在系列文章前面几篇中,介绍了NSQ改造的过程和几个基础特性,本文中我们继续介绍几个高级特性及其使用场景,这些都是结合有赞业务场景总结提炼出来的重要功能。
NSQ拓展消息格式的设计
有赞中间件在NSQ中引入了支持拓展内容的消息格式,通过支持拓展的消息格式。业务方能够在消息体外定义额外的数据,拓展了应用功能,支持更多的场景。
相比较于Kafka等消息中间件,NSQ的消息格式在内容和数量上较为简单。一条消息除了基本的元数据之外,其余内容为消息体。消息的元数据主要包括了消息在服务端产生时的时间戳,服务端对于该消息的下发次数,消息ID。Kafka消息格式(record batch,control record,record)中出现的部 分元数据例如压缩格式(snappy),nsq在客户端建连的过程中通过IDENTIFY确认,而部分元数据,如CRC,事务属性等,在NSQ中则没有对应实现。
消息格式的相对简单,使得nsq传输消息内容上有更高的效率,同时使得编写NSQ客户端时更为容易。而简单格式所带来的缺点就是NSQ消息除了消息体本身之外,无法携带更多的额外信息。在传输一些可以和业务流程解耦的数据时,依然需要修改已有消息格式,并且由于缺少重用性,每个需要传输拓展数据的业务方都需要重新改造自己的业务消息格式。
拓展内容的消息格式
为了使NSQ支持更多的场景,有赞中间件在原有NSQ消息格式的基础上进行了改进,设计并实现了一种支持拓展的消息格式。
[x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x][x]...[x][x][x][x]...
| (int64) || || (binary string ) || || || || (binary)
| 8-byte || || 16-byte || || || || N-byte
---------------------------------------------------------------------------------------------------------------------------------...
nanosecond timestamp ^^ message ID ^ ^ message body
(uint16) ,
2-byte ,
attempts ,
可以看到新消息格式在已有消息格式上增加了3个部分(绿色字体):
- 拓展内容的版本(version of extension content): 长度为1个字节,用于区分拓展内容的类别和格式。例如,0x01为json拓展;
