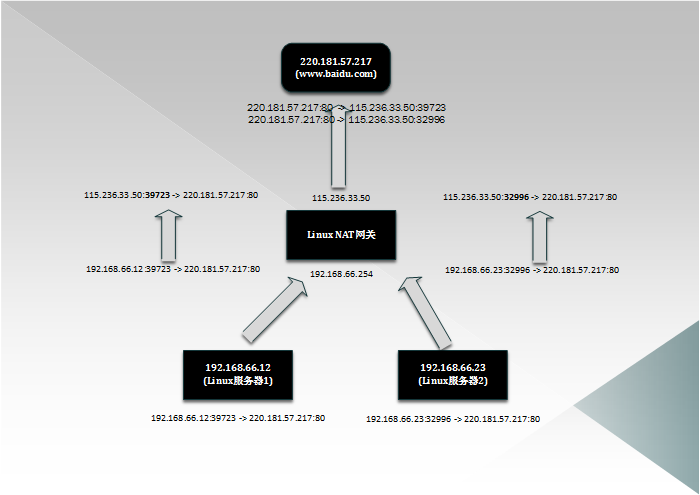 内网的机器,将网关配置成NAT网关的地址,当访问公网时,NAT会将访问公网的包的源地址(内网地址)转换为自己的公网地址,再将包发给公网的服务器。
内网的机器,将网关配置成NAT网关的地址,当访问公网时,NAT会将访问公网的包的源地址(内网地址)转换为自己的公网地址,再将包发给公网的服务器。
然而,服务器访问公网与桌面系统访问公网的场景,是完全不同的,服务器访问公网的行为,通常比桌面系统的行为更有“规律“(其实与操作系统也有关系,不同操作系统的TCP/IP协议栈行为是有差别的)。比如,服务器会在相对集中、统一的时间同时发起公网请求,并且还是相对集中地访问固定的地址。这对NAT设备来说,要求就比桌面系统的NAT要高。我们知道,计算机系统中大量地使用"哈希算法",而对哈希算法性能影响最明显的,就是“哈希因子分布不匀”。
在使用默认NAT的情况下,我们遇到若干问题,写下来希望对别人有帮助。(如有不正确的地方,欢迎指正。我们运维团队衷爱对系统底层实现有理解、有认识的同学,欢迎讨论)。
问题一:
在公网请求突发变大的情况下,NAT设备的CPU会被打满(CPU软中断使用率占大头),平时CPU使用率5%不到。
被打满的经典现象(出现过多次)是:
- CPU使用率达到或接近100%。
- 网卡带宽很小。比平时大,但绝没有达到极限。
- PPS比平时大,但是跟网卡的处理能力比,也是微不足道。
- /proc/net/nf_conntrack 条目达到9万多条。
我们分析了/proc/net/nf_contrack的条目,得到了两个重要的信息:
- 访问公网的目的地址很集中。
- 有大量的TIME_WAIT状态的连接。
因为我们没人理解内核的原理,只能靠经验来分析。
我们抛出了几个问题:
1. 一个只有一个公网地址的NAT网关,最多能支持多少个“访问公网的连接”?(我们知道,一个公网IP,连接同一个目标IP:PORT,理论上,能支持的主动连接也就65535个,因为在ipv4中,本地端口最多只有6335个。)
2. net.netfilter.nfconntrackbuckets 这个参数,默认有点小,连接数多了以后,势必造成“哈希冲突”增加,“哈希处理”性能下降。( 是这样吗?)
经过一轮分析,我们得出一调整结论为:
- 增加网关公网地址数量。
- 增加 net.netfilter.nfconntrackbuckets 值。
- 减小 net.netfilter.nfconntracktcptimeouttime_wait 值。
调整完之后,到目前为止,还没有再出现过CPU使用率100%的问题,至少是在之前就会故障的同等“连接数量”场景下,CPU依然很低,网关依然可用。
然而事情还没有完结……
问题二:
通过观察监控,我们发现有一个4台设备的集群,TCP的重传率不一致,查找原因,最终发现调用某个第三方的API时,4台机器的表现不一致,有2台能访问,2台不能访问。 我们确认了4台设备上的 net.vip4.tcptwrecyle = 0。作为Server端,是绝对不能打开这个开关的,会让在NAT后端的Client出现连接不上服务端。那么几乎可以肯定是对端开启了这个设置,导致我们位于NAT后端后设备连接不上第三方的服务。
于是我们不得不 sysctl -w net.ipv4.tcp_timestamps = 0,然后4台机器都能访问这个第三方API了。
结论:
- 对于提供监听服务(即以被动连接的形式提供业务)的系统来说,net.ipv4.tcptwrecyle 必须等于 0。否则,对NAT后的Client,将不能提供100%的可用服务。
- 假如你的连接要经过NAT,那么就不应该启用“net.ipv4.tctwreuse”。
- 要用好一个东西,一定要知道、理解它的工作原理。
- 观察(监控、可视化)、分析、思考是运维工作中“做好细节”的唯一的方式、方法。
- 查资料这种事,Google虽然很方便,但是“手册、官网”才是正经信息来源。
参考:
Linux-netfilter-conntrack机制初步分析
http://blog.sina.com.cn/s/blog_781b0c850100znjd.html (阿里技术专家)
http://blog.chinaunix.net/uid-20196318-id-3409788.htmlg