- 拓展内容的长度(length of extension content): 长度为2个字节,表示拓展内容的字节长度;
- 拓展内容的二进制字符串:可变长度,为拓展内容的二进制字节数组;
通过在消息格式中引入以上附加信息,NSQ在消息传输过程中能够在不修改原有消息格式的前提下附带额外的信息,业务方或者应用框架能够通过拓展消息格式支持新的场景和新的功能。在此我们以有赞业务中使用的几个典型场景为例, 详细描述下扩展消息的使用。
拓展消息使用场景之链路压测
链路压测是生产环境中的典型场景。压测器在短时间内生产大量线上压测数据,用以检测线上链路的性能以及可用性。针对压测链路上使用消息中间件的应用,通过拓展消息设计,在链路压测场景中,消息中间件可以提供如下功能。
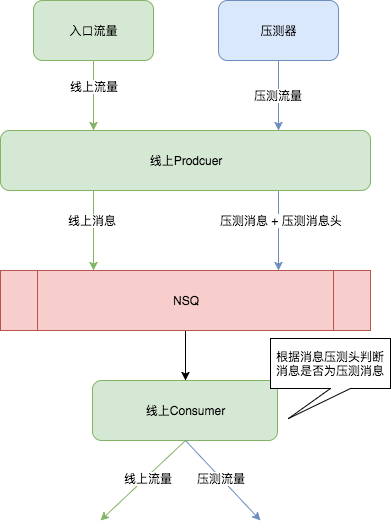 fig1. 消息使用场景之链路压测
fig1. 消息使用场景之链路压测
生产者应用在处理压测消息时,在拓展消息头中标记该消息为压测消息。NSQ将线上消息以及压测消息统一下发至下游消费者(线上Consumer),下游消费者通过检查拓展消息中的压测字段来判断该消息是否为压测流量,由应用框架根据拓展消息头内容决定是否下发至应用,或者对压测消息进行拦截。 该方案的优势在于,应用方无需对已有NSQ的Topic生产/消费配置进行变更,新版NSQ通过对已有topic进行升级,使topic支持拓展消息格式。业务方仅需要关注压测消息的处理。该方案的缺点在于,线上消息和压测消息共用一个topic,未进行隔离。一旦生产者对于压测消息的处理出现错误,或者下游消费应用超过负载时,此时隔离压测数据的操作较为复杂,需要业务方修改代码,新版NSQ通过回溯消费功能来“洗掉”压测消息。
拓展消息使用场景之链路隔离
拓展消息的另外一种场景为应用链路隔离。场景如下:QA环境总存在两类应用,第一类是QA环境中应用的稳定版本,另外一类是应用在QA上进行新功能开发/验证的版本。QA环境中应用通过NSQ进行解耦。新功能版本中增加了新的消息处理逻辑来消费稳定QA环境中不支持的消息,在NSQ不支持链路隔离前,开发需要:
- 停止QA稳定消费,启动新功能验证的消费;
- 在NSQ上验证新功能;
- 停止新功能验证消费,恢复稳定QA消费;
- 以上步骤往复,直至原有QA被替换;
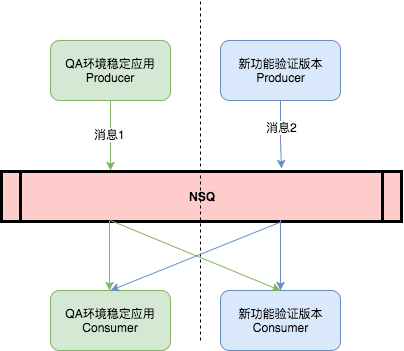 fig2. QA环境中应用使用NSQ场景
fig2. QA环境中应用使用NSQ场景
通过在NSQ服务端实现基于拓展消息头内容的投递优先级,新版NSQ支持业务上链路隔离的需求。
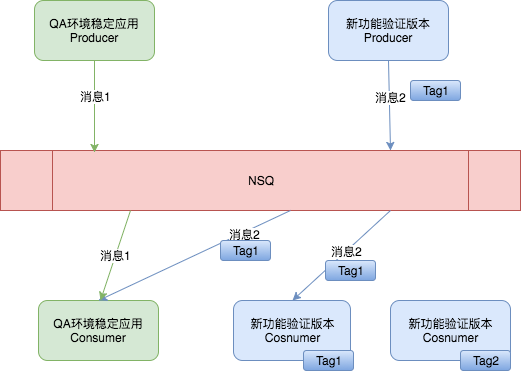 fig3. 新版NSQ支持链路隔离应用场景
fig3. 新版NSQ支持链路隔离应用场景
供新功能验证的消息将通过在拓展消息头上的附带信息进行标记,NSQ服务端在投递消息时根据消息头中的投递信息(Tag)按照以下规则进行路由:
- 消费者中不存在带有相同投递信息的消费者时,消息统一投递给QA稳定环境的消费者;
- 消费者中存在和消息头中相同的投递信息时,消息投递给该消费者;
- 消息投中不包含投递信息时,消息统一投递给QA稳定环境的消费者;
通过实现该规则,新版NSQ支持业务方实现环境链路隔离。
拓展消息使用场景之消息过滤
NSQ消息的消费模式为,消息在channel之间为组播,channel内的客户端(Consumer)竞争一条消息。
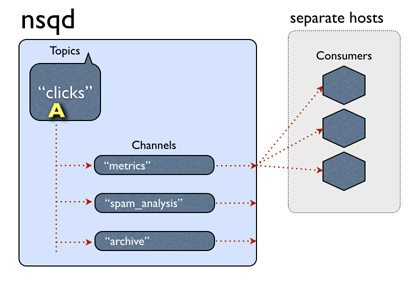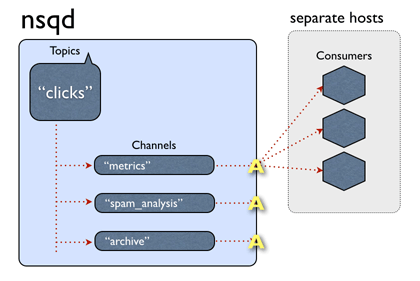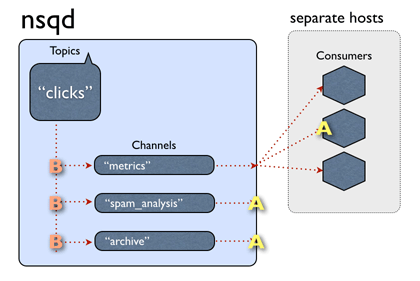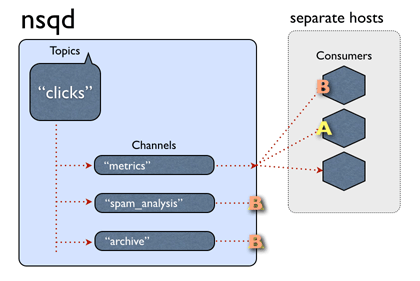 fig4.NSQ消息投递机制
fig4.NSQ消息投递机制
与链路隔离的思路类似,通过对消息拓展头的指定值进行过滤,新版NSQ可以支持channel内的消息过滤。
订阅到相同channel上的消费者附带相同的拓展消息关键字,当NSQ投递消息时:
- 消息内容没有标识信息或者标识信息空, 则只会投递没有filter_key或者filter_key为空的channel;
- 消息有过滤标识信息, 投递到匹配的filter_key的消费channel, 未指定filter的channel也要投递;
- 对于某个channel不匹配的消息, 服务端视为已消费,现象为该channel不投递;
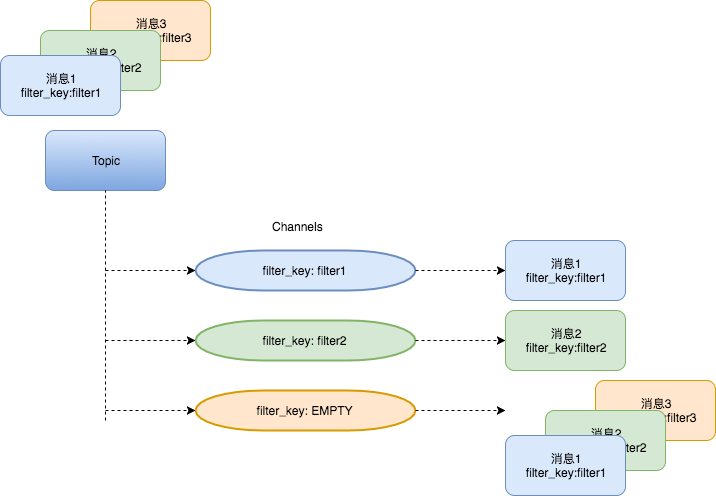 fig5. NSQ基于channel的消息过滤
fig5. NSQ基于channel的消息过滤
该功能的实现基于消息拓展头,可以在服务端,客户端单独实现,或由服务端和客户端共同实现。
NSQ migrate proxy-nsq迁移工具
对于正在使用开源版本NSQ的用户,NSQ migrate proxy提供将开源版本NSQ迁移到有赞自研版本NSQ的能力。借助于该迁移工具,可在用户无感知的情况下对topic进行迁移。NSQ migrate proxy在迁移过程中作为开源NSQ和自研NSQ的代理,根据迁移阶段的变化将lookup请求代理至开源NSQ和自研NSQ,整合nsqlookupd的结果后返回给客户端。使用迁移代理需要连接客户端实现读写策略,迁移代理需要根据读(r)写(w)参数对对生产者和消费者进行区分。
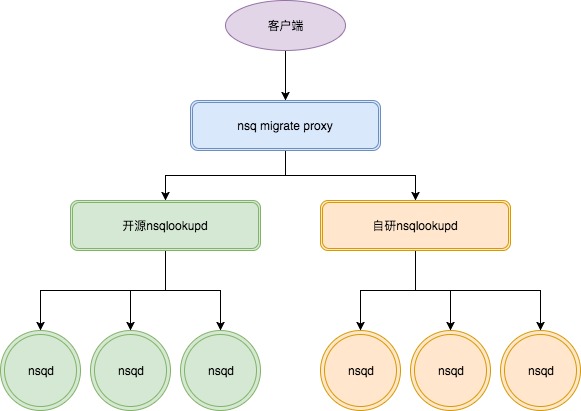 fig6. nsq迁移结构图
fig6. nsq迁移结构图
迁移步骤
结合自研版NSQ的读写策略(r/w),NSQ migrate proxy定义了3个迁移阶段,到达最后阶段后,topic的生产消费便迁移到自研版本
1.第1阶段中,代理将在返回给客户端的lookup结果中包含两个NSQ集群的节点信息。消费者将在两个集群间建立消费连接。生产继续向开源nsq进行生产。
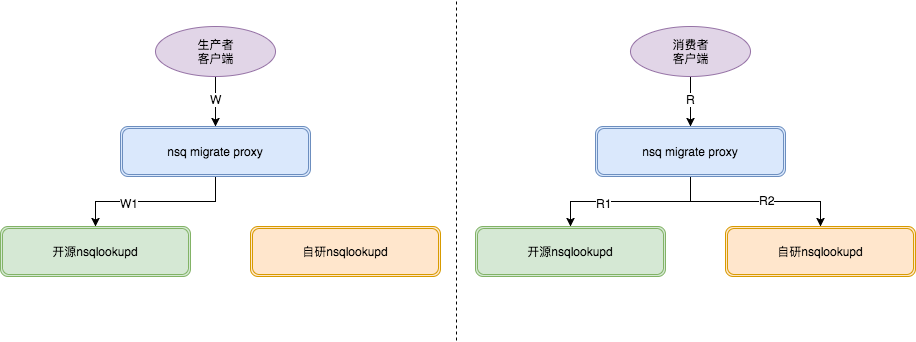 fig7.迁移阶段1
fig7.迁移阶段1
2.第2阶段中,代理对于生产者的lookup请求,只返回迁移目标集群的lookup结果。此时消息生产将指向目标NSQ集群。消费者继续维持双集群消费。
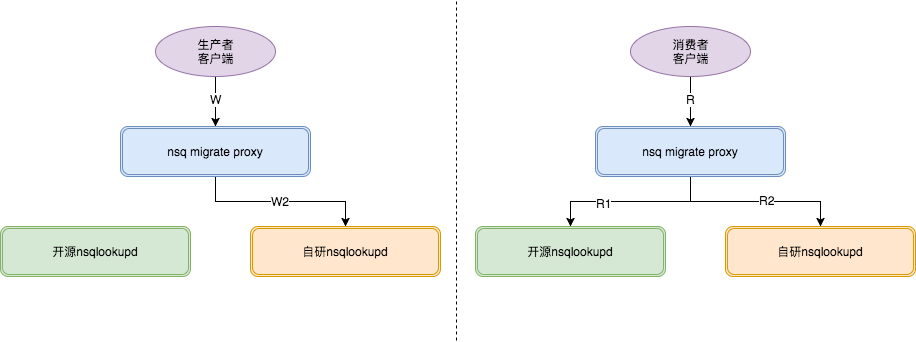 fig8.迁移阶段2
fig8.迁移阶段2
3.当确认开源NSQ集群中的消息已经消费完后,迁移进入最后阶段。代理对于消费者的lookup请求只返回目标NSQ节点信息。消费和开源NSQ的连接将断开。此时消息的生产和消费都迁移到自研NSQ集群。迁移完成。
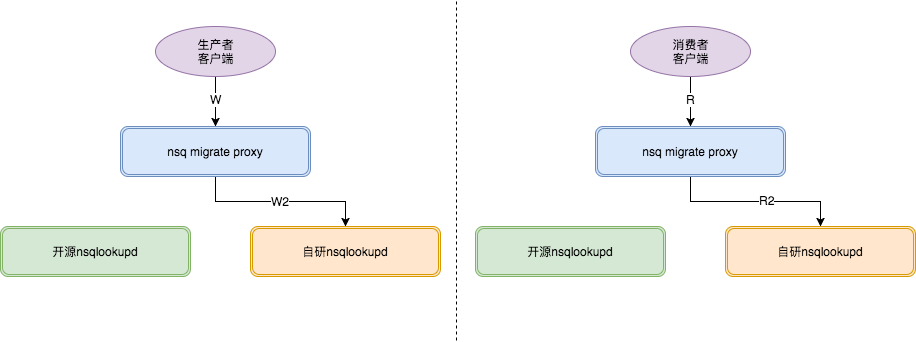 fig9.迁移阶段3
fig9.迁移阶段3
Connectors
除了围绕NSQ本身的的改造,我们针对spark和flume尝试了通过拓展与nsq进行集成。
spark connectors
spark consumer作为NSQ的消费者,从NSQ消费消息后通过spark streaming API进行处理。
flume connectors
flume nsq sink作为apache flume sink拓展,用于连接flume和NSQ,并通过本地文件序列化保存发送失败的event body并重试。通过插件的方式,用户在flume中的配置文件中指定NSQ作为flume的下游。
未来计划
为了支撑更多样的业务需求,有赞NSQ还在继续完善和丰富更多新特性, 这些特性包括NSQ本身的特性开发,也包括基于NSQ做的外部扩展系统的开发。未来的一段时间,我们计划增加如下值得期待的重要特性。
流控
目前有赞有大量的topic都部署在一个大的集群,受益于golang的goroutine模型,每个topic基本都是独立的处理,互相直接影响不大, 但是碰到一些数据量大的情况, 还是会对其他topic造成一定的影响,特别是一些网络流量非常大的 topic,为了降低这种topic流量影响,我们需要限制一些topic的流量上限, 对整个集群的稳定性提供保障。 设计方案上, 我们计划使用业界常用的令牌桶方案。
批量订阅
目前的NSQ还是沿用每条消息ack的模式, 保持兼容特性。 性能上虽然满足目前以及未来一段时间的业务需求,但是还有改进的空间。特别是在某些网络延迟较高的场景下,批量订阅可以大大提高吞吐量。批量订阅将会支持一次消费一组消息并且可以一次性ack一组消息,从而减少一定的网络开销。
更丰富安全审计功能
原版的NSQ已经支持一部分的安全审计功能, 包括使用安全链接以及使用验证服务器,我们后面将会针对topic的生产和channel的一些操作提供独立的安全验证服务,并做好审计日志,防范一些安全问题。另外针对nsqadmin也会打通内部的统一登录验证,针对性的限制业务的一些危险操作。
分布式事务协调器
微服务拆分的痛点就是多个系统之间的一致性保证问题,因此急需一个统一的框架能解决此类问题。分布式事务协调器将会是构建在NSQ基础之上的一个重要产品, 该产品将会充分利用NSQ的一些特性去解决业务的痛点。
基于消息内容的消费过滤
虽然目前已经有支持基于消息扩展头进行初步过滤的功能,但是也有些业务需求非常定制化,需要更加复杂的过滤规则,这种情况为了避免给NSQ核心代码带来影响,我们也计划在NSQ之上构建一个更加复杂的过滤系统去做和业务耦合的事情,避免给NSQ注入过多的业务耦合功能.
总结
本文中,先展示了有赞中间件在NSQ中引入的支持拓展的消息格式,并通过3个业务场景来展示新的消息格式的玩法。之后的部分介绍了围绕自研版本NSQ开发的拓展工具,包括了用于迁移的代理,以及可以将NSQ与spark和flume进行集成的拓展。最后对于未来计划进行了介绍,展望了部分计划中的新特性。
参考资料
- [1]NSQ spark consumer: https://github.com/youzan/spark-nsq-consumer
- [2]NSQ flume sink: https://github.com/DoraALin/flume-nsq-sink
